Zookeeper是什么

Zookeeper是一个高性能分布式应用协调服务,主要有以下功能:
- Naming Service
- 配置管理
- Leader Election
- 服务发现
- 同步
- Group Service
- Barrier
- 分布式队列
- 两阶段提交
Zookeeper工作方式

- Zookeepe集群包含 1 个Leader,多个Follower
- 所有的Follower都可提供读服务
- 所有的写搡作都会被forward到Leader
- Client 与 Server通过NIO通信。
- 全局串行化所有的写操作
- 保证同一客户端的指令被FIFO执行
- 保证消息通知的FIFO
Zab协议
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)
1 广播模式

-
Leader将所有更新(称为proposal),顺序发送给Follower
每个Zookeeper都有一个内存数据库(缓存),当client请求server时读取数据时就是读取的内存数据库,不用每次读磁盘。
- 当Zookeeper收到proposal时,会将proposal持久化到磁盘
- 当Leader commit proposal后就会将proposal写到内存数据库
-
当Leader收到半数以上的Follower对此proposal的ACK时,即向所有Follower发送commit消息,并在本地commit该消息
-
Follower收到Proposal后即将该proposal写入磁盘,写入成功即返回ACK给Leader
-
每个Proposal都有一个唯一的单调递增的proposal ID ,即zxid1
2 恢复模式
- 进入恢复模式
当Leader宕机或者丢失大多数Follower后, 即进入恢复模式
- 结束恢复模式
新领导被选举出来, 且大多数Follower完成了与Leader的状态同步后,恢复模式即结束,从而进入广播模式
- 恢复模式的意义
- 发现集群中被commit的proposal的最大zxid(恢复时,新的Leader需要知道最大的zxid)
- 建立新的epoch, 从而保证之前的Leader不能再commit新的Proposal(旧Leader活过来后尝试发送数据就发不出去了,因为已经有了新的epoch)
- 集群中大部分节点都commit过前一个Leader commit过的消息, 而新的Leader是被大多数节点所支持的,所以被之前Leader commit过的Proposal不会丢失, 至少被一个节点所保存
- 新Leader会与所有Follower通信, 从而保证大部分节点都拥有最新的数据
- 恢复阶段的保证
- 确保已经被 Leader 提交的 Proposal 必须最终被所有的 Follower 服务器提交。
如下图:server1向server2、server3发送p1、p2并且收到server2、server3的ack,然后server1进行commit后还没来得及向server2、server3发出commit消息之前挂了,server2、server3必须将p1、p2提交。

- 确保丢弃已经被 Leader 提出的但是没有被提交的 Proposal。
- 确保已经被 Leader 提交的 Proposal 必须最终被所有的 Follower 服务器提交。
Zookeeper一致性保证
- 顺序 一致性
从一个客户端发出的更新操作会按发送顺序被顺序执行 - 原子性
更新操作要么成功要么失败,无中间状态 - 单一系统镜像
一个客户端只会看到同一个view ,无论它连到哪台服务器 - 可靠性
- 一旦一个更新被应用,该更新将被持久化,直到有客户端更新该结果
- 如果一个客户端得到更新成功的状态码,则该更新一定已经生效
- 任何一个被客户端通过读或者更新"看到"的结果,将不会被回滚,即使是从失败中恢复
- 实时性
保证客户端可在一定时间(通常是几十秒)内看到最新的视图
Zookeeper使用注意事项
- 只保证同一客户端的单一系统镜像,并不保证多个不同客户端在同一时刻一定看到同一系统镜像,如果要实现这种效果,需要在读取数据之前调用Zookeeper的sync操作。
如下图,client1修改a的值为1,由于Zookeeper半数以上的节点确认后就提交事务,client2可能就会读取到未确认的节点的值0,如果client2想要读取最新数据就需要在读取之前调用Zookeeper的sysc操作。

- Zooke印eri卖性能好于写性能,因为任何Serve均可提供读服务,而只有Leader可提供写服务,因此更适合读多写少的场景
- 为了保证Zookeeper本身的Leader Election顺利进行,通常将Server®置为奇数
- 若需容忍 f个Server的失败,必须保证有2f+l个以上的Server
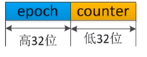
Zxid的是64位,高位是epoch,低位是counter,leader之间的epoch都不相同,但是每个leader的epoch相同。leader1的epoch位2(所以新leader发出的proposal比老的leader发出的proposal大),leader2的epoch为2。counter计数这是这个leader期间的第几次更新。 ↩︎