JAXP技术
JAXP即Java Api for Xml Processing该API主要是SUN提供的用于解析XML数据的一整套解决方案,主要包含了DOM和SAX解析技术。大家可以参见SUN的以下两个包:
javax.xml.parsers.* 主要存储的是解析器
org.w3c.dom.*或org.w3c.sax.* 主要存储的是DOM解析或SAX解析需要的API
DOM解析主要采用DOM树的方式进行XML的数据解析。如:JavaScript中的DOM操作
SAX解析主要采用事件的方式进行XML的数据解析。 如:JavaScript中的事件机制

- 编写需要解析的XML文件
- 获取相应的XML解析器对象
- 使用API获取数据
- 返回数据给开发者
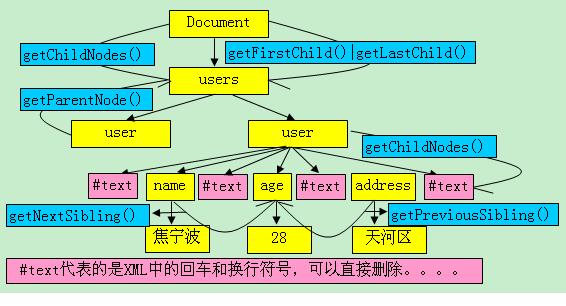
其中回车换行也算是一个元素,所以底下xml文件中的users节点有个节点,其中3个为#text的打印
1 <?xml version="1.0" encoding="UTF-8" standalone="no"?> 2 <users> 3 <user> 4 <name>jack</name> 5 <age>26</age> 6 <address>gz</address> 7 </user> 8 <user><name>二货</name><age>28</age><address>天河区</address></user> 9 </users>
1 import org.w3c.dom.Document; 2 import org.w3c.dom.Element; 3 import org.w3c.dom.Node; 4 import org.w3c.dom.NodeList; 5 6 public class Demo1 { 7 8 // 2. 提供获取解析器的方法 9 public static DocumentBuilder getParser()throws Exception{ 10 // 2.1 创建工厂类对象 11 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 12 // 2.2 获取解析器对象 13 DocumentBuilder parser = factory.newDocumentBuilder(); 14 return parser; 15 } 16 17 // 3. 提供获取DOM数据的方法 18 public static Document getDOM(File file)throws Exception{ 19 // 3.1 获取解析器 20 DocumentBuilder parser = getParser(); 21 // 3.2解析数据 22 Document dom = parser.parse(file); 23 return dom; 24 } 25 26 // 4. 提供解析根元素的数据的方法 27 public static void getRoot(File file)throws Exception{ 28 // 4.1 获取DOM树 29 Document dom = getDOM(file); 30 // 4.2遍历dom树找根元素 31 Node node = dom.getElementsByTagName("users").item(0); 32 // 4.3输出根元素的名 33 System.out.println(node.getNodeName()); 34 // 4.4根据节点直接的关系获取根元素 35 NodeList list = dom.getChildNodes(); 36 Node root = list.item(0); 37 System.out.println(root.getNodeName()); 38 root = dom.getFirstChild(); 39 System.out.println(root.getNodeName()); 40 root = dom.getLastChild(); 41 System.out.println(root.getNodeName()); 42 } 43 44 // 5. 添加一个user节点 45 public static Document addElement(File file)throws Exception{ 46 // 5.1获取DOM树 47 Document dom = getDOM(file); 48 // 5.2创建user元素 49 Element user = dom.createElement("user"); 50 Element name = dom.createElement("name"); 51 Element age = dom.createElement("age"); 52 Element address = dom.createElement("address"); 53 54 name.setTextContent("焦宁波"); 55 age.setTextContent("28"); 56 address.setTextContent("天河区"); 57 // 5.3建立关系 58 Element root = (Element) dom.getFirstChild(); 59 user.appendChild(name); 60 user.appendChild(age); 61 user.appendChild(address); 62 root.appendChild(user); 63 // 5.4返回修改后的DOM树对象 64 return dom; 65 } 66 67 // 6. 修改第二个user的年龄为30岁 68 public static Document modifyElement(File file)throws Exception{ 69 // 6.1获取DOM树 70 Document dom = getDOM(file); 71 // 6.2获取第二个age元素 72 Node age2 = dom.getElementsByTagName("age").item(1); 73 // 6.3设置文本值 74 age2.setTextContent("30"); 75 return dom; 76 } 77 78 // 7. 删除第一个user节点 79 public static Document removeElement(File file)throws Exception{ 80 // 7.1获取DOM树 81 Document dom = getDOM(file); 82 // 7.2获取user的父亲 83 dom.getElementsByTagName("user").item(0).getParentNode().removeChild(dom.getElementsByTagName("user").item(0)); 84 return dom; 85 } 86 87 // 8. 使用关系获取节点 88 public static void searchElement(File file)throws Exception{ 89 // 8.1获取DOM树 90 Document dom = getDOM(file); 91 // 8.2获取第二个user的所有的子元素并输入元素名 92 Element user2 = (Element) dom.getElementsByTagName("user").item(1); 93 // 8.3获取所有的儿子 94 NodeList list = user2.getChildNodes(); 95 // 8.4遍历所有的孩子 96 for(int i = 0;i<list.getLength();i++){ 97 Node node = list.item(i); 98 System.out.println(node.getNodeName()); 99 } 100 // 8.5获取第二个user的address元素 101 Element address2 = (Element) list.item(2); 102 System.out.println(address2.getNodeName()); 103 Node age2 = address2.getPreviousSibling(); 104 System.out.println(age2.getNodeName()); 105 106 Element name2 = (Element) list.item(0); 107 System.out.println(name2.getNodeName()); 108 age2 = name2.getNextSibling(); 109 System.out.println(age2.getNodeName()); 110 111 } 112 113 114 // 提供一个工具方法将内存中的DOM树存储到磁盘的指定文件中 115 public static void writeDOM2XML(Document dom,File file)throws Exception{ 116 // 1.获取转换器的工厂类对象 117 TransformerFactory factory = TransformerFactory.newInstance(); 118 // 2.获取转换器对象 119 Transformer trans = factory.newTransformer(); 120 // 3.转换 121 trans.transform(new DOMSource(dom), new StreamResult(new FileOutputStream(file))); 122 } 123 124 125 public static void main(String[] args) throws Exception{ 126 File file = new File("users.xml"); 127 //getRoot(file); 128 //Document dom = addElement(file); 129 //Document dom = modifyElement(file); 130 //Document dom = removeElement(file); 131 //writeDOM2XML(dom, file); 132 searchElement(file); 133 134 } 135 136 }