上一篇文章写过centos 7下clickhouse rpm包安装和基本的目录结构,这里主要介绍clickhouse高可用集群的部署方案,因为对于默认的分布式表的配置,每个分片只有一份,这样如果挂掉一个节点,则查询分布式表的时候直接会报错,这个是基于clickhouse自己实现的多分片单副本集群,配置也比较简单,这里说的高可用是指,每个分片具有2个或以上副本,当某个节点挂掉时,该节点分片仍可以由其他机器上的副本替代工作,所以这样实现的分布式集群可以在挂掉至少1个节点时机器正常运行,随着集群节点数量的增加,则集群挂掉2个节点或以上可提供服务的概率也越大,至少能避免单点故障问题,集群的稳定性也更高.
clickhouse集群的理想方案是如下所示:
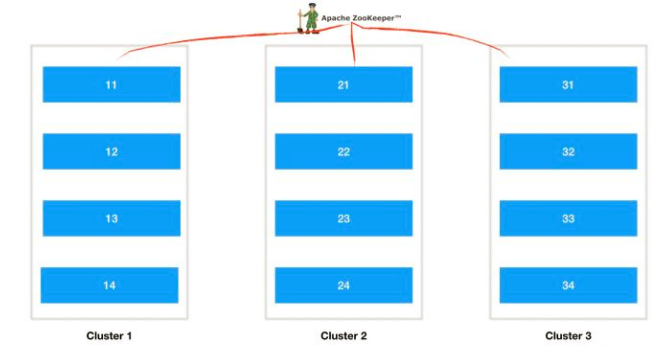
这里有3个集群,每个集群n个节点,每个节点的数据依靠zookeeper协调同步,比如cluster1提供服务,如果cluster1里面挂掉多台机器那么cluster2的副本可以切换过来提供服务,如果cluster2的分片再挂了,那么cluster3中的副本也可以提供服务,cluster1~3同时挂掉的概率就非常小了,所以集群的稳定性可以非常高,其中单个集群的节点个数n决定了clickhouse的性能,性能是可以线性扩展的,具体副本集群的个数根据机器资源配置.
如果机器资源确实特别少,想每个节点都用上提供服务的话,那么可以每个节点存储两个以上的副本,即提供服务的分片和其他机器的副本,实现相互备份,但是clickhouse不支持单个节点多个分片的配置,我们可以人为设置在每个节点上启动两个实例来实现,设计图如下:

图画的非常简陋,但是可以看出来3个节点每个节点的tcp 9000对外提供服务,9001提供副本,其中2提供1的备份,3提供2的备份,1提供3的备份,这样假设挂掉1个节点,集群也可以正常使用,但是挂掉2个几点,就不正常了,这样的话是机器越多越稳定一些.
上面两种方案,官网上还是推荐的第一种方案可用性最高,这里为了演示采用第二种方式配置,其实两种方式的配置是完全一样的,第二种配置反而更繁琐一些,下面详细说一下配置的流程,软件包结构就采用上一篇文章打包好的.
0. 高可用原理:zookeeper + ReplicatedMergeTree(复制表) + Distributed(分布式表)
1. 前提准备:所有节点防火墙关闭或者开放端口;hosts表和主机名一定要集群保持一致正确配置,因为zookeeper返回的是主机名,配置错误或不配置复制表时会失败.
clickhouse测试节点2个:192.168.0.107 clickhouse1, 192.168.0.108 clickhouse2
zookeeper测试节点1个:192.168.0.103 bigdata
配置方案:两个节点各配置两个clickhouse实例,相互备份.
clickhouse1: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片1, 副本1
clickhouse1: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片2, 副本2 (clickhouse2的副本)
clickhouse2: 实例1, 端口: tcp 9000, http 8123, 同步端口9009, 类型: 分片2, 副本1
clickhouse2: 实例2, 端口: tcp 9001, http 8124, 同步端口9010, 类型: 分片1, 副本2 (clickhouse1的副本)
2. 修改启动脚本和配置文件
首先将启动脚本复制一个出来,除了上一篇文章说的外,主要修改配置文件位置和pid文件位置,如下:
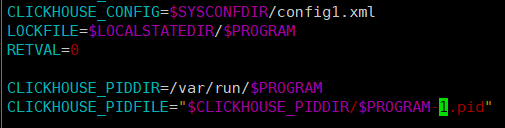
这里配置文件比如使用config1.xml,pid使用clickhouse-server-1.pid
然后进入到配置文件目录,将原有配置文件拷贝一份,这里是config1.xml,然后修改配置:
主要修改内容是:日志文件(和之前不要冲突)、http端口、tcp端口、副本同步端口(这个改完之后clickhouse按照当前实例的端口自动和其他实例同步)、数据文件和tmp目录、users.xml(这个如果都一样可以用同一个)、最后就是集群配置了,下面重点叙述:
集群配置默认为:<remote_servers incl="clickhouse_remote_servers" />
zookeeper默认为:<zookeeper incl="zookeeper-servers" optional="true" />
macros默认为:<macros incl="macros" optional="true" />
首先是集群分片的配置,这个配置所有节点的所有实例完全保持一致:
<remote_servers>
<distable>
<shard>
<!-- Optional. Shard weight when writing data. Default: 1. -->
<weight>1</weight>
<!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas). -->
<internal_replication>true</internal_replication>
<replica>
<host>192.168.0.107</host>
<port>9000</port>
</replica>
<replica>
<host>192.168.0.108</host>
<port>9001</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.0.108</host>
<port>9000</port>
</replica>
<replica>
<host>192.168.0.107</host>
<port>9001</port>
</replica>
</shard>
</distable>
</remote_servers>
配置里面的<distable>是分布式标识标签,可以自定义,到最后创建分布式表的时候会用到;然后weight是分片权重,即写数据时有多大的概率落到此分片,因为这里所有分片权重相同所有都设置为1,然后是internal_replication,表示是否只将数据写入其中一个副本,默认为false,表示写入所有副本,在复制表的情况下可能会导致重复和不一致,所以这里一定要改为true,clickhouse分布式表只管写入一个副本,其余同步表的事情交给复制表和zookeeper来进行,然后是replica配置这个好理解,就是一个分片下的所有副本,这里副本的分布一定要手动设计好,保证相互备份,然后再次说明是所有的节点配置一致. 此部分配置严格按照官网配置,参考链接:https://clickhouse.yandex/docs/en/operations/table_engines/distributed/
然后是zookeeper配置,这个也是所有示例配置都一样:
<zookeeper>
<node index="1">
<host>192.168.0.103</host>
<port>2181</port>
</node>
</zookeeper>
这里zookeeper只有一个,如果多个的话继续往下写,就像官网上给出的一样,参考下图:

然后是复制标识的配置,也称为宏配置,这里唯一标识一个副本名称,每个实例都要配置并且都是唯一的,这里配置如下:
clickhouse1 9000 分片1, 副本1:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>
clickhouse1 9001 分片2, 副本2:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>
clickhouse2 9000 分片2, 副本1:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-1</replica>
</macros>
clickhouse2 9001 分片1, 副本2:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-2</replica>
</macros>
由上面配置可以看到replica的分布规律,其中layer是双级分片设置,在Yandex公司的集群中用到,因为我们这里是单集群所以这个值对我们没有影响全部一样即可,这里是01;然后是shard表示分片编号;最后是replica是副本标识,这里使用了cluster{layer}-{shard}-{replica}的表示方式,比如cluster01-02-1表示cluster01集群的02分片下的1号副本,这样既非常直观的表示又唯一确定副本. 副本的文档链接下面会给出.
3. 创建本地复制表和分布式表
所有实例配置完上面这些之后,分别执行启动命令启动,然后所有实例都执行下面语句创建数据库:
CREATE DATABASE monchickey;
然后对于所有实例分别创建对应的复制表,这里测试创建一个简单的表
clickhouse1 9000 实例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-01/image_label','cluster01-01-1',insert_time, (label_id, insert_time), 8192)
clickhouse1 9001 实例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-02/image_label','cluster01-02-2',insert_time, (label_id, insert_time), 8192)
clickhouse2 9000 实例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-02/image_label','cluster01-02-1',insert_time, (label_id, insert_time), 8192)
clickhouse2 9001 实例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-01/image_label','cluster01-01-2',insert_time, (label_id, insert_time), 8192)
到这里复制表就创建完毕了,注意引号部分只能用单引号,其中核心的地方是同一个分片在zookeeper上面的znode相同,下面包含数据表的多个副本,当一个副本写入数据时会自动触发同步操作. 上面建表语句和配置文件对应着看应该容易理解,更详细的说明参考文档:https://clickhouse.yandex/docs/en/operations/table_engines/replication/ 文档关于ReplicatedMergeTree叙述如下:
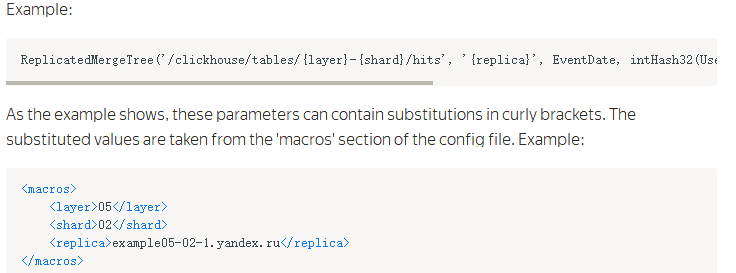
然后创建完上面复制表之后,可以创建分布式表,分布式表只是作为一个查询引擎,本身不存储任何数据,查询时将sql发送到所有集群分片,然后进行进行处理和聚合后将结果返回给客户端,因此clickhouse限制聚合结果大小不能大于分布式表节点的内存,当然这个一般条件下都不会超过;分布式表可以所有实例都创建,也可以只在一部分实例创建,这个和业务代码中查询的示例一致,建议设置多个,当某个节点挂掉时可以查询其他节点上的表,分布式表的建表语句如下:
CREATE TABLE image_label_all AS image_label ENGINE = Distributed(distable, monchickey, image_label, rand())
分布式表一般用本地表加all来表示,这里distable就是上面xml配置中的标签名称,最后的rand()表示向分布式表插入数据时,将随机插入到副本,在生产环境建议插入的时候客户端可以随机分桶插入到本地表,查询的时候走分布式表,即分布式表只读,本地复制表只写.
配置好上面这些可以尝试通过不同clickhouse实例写入数据测试,然后查询可以发现分片都会单独同步,不同分片间数据互不影响,通过分布式表查询可以查询到所有的数据;如果停掉clickhouse2这个节点,此时clickhouse会自动切换为可用的副本使用,无需人工干预,现在查询分布式表仍然可用,当clickhouse2上面的实例启动恢复的时候,clickhouse会自动切换回来并且做数据的同步,这样就实现了高可用性.
上面就是clickhouse高可用集群的基本配置,确实如一些文章所说像一辆手动挡的车,用的越熟练越好用,另外关于性能和深入的配置随着以后使用会继续分享,最后本人表达能力不是太好,如果文中有错误或叙述的不当,希望路过的大牛们指出,非常感谢^_^