二、逻辑回归
1、代价函数

可以将上式综合起来为:
![]()
其中:
![]()
为什么不用线性回归的代价函数表示呢?因为线性回归的代价函数可能是非凸的,对于分类问题,使用梯度下降很难得到最小值,上面的代价函数是凸函数![]() 的图像如下,即y=1时:
的图像如下,即y=1时:
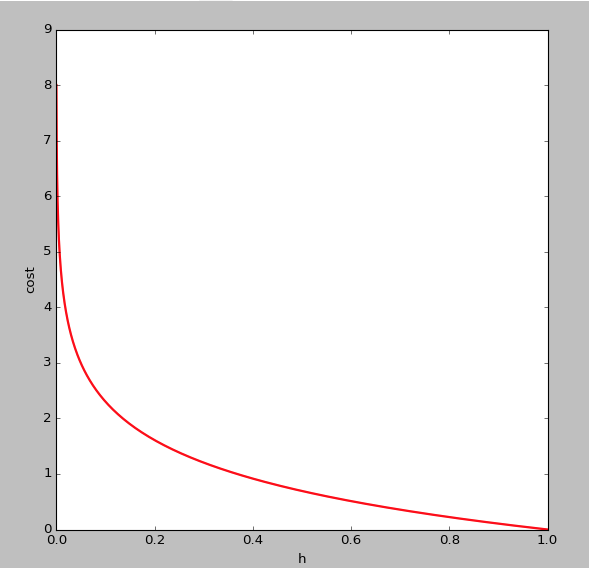
可以看出,当![]() 趋于1,y=1,与预测值一致,此时付出的代价cost趋于0,若
趋于1,y=1,与预测值一致,此时付出的代价cost趋于0,若![]() 趋于0,y=1,此时的代价cost值非常大,我们最终的目的是最小化代价值,同理
趋于0,y=1,此时的代价cost值非常大,我们最终的目的是最小化代价值,同理![]() 的图像如下(y=0):
的图像如下(y=0):

2、梯度
同样对代价函数求偏导:
![]()
可以看出与线性回归的偏导数一致。
推导过程:
3、正则化
正则化的目的为了防止过拟合。在代价函数中加上一项
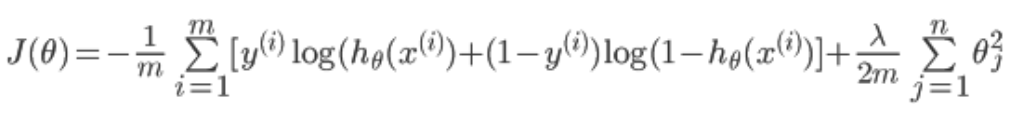
注意j是从1开始的,因为theta(0)为一个常数项,X中最前面一列会加上一列1,所以乘积还是theta(0),与feature没有关系,没有必要正则化。
正则化后的代价:
1 # 代价函数 2 def costFunction(initial_theta,X,y,inital_lambda): 3 m = len(y) 4 J = 0 5 6 h = sigmoid(np.dot(X,initial_theta)) # 计算h(z) 7 theta1 = initial_theta.copy() # 因为正则化j=1从1开始,不包含0,所以复制一份,前theta(0)值为0 8 theta1[0] = 0 9 10 temp = np.dot(np.transpose(theta1),theta1) 11 J = (-np.dot(np.transpose(y),np.log(h))-np.dot(np.transpose(1-y),np.log(1-h))+temp*inital_lambda/2)/m # 正则化的代价方程 12 return J
正则化后的代价的梯度
1 # 计算梯度 2 def gradient(initial_theta,X,y,inital_lambda): 3 m = len(y) 4 grad = np.zeros((initial_theta.shape[0])) 5 6 h = sigmoid(np.dot(X,initial_theta))# 计算h(z) 7 theta1 = initial_theta.copy() 8 theta1[0] = 0 9 10 grad = np.dot(np.transpose(X),h-y)/m+inital_lambda/m*theta1 #正则化的梯度 11 return grad
4、S型函数(即![]() )
)
代码实现
1 # S型函数 2 def sigmoid(z): 3 h = np.zeros((len(z),1)) # 初始化,与z的长度一置 4 5 h = 1.0/(1.0+np.exp(-z)) 6 return h
5、映射为多项式
因为数据的feature可能很少,导致偏差大,所以创造出一些组合feature
eg:映射为2次方的形式为:![]()
代码实现:
1 # 映射为多项式 2 def mapFeature(X1,X2): 3 degree = 3; # 映射的最高次方 4 out = np.ones((X1.shape[0],1)) # 映射后的结果数组(取代X) 5 ''' 6 这里以degree=2为例,映射为1,x1,x2,x1^2,x1,x2,x2^2 7 ''' 8 for i in np.arange(1,degree+1): 9 for j in range(i+1): 10 temp = X1**(i-j)*(X2**j) #矩阵直接乘相当于matlab中的点乘.* 11 out = np.hstack((out, temp.reshape(-1,1))) 12 return out
6、使用scipy的优化方法
梯度下降使用scipy中optimize中的fmin_bfgs函数
调用scipy中的优化算法fmin_bfgs(拟牛顿法Broyden-Fletcher-Goldfarb-Shanno costFunction是自己实现的一个求代价的函数),
initial_theta表示初始化的值,
fprime指定costFunction的梯度
args是其余参数,以元组的形式传入,最后会将最小化costFunction的theta返回
result = optimize.fmin_bfgs(costFunction, initial_theta, fprime=gradient, args=(X,y,initial_lambda))
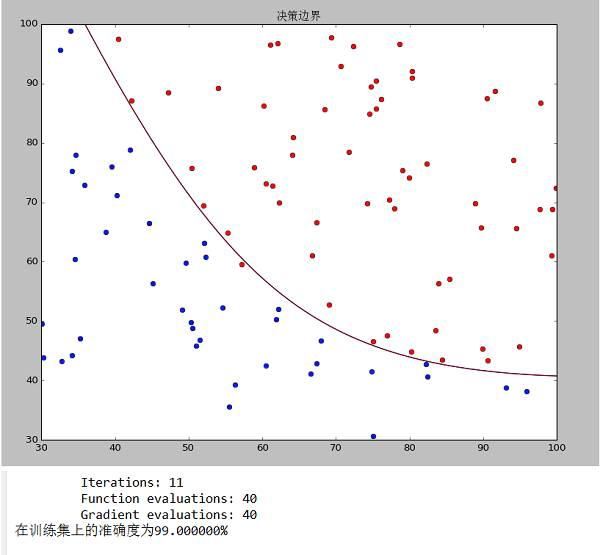
7、运行结果
data1决策边界和准确度
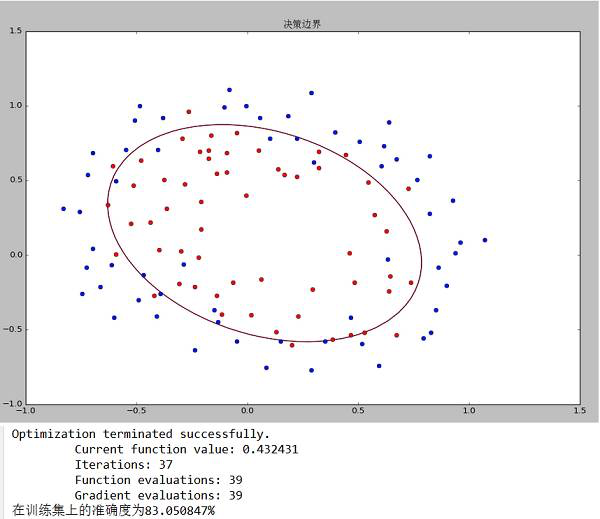
data2决策边界和准确度
8、使用scikit-learn库中的逻辑回归模型实现
1 from sklearn.linear_model import LogisticRegression 2 from sklearn.preprocessing import StandardScaler 3 from sklearn.cross_validation import train_test_split 4 import numpy as np 5 6 def logisticRegression(): 7 data = loadtxtAndcsv_data("data1.txt", ",", np.float64) 8 X = data[:,0:-1] 9 y = data[:,-1] 10 11 # 划分为训练集和测试集 12 x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.2) 13 14 # 归一化 15 scaler = StandardScaler() 16 scaler.fit(x_train) 17 x_train = scaler.fit_transform(x_train) 18 x_test = scaler.fit_transform(x_test) 19 20 #逻辑回归 21 model = LogisticRegression() 22 model.fit(x_train,y_train) 23 24 # 预测 25 predict = model.predict(x_test) 26 right = sum(predict == y_test) 27 28 predict = np.hstack((predict.reshape(-1,1),y_test.reshape(-1,1))) # 将预测值和真实值放在一块,好观察 29 print predict 30 print ('测试集准确率:%f%%'%(right*100.0/predict.shape[0])) #计算在测试集上的准确度 31 32 # 加载txt和csv文件 33 def loadtxtAndcsv_data(fileName,split,dataType): 34 return np.loadtxt(fileName,delimiter=split,dtype=dataType) 35 36 # 加载npy文件 37 def loadnpy_data(fileName): 38 return np.load(fileName) 39 40 if __name__ == "__main__": 41 logisticRegression()
逻辑回归_手写数字识别_OneVsAll
1、随机显示100个数字
我们没有使用scikit-learn中的数据集,像素是20*20px,彩色图如下:

灰度图为:

代码实现:
1 # 显示100个数字 2 def display_data(imgData): 3 sum = 0 4 ''' 5 显示100个数(若是一个一个绘制将会非常慢,可以将要画的数字整理好,放到一个矩阵中,显示这个矩阵即可) 6 - 初始化一个二维数组 7 - 将每行的数据调整成图像的矩阵,放进二维数组 8 - 显示即可 9 ''' 10 pad = 1 11 display_array = -np.ones((pad+10*(20+pad),pad+10*(20+pad))) 12 for i in range(10): 13 for j in range(10): 14 display_array[pad+i*(20+pad):pad+i*(20+pad)+20,pad+j*(20+pad):pad+j*(20+pad)+20] = (imgData[sum,:].reshape(20,20,order="F")) # order=F指定以列优先,在matlab中是这样的,python中需要指定,默认以行 15 sum += 1 16 17 plt.imshow(display_array,cmap='gray') #显示灰度图像 18 plt.axis('off') 19 plt.show()
2、OneVsAll
如何利用逻辑回归解决多分类的问题,OneVsAll就是把当前某一类看成一类,其他所有类别看作一类,这样就成了二分类问题。如下图,把途中的数据分成三类,先把红色的看成一类,把其他的看作另一类,进行逻辑回归,然后把蓝色的看成一类,其他的看成另一类,以此类推。。。
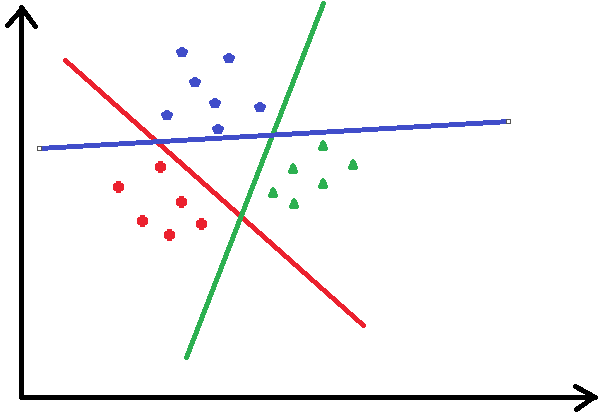
可以看出大于2类的情况下,有多少类就要进行多少次的逻辑回归分类
3、手写数字识别
共有0-9,10个数字,需要10次分类
由于数据集y给出的是0,1,2,。。。9的数字,而进行逻辑回归需要0/1的label标记,所以需要对y处理。
说一下数据集,前500个是0,500-1000是1,...,所以如下图,处理后的y,前500行的第一列是1,其余都是0,500-1000行第二列是1,其余都是0。。。
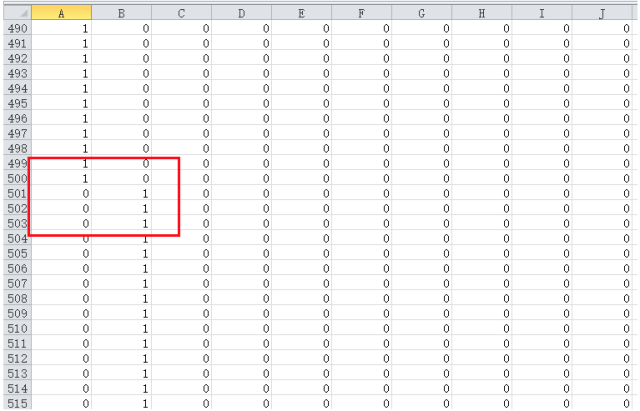
然后调用梯度下降算法求解theta
代码实现:
1 # 求每个分类的theta,最后返回所有的all_theta 2 def oneVsAll(X,y,num_labels,Lambda): 3 # 初始化变量 4 m,n = X.shape 5 all_theta = np.zeros((n+1,num_labels)) # 每一列对应相应分类的theta,共10列 6 X = np.hstack((np.ones((m,1)),X)) # X前补上一列1的偏置bias 7 class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系 8 initial_theta = np.zeros((n+1,1)) # 初始化一个分类的theta 9 10 # 映射y 11 for i in range(num_labels): 12 class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值 13 14 #np.savetxt("class_y.csv", class_y[0:600,:], delimiter=',') 15 16 '''遍历每个分类,计算对应的theta值''' 17 for i in range(num_labels): 18 result = optimize.fmin_bfgs(costFunction, initial_theta, fprime=gradient, args=(X,class_y[:,i],Lambda)) # 调用梯度下降的优化方法 19 all_theta[:,i] = result.reshape(1,-1) # 放入all_theta中 20 21 all_theta = np.transpose(all_theta) 22 return all_theta
4、预测
之前说过,预测的结果是一个概率值,利用学习出来的theta代入预测的S型函数中,每行的最大值就是某个数字的最大概率,所在的列号就是预测的数字的真实值,因为在分类时,所有为0的将y映射在第一列,为1的映射在第二列,以此类推
代码实现:
1 # 预测 2 def predict_oneVsAll(all_theta,X): 3 m = X.shape[0] 4 num_labels = all_theta.shape[0] 5 p = np.zeros((m,1)) 6 X = np.hstack((np.ones((m,1)),X)) #在X最前面加一列1 7 8 h = sigmoid(np.dot(X,np.transpose(all_theta))) #预测 9 10 ''' 11 返回h中每一行最大值所在的列号 12 - np.max(h, axis=1)返回h中每一行的最大值(是某个数字的最大概率) 13 - 最后where找到的最大概率所在的列号(列号即是对应的数字) 14 ''' 15 p = np.array(np.where(h[0,:] == np.max(h, axis=1)[0])) 16 for i in np.arange(1, m): 17 t = np.array(np.where(h[i,:] == np.max(h, axis=1)[i])) 18 p = np.vstack((p,t)) 19 return p
5、运行结果
10次分类,在训练集上的准确度:

6、使用scikit-learn库中的逻辑回归模型实现
1 #-*- coding: utf-8 -*- 2 from scipy import io as spio 3 import numpy as np 4 from sklearn import svm 5 from sklearn.linear_model import LogisticRegression 6 7 8 9 def logisticRegression_oneVsAll(): 10 data = loadmat_data("data_digits.mat") 11 X = data['X'] # 获取X数据,每一行对应一个数字20x20px 12 y = data['y'] # 这里读取mat文件y的shape=(5000, 1) 13 y = np.ravel(y) # 调用sklearn需要转化成一维的(5000,) 14 15 model = LogisticRegression() 16 model.fit(X, y) # 拟合 17 18 predict = model.predict(X) #预测 19 20 print u"预测准确度为:%f%%"%np.mean(np.float64(predict == y)*100) 21 22 # 加载mat文件 23 def loadmat_data(fileName): 24 return spio.loadmat(fileName) 25 26 if __name__ == "__main__": 27 logisticRegression_oneVsAll()