在数据挖掘过程中,经常会有不同表格的数据需要进行合并操作。今天介绍通过python下的pandas库下的merge方法和concat方法来实现数据集的合并。
1.merge
merge 函数通过一个或多个键来将数据集的行连接起来。该函数的主要 应用场景是针对同一个主键存在两张包含不同特征的表,通过该主键的连接,将两张表进行合并。合并之后,两张表的行数没有增加,列数是两张表的列数之和减一。
函数的具体参数为:
merge(left,right,how='inner',on=None,left_on=None,right_on=None,
left_index=False,right_index=False,sort=False,suffixes=('_x','_y'),copy=True)- 1
- 2
- on=None 指定连接的列名,若两列希望连接的列名不一样,可以通过left_on和right_on 来具体指定
- how=’inner’,参数指的是左右两个表主键那一列中存在不重合的行时,取结果的方式:inner表示交集,outer 表示并集,left 和right 表示取某一边。
举例如下
import pandas as pd
df1 = pd.DataFrame([[1,2,3],[5,6,7],[3,9,0],[8,0,3]],columns=['x1','x2','x3'])
df2 = pd.DataFrame([[1,2],[4,6],[3,9]],columns=['x1','x4'])
print df1
print df2
df3 = pd.merge(df1,df2,how = 'left',on='x1')
print df3- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这里我分别设置了两个DataFrame类别的变量df1,df2,(平常我们用的表csv文件,读取之后也是DataFrame 格式)。然后我设置 on=’x1’,即以两个表中的x1为主键进行连接,设置how=’left’ ,即是以两个表中merge函数中左边那个表的行为准,保持左边表行数不变,拿右边的表与之合并。结果如下:
第一个结果为how=’left’的情况。第二个结果为how=’inner’的情况。
注意:在how=’left’设置后,左边行之所以能够保持不变,是因为右边的表主键列没有重复的值,x下面我会举个例子作为思考题: 
这是两张表,分别为df1,df2;

第一个问题:
在默认情况下即merge(df1,df2)其他参数为默认值的返回结果是 什么?
第二个问题:
在加上how=’left’之后的返回结果是什么?
看完了问题之后,返回去看这两张表,不着急看答案,仔细想想。

这两个问题明白之后,表之间的连接和映射应该都能够明白了。
2.concat
concat 与其说是连接,更准确的说是拼接。就是把两个表直接合在一起。于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis 。
函数的具体参数是:
concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False)- 1
- objs 是需要拼接的对象集合,一般为列表或者字典
- axis=0 是行拼接,拼接之后行数增加,列数也根据join来定,join=’outer’时,列数是两表并集。同理join=’inner’,列数是两表交集。
在默认情况下,axis=0为纵向拼接,此时有
concat([df1,df2]) 等价于 df1.append(df2)- 1
在axis=1 时为横向拼接 ,此时有
concat([df1,df2],axis=1) 等价于 merge(df1,df2,left_index=True,right_index=True,how='outer')- 1
举个例子
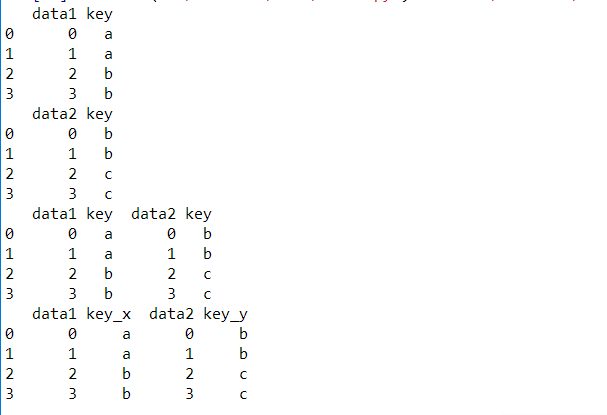
import pandas as pd
df1 = pd.DataFrame({'key':['a','a','b','b'],'data1':range(4)})
print df1
df2 = pd.DataFrame({'key':['b','b','c','c'],'data2':range(4)})
print df2
print pd.concat([df1,df2],axis=1)
print pd.merge(df1,df2,left_index=True,right_index=True,how='outer')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8