一套完整的数据分析流程 , 如下图所示
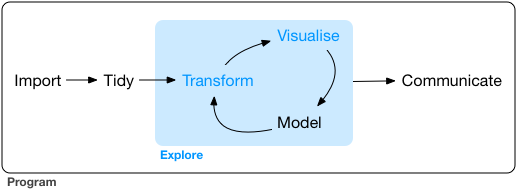
从图中可以看到,整个流程包括读取数据,整洁数据,数据探索和交流部分。经过前两部分, 我们可以得到一个整理好的数据,它的每一行都是一个样本 , 每一列是一个变量。
然后我们就可以进入最核心的数据探索部分。数据探索包括数据转换,可视化,建模三部分。数据转换的内容包括构建新的变量,选出子集,对数据进行分组并获取统计量 。进而可以通过可视化把变量或变量之间关系用图形表示出来;在对数据有大体上的认知后,可以尝试用精确的数学语言来对数据进行建模 。模型的结果会给我们一些新的洞察和知识,驱动我们去提出新的问题,构成一个反馈循环。
数据探索完成后我们要把所做的工作借助文章清晰地表达出来,从而与其他人沟通
分析汽车排放数据集
首先载入 tidyverse 包 , 并观察 mpg 数据的头部:
library(tidyverse)
mpg
可视化:ggplot
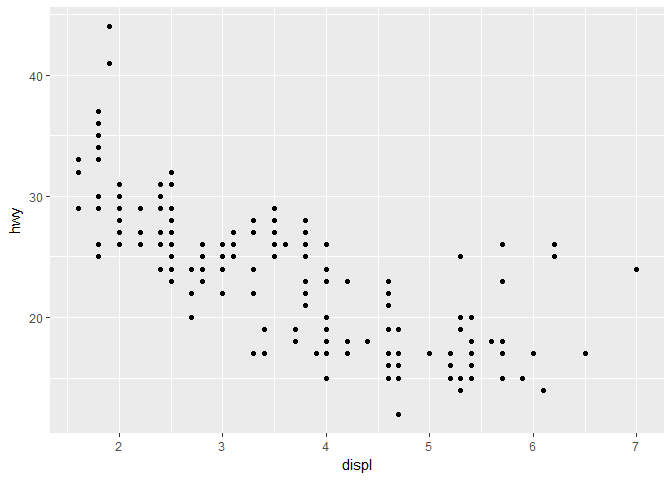
先提出一个问题 , 汽车排放量和高速路上的每公里耗油量有什么关系? 这两个变量都是数值变量,可以先用散点图的形式将它们的关系展示出来:
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy))
绘图的核心要素:
数据 : ggplot 的数据集必须是一个数据框,这里我们的数据是 mpg
图形属性映射:将数据变量映射到图形中,我们这里使用 aes(x = displ, y = hwy) 把 x 坐标映射到排气量,y 坐标映射到每公里耗油量
几何对象 : geom 代表几何对象,比如我们这里想画散点图,就用 geom_point 来生成散点图
从这张图我们可以发现排气量与耗油成反向关系,排气量越大,耗油越少,它们的关系大致是线性的,但也有一些例外,比如左上和右上的一些点 。很容易想到,耗油量不仅与排气量有关,还与车的类型有关,我们可以尝试把车型的信息加入到图中:
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class))
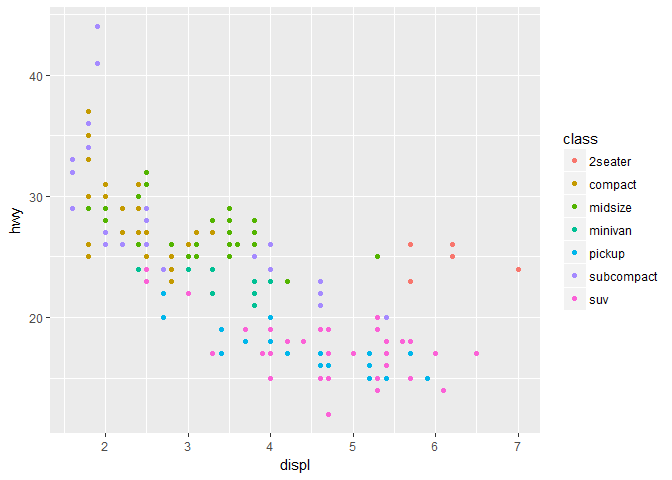
可以看到排气量较大但耗油量也大的大多属于 2seater (2 个座位的跑车)这一类型,类型与耗油确实有很大关系
为了进一步地分析类型与耗油的关系,我们会想到把不同的类型的车的数据分离开来,而不是画在一张图上,我们可以使用 facet_wrap 把他们分离开来:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class)
从原来的图上我们可以看到一种强烈的线性关系,能不能拟合一条曲线并把它画到图上呢?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy))
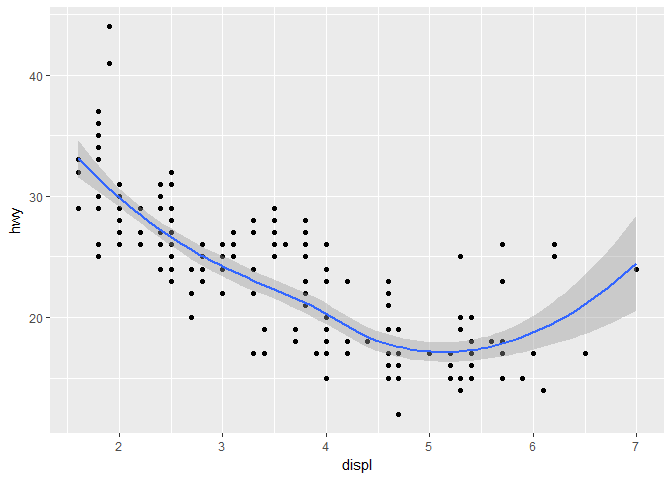
上面拟合所用的方法是 loess,翻译成中文就是近邻多项式回归,是一种非参数方法,所以由于几种跑车的存在,曲线右边翘了起来
曲线的阴影部分是置信区间的上下界
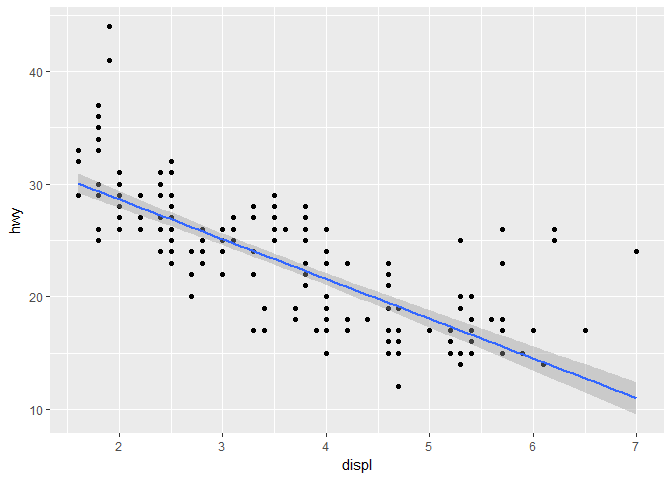
如果我们想拟合普通的线性回归,我们可以改变 method 参数:
ggplot(mpg , aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(method = "lm")
数据转换:dplyr
filter 是一个用于筛选行的函数,例如我们想筛出排量大于等于 5,高速路每公里耗油小于 20 的车:
mpg %>% filter(displ >=5 , hwy < 20)
得到了这些排量较大,耗油较小的车,我们想按照生产日期降序排列 , 耗油量升序排列
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy)
这 11 个变量太多 , 我们只关心车型 , 那么可以通过 select 函数把这一个变量单独提出来
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy) %>% select(model)
我们回到原来的 mpg 数据集,按照常识,排气管越多,排量越大,我们想生成一个新变量来看一看每根排气管的平均排气量是不是很接近
mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ)
var(mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ))
可以发现我们的猜想大致正确,大多数车的平均排气量都在 0.5 到 0.7 之间 , 计算出来的方差也非常小
有的时候我们不想看单个样本,而是想按照某个标准把数据分成几组,再来分别看这些组的统计特征有什么差异,那么我们可以先用 group_by 按照条件分组,再用 summarise 算出每组组内的统计特征。例如我们想看不同车型的平均排气量和平均耗油量
mpg %>% group_by(class) %>% summarise(mean(displ) , mean(hwy))