前言
在想很好了解 Stream 之前,很有必要简单的了解下函数式变成以及Lambda的概念,可以阅读另外一篇
大家回忆下日常学习工作中使用的最多的 Java API 是什么?相信很多人的答案和我一样都是集合。我们选择适合的集合数据结构存储数据,而我们之于集合最多的操作就是遍历,实现查询,统计,过滤,合并等业务。
哪里用Stream
集合迭代
外部迭代:通过 for循环,Iterator迭代器遍历集合,手动的拿到集合中每个元素进行相应处理
- 优点
- 对于程序的掌控更高
- 性能强(如果算法功力深厚)
- 缺点
- 很多重复的模板代码
- 需要很多中间临时变量来减少遍历次数
- 性能完全取决于程序员水平,烧脑
- 代码不易读
- 容易出错:例如for循环遍历LinkedList会出错
内部迭代:只提供对集合中元素的处理逻辑,遍历过程交给库类,Java5提供了foreach,Java8提供了Stream
- 优点
- 代码好读
- 简单,只需要提供处理逻辑
- 缺点
- 有些情况性能比外部迭代差一点点
- 在使用foreach时不能对元素进行赋值操作
为什么要Stream
本文要介绍的Stream属于内部迭代,之前我们已经有了foreach减少了我们的代码量,为什么我们还需要Stream呢?
- 流水线的方式处理集合,结合Lambda爽歪歪
- 代码超短超好读
- Stream的开始到结束就相当于一次遍历,允许我们在遍历中拼接多个操作
- 强调的是对集合的计算逻辑,逻辑可以多次复用
- 特别繁重的任务可以很轻松的转为并行流,适合类似于大数据处理等业务
- 成本非常小的实现并行执行效果
怎么用Stream
上文我们大概知道了Stream主要服务与集合,流的过程可以总结为三步:
- 开始操作:读取数据源(如集合)
- 中间操作:组装中间操作链,形成一条流的流水线
- 终端操作:一次迭代执行流水线,结束流,并生成结果
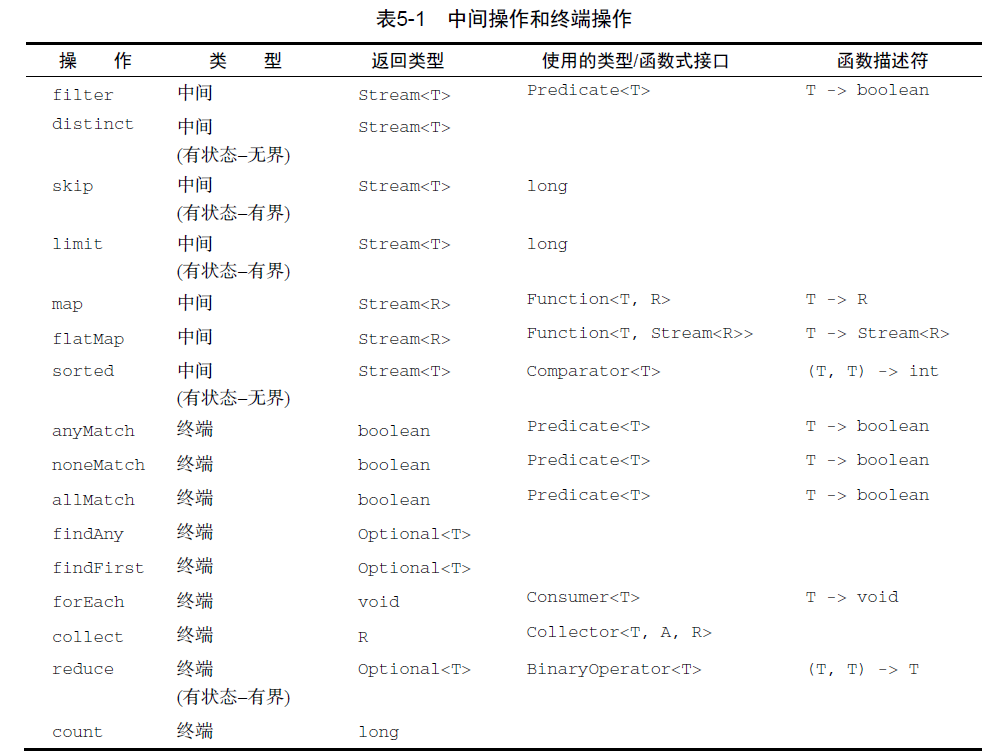
中间操作和终端操作
第一步流加载集合数据,库类完成我们不需要关心,要想使用好Stream有必要从不同维度了解主要的操作
- 中间操作:流水线的部件,返回的是this,也就是Stream,此时迭代并没有执行
- 终端操作:流水线真正开始执行,返回的是处理结果,终端操作过后流关闭
- 无状态操作:例如对集合中所有元素做转换,或者过滤,不用保存别的元素的处理结果
- 有状态操作:例如排序,去重操作,需要保存之前集合中元素的状态
- 非短路操作:按部就班完成迭代,返回处理结果
- 短路操作:只有一达到预设的条件,立刻停止并返回
下图给出了Stream给出的一些常用api的基本信息
基本数据类型流
为了避免自动装箱拆箱消耗性能,Stream为我们提供了IntStream、DoubleStream和LongStream,分别将流中的元素特化为int、long和double,这些特殊的流中提供了range,sum,max等数字类型常用的api
并行流
当我们面对计算是否密集的应用开发时,为了充分利用硬件资源,可以简单的通过改变parallel方法将流变成并行执行,但是在使用时有如下注意事项。
- 并行流是通过 fork/join 线程池来实现的,该池是所有并行流共享的。默认情况,fork/join 池会为每个处理器分配一个线程。假设你有一台16核的机器,这样你就只能创建16个线程。而与此同时其他任务将无法获得线程被阻塞住,所以使用并行流要结合机器和业务场景。
- 避免在并行流中改变共享状态,小心使用有状态的操作
- 并行流并不一定就快,要将多个线程的执行结果汇总
实战
相信大家最关心的还是实际开发中能帮助我们解决哪些问题,通过一些简单案例熟悉各种操作的用法
开始操作
生成空流
Stream<Object> empty = Stream.empty();
值生成流
Stream<String> stringStream = Stream.of("1", "2", "3");
数组生成流
String[] strings = { "1", "2", "3"};
Stream<String> stream = Arrays.stream(strings);
集合生成流
List<String> strings1 = Arrays.asList("1", "2", "3");
Stream<String> stream1 = strings1.stream();
文件生成流
Stream<String> lines = Files.lines(Paths.get("/c/mnt/"));
函数生成流(无限流)
// 无限流,流从0开始,下面的每个元素依次加2
Stream<Integer> iterate = Stream.iterate(0, num -> num + 2);
// 无限流,流中每个元素都是 0~1 随机数
Stream<Double> generate = Stream.generate(Math::random);
数值范围生成流
// 生成0到10的int流
IntStream intStream = IntStream.rangeClosed(0, 10);
// 生成0到9的int流
IntStream intStream1 = IntStream.range(0, 10);
手动生成流
// 生成有字符串a和数字1的异构的流
Stream.builder().add("a").add(1).build().forEach(System.out::print);
合并两个流
Stream.concat(
Stream.of("1", 22, "333"),
Stream.of("1", 22, 333)
).forEach(System.out::print);
中间操作
在介绍中间操作时,为了方便学习演示使用到了终端操作中的foreach方法,作用就和我们写的foreach循环类似,遍历执行,不返回值。
过滤filter
// 过滤所有空字符串,注意是返回 true的留下
Stream.of("1", null, "2", "", "3")
.filter(StringUtils::isNotEmpty)
.forEach(System.out::print);
去重distinct
// 去掉重复的2
Stream.of("1", "2", "2", "2", "3")
.distinct()
.forEach(System.out::print);
跳过skip
// 跳过前两个元素
Stream.of("1", "2", "3", "4", "5")
.skip(2)
.forEach(System.out::print);
截短limit
// 与skip相反,只留下前2个
Stream.of("1", "2", "3", "4", "5")
.limit(2)
.forEach(System.out::print);
映射map
@Data
@AllArgsConstructor
public class Person {
private String name;
}
// 将流中每个字符串转为Person实例
Stream.of("1", "2", "3")
.map(Person::new)
.forEach(System.out::print);
// 将流每个字符串变成其长度,为了避免自动拆箱,使用mapToInt转为IntStream
Stream.of("1", "2", "3")
.mapToInt(String::length)
.forEach(System.out::print);
扁平映射flatMap
用法和map类似,当我们需要把流中的每个元素全映射另外一个流,也就是数据在流中流里面,这时候操作就不方便,借助flatMap,我们可以把所有第二层流中的元素合并到最外层流
// 每个字符串按照逗号分隔合并成一个流
Stream.of("1,2,3", "4,5,6", "7,8,9")
.flatMap(a -> Stream.of(a.split(",")))
.forEach(System.out::print);
排序sorted
Stream.of("4", "3", "5")
.sorted()
.forEach(System.out::print);
Stream.of("4", "3", "5")
.sorted(Comparator.naturalOrder())
.forEach(System.out::print);
并行流相关parallel,sequential,unordered
// 串行流转并行流
Stream.of("1", "2", "3").parallel();
// 并行流转串行流
Arrays.asList("1", "2", "3").parallelStream().sequential();
// 在并行流中加上unordered,使得流变成无序,提供并行效率,此时limit相当于随机取2个元素
Arrays.asList("1", "2", "3", "4", "5")
.parallelStream()
.unordered()
.limit(2).forEach(System.out::print);
调试peek
用于debug调试代码,在每次执行操作前,看一眼元素
// 每个元素会打印两遍
Stream.of("1", "2", "3").peek(System.out::print).forEach(System.out::print);
终端操作
遍历foreach
Stream.of("1", "2", "3").forEach(System.out::print);
// 并行流中使用用于保持有序
Arrays.asList("1", "2", "3").parallelStream().forEachOrdered(System.out::print);
通用统计count,max,min
// 总个数,返回true|false
Stream.of("1", "2", "3").count();
// 最大元素,返回Optional
Stream.of("1", "2", "3").max(Comparator.naturalOrder());
// 最小元素,返回Optional
Stream.of("1", "2", "3").min(Comparator.naturalOrder());
数值流特有统计sum,average,summaryStatistics
以 IntStream 举例
// 累加求和
Stream.of("1", "2", "3").mapToInt(Integer::valueOf).sum();
// 求平均数
Stream.of("1", "2", "3").mapToInt(Integer::valueOf).average();
// 总和,最大值,最小值,平均数,总个数,应有尽有
Stream.of("1", "2", "3").mapToInt(Integer::valueOf).summaryStatistics();
匹配match
返回true|false
// 是否有长度大于 2 的字符串
Stream.of("1", "22", "333").anyMatch(s -> s.length() > 2);
// 是否一个长度大于 2 的字符串也没有
Stream.of("1", "22", "333").noneMatch(s -> s.length() > 2);
// 是否字符串长度全大于 2
Stream.of("1", "22", "333").allMatch(s -> s.length() > 2);
查找find
由于是短路操作,所以只有在串行流中findAny和findFirst才区别明显
// 找到流中任意一个元素,普通流一般也返回第一个元素,并行流中返回任意元素
Stream.of("1", "22", "333").findAny();
// 找到流中第一个元素,普通流和并行流都一样
Stream.of("1", "22", "333").findFirst();
汇总collect
把所有处理结果汇总,Collectors收集器里提供了很多常用的汇总操作
// 将结果汇总成一个list
Stream.of("1", "22", "333").collect(Collectors.toList());
归约reduce
谷歌著名的map-reduce理想,用于最后汇总结果
// 0作为起始的pre,流的结果等于pre乘以自身再加一,直到curr到达最后一个元素
// (1) pre = 0 curr = 1 计算 pre = 0 * 1 + 1 = 1
// (2) pre = 1 curr = 2 计算 pre = 1 * 2 + 1 = 3
// (3) pre = 3 curr = 3 计算 pre = 3 * 3 + 1 = 10
// (4) pre = 10 curr = null 返回结果 10
IntStream.of(1, 2, 3).reduce(0, (pre, curr) -> pre * curr + 1);
// 当然如果不设置初始值,流中第一个元素就是pre
IntStream.of(1, 2, 3).reduce((pre, curr) -> pre * curr + 1);
转数组toArray
Stream.of("1", "22", "333").toArray();
获得迭代器iterator
Stream.of("1", "2", "3").iterator();
获得并行可分迭代器spliterator
Stream.of("1", "2", "3").spliterator();
流类型判断isParallel
Stream.of("1", "2", "3").isParallel();
收集器进阶
在 collect 操作的介绍中,我们用了 Collectors 中提供的 toList 方法将结果汇总成List,collect 是很常用的操作Collectors中有很多有用的方法,这也使得 collect 成为 reduce 更高阶的实现,很多终端方法可用 collect 来实现,如果都不能满足需求我们还可以自己实现一个
转常用集合
// 转list
List<String> collect = Stream.of("1", "2", "3").collect(Collectors.toList());
// 转set
Set<String> collect = Stream.of("1", "2", "3").collect(Collectors.toSet());
// 转map,key为字符串长度,value为字符串本身
Map<Integer, String> collect = Stream.of("1", "2", "3")
.collect(Collectors.toMap(String::length, Function.identity()));
// 转并发版map,key为字符串长度,value为字符串本身
Map<Integer, String> collect = Stream.of("1", "2", "3")
.collect(Collectors.toConcurrentMap(String::length, Function.identity()));
// 转指定类型集合
ArrayList<String> collect = Stream.of("1", "2", "3")
.collect(Collectors.toCollection(ArrayList::new));
拼接字符串
// 拼接成一个字符串
String collect = Stream.of("1", "2", "3").collect(Collectors.joining());
// 拼接成一个字符串,逗号分隔
String collect = Stream.of("1", "2", "3").collect(Collectors.joining(","));
统计
都有对应简化版,一些更加灵活多变的操作可以用Collectors
// 和终端操作中的 max 等价
Stream.of("1", "2", "3").collect(Collectors.maxBy(Comparator.naturalOrder()));
// 和终端操作中的 min 等价
Stream.of("1", "2", "3").collect(Collectors.minBy(Comparator.naturalOrder()));
// 和终端操作中的 count 等价
Stream.of("1", "2", "3").collect(Collectors.counting(Integer::valueOf));
// 和数值流终端操作中的 sum 等价
Stream.of("1", "2", "3").collect(Collectors.summingInt(Integer::valueOf));
// 和数值流终端操作中的 average 等价
Stream.of("1", "2", "3").collect(Collectors.averagingInt(Integer::valueOf));
// 和数值流终端操作中的 summaryStatistics 等价
Stream.of("1", "2", "3").collect(Collectors.summarizingInt(Integer::valueOf));
分组
可以和其他收集器方法任意组合
// 以字符串长度分成3组,map的key为长度,value为对应长度字符串list
Map<Integer, List<String>> collect = Stream.of("1", "22", "33", "4", "555")
.collect(Collectors.groupingBy(String::length));
// 以字符串长度分成3组,map的key为长度,value为对应的元素个数
Map<Integer, Long> collect = Stream.of("1", "22", "33", "4", "555")
.collect(Collectors.groupingBy(String::length, Collectors.counting()));
// 这个例子没有实际意义,展示我们可以进行二级分组,长度分组完毕,再组内以hash值分组
Map<Integer, Map<Integer, List<String>>> collect = Stream.of("1", "22", "33", "4", "555")
.collect(Collectors.groupingBy(
String::length,
Collectors.groupingBy(String::hashCode)
));
分区
分区时特殊的分组,使用方法类似,特殊是通过谓词表达式只能分成两组,true是一组,false是一组
// 以长度大于2为标准分区
Map<Boolean, List<String>> collect = Stream.of("1", "22", "33", "4", "555")
.collect(Collectors.partitioningBy(s -> s.length() > 2));
归约
// 和终端操作 reduce 等价
Stream.of("1", "22", "33", "4", "555")
.collect(Collectors.reducing(0, Integer::valueOf, Integer::sum))
多操作连接
// 把流汇总成list,然后再求出其容量
Integer collect = Stream.of("1", "22", "33", "4", "555")
.collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
自定义
有些时候默认的实现有缺陷,或者追求更高的性能我们需要自己实现收集器。只要实现 Collector<T, A , R>接口 中的方法我们就可以获得自己的收集器,其中 T 是元素泛型,A是累加器结果,R是最终返回结果,所有首先我们来看下要实现哪些方法
- supplier:提供一个容器 A 装结果
- accumulator:累加器,将元素累加进刚才创建的容器
- combiner:合并容器的结果
- finisher:完成操作,将 A 转为 R 返回
- characteristics:是个定义标识的方法
- UNORDERED:结果不受流中项目的遍历和累积顺序的影响
- CONCURRENT:accumulator函数可以从多个线程同时调用
- IDENTITY_FINISH:表示 finisher 没做任何事情,直接返回了累加的结果,也就是A和R相同
public static final Collector<String, List<String>, List<String>> myToList = Collector.of(
// supplier: 创建 A(ArrayList)
ArrayList::new,
// accumulator:把每个元素放入 A 中
(list, el) -> list.add(el),
// combiner:如果并行拆分成多个流,直接 addAll 合并
// 如果不想支持并行可以写个空,或抛UnsupportedOperationException异常
(listA, listB) -> {
listA.addAll(listB);
return listA;
},
// finisher:不做任何事情,直接返回 A
Function.identity(),
// characteristics...:表示 A R 类型相同, 且支持并行流
Collector.Characteristics.IDENTITY_FINISH,
Collector.Characteristics.CONCURRENT
);
// 自定义收集器转成list
List<String> collect = Stream.of("1", "22", "33", "4", "555").collect(myToList);