PAI简介
阿里云机器学习PAI(Platform of Artificial Intelligence)是一款一站式的机器学习平台,包含数据预处理、特征工程、常规机器学习算法、深度学习框架、模型的评估以及预测这一整套机器学习相关服务。由于目前PAI还属于公测阶段,所以是不收费的。但是PAI底层依赖于maxcompute(计算)和oss(存储),所以会收取一定的托管费和深度学习存储费用。不过实测发现每天差不多一两分钱,充10块能玩好久。
实验准备
实验的整个过程都在官方文档有很详细的说明:https://yq.aliyun.com/articles/72841,所以我看着文档做了一遍,最终是成功了,不过也发现一些问题,在这里把它记录下来。
首先为了完成实现我们得有阿里云账号,申请云账号AccessKey,然后开通机器学习和oss服务,这些都可以在官网相应产品下点击开通,很方便。
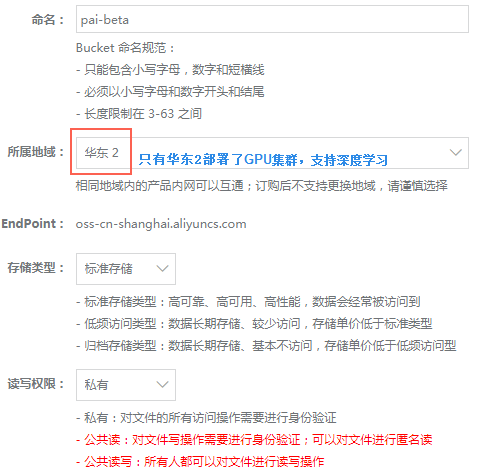
进入控制台->机器学习,从这里创建一个项目,所属区域一定要选择华东2,因为目前阿里只有华东2区支持深度学习的GPU集群,而且oss在华东2区不产生流量费用,在读取OSS数据时会产生请求费用,请求费用为0.01元/万次。OSS的存储费用为0.148元/GB/月,还是很便宜。
深度学习与GPU
深度学习是人工智能 (AI) 中发展迅速的领域之一,可帮助计算机理解大量图像、声音和文本形式的数据。利用多层次的神经网络,现在的计算机能像人类一样观察、学习复杂的情况,并做出相应的反应,有时甚至比人类做得还好。这样便提供了一种截然不同的方式,用于思考数据、技术以及人类所提供的产品和服务。通常说到计算我们首先想到的是CPU,GPU是图形处理器。CPU和GPU的设计目标是不同的,针对了两种不同的应用场景:CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境(扩展:https://www.zhihu.com/question/19903344)。
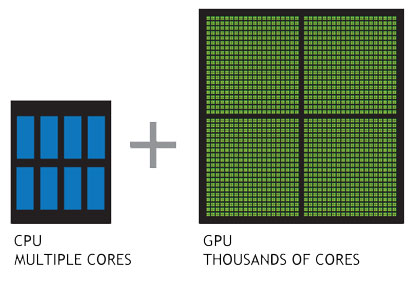
上面的图是从NVIDIA官网扒过来的,CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。(官网链接:http://www.nvidia.cn/object/what-is-gpu-computing-cn.html)
阿里PAI深度学习使用的GPU是NVIDIA Tesla M40,一款专注深度学习模型训练的GPU,性能还是很强劲的,这是官方一张图:

GPU和CPU在深度学习训练时GPU速度更快,这点很重要,因为机器学习会有大量复杂算法,NVIDIA GPU 特别擅长处理并行工作负载,可让网络提速 10-20 倍,从而将各个数据训练迭代周期从几个星期缩短为几天。实际上,GPU 在仅仅三年内便将深度神经网络 (DNN) 的训练速度提高了 50 倍(这一速度远远超过摩尔定律),预计未来几年还将再提高 10 倍。
开始实验
对机器学习领域的深度学习有了一个简单的认识之后,我们利用阿里PAI做一个简单的实验:Tensorflow图片分类。上面已经准备好了必要的环境,接下来进入机器学习模块,点击首页,从模板创建一个实验:Tensorflow图片分类,在左侧设置里面开启oss访问权限。然后得到下面的可视化模型:
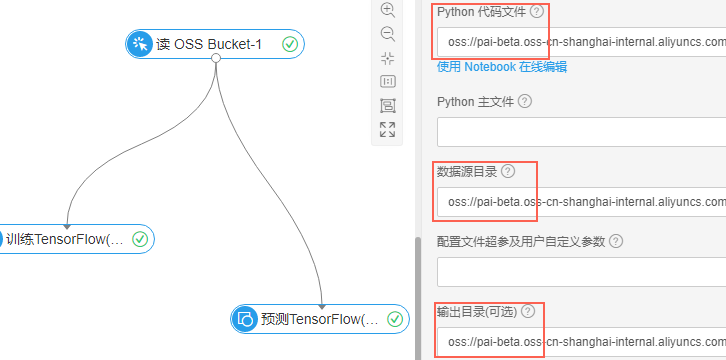
点击组件进行参数设置。这里的参数要配置执行训练的python代码文件,训练集文件目录,以及输出模型目录。这些都是放在oss上的,所以要先在oss上创建bucket,然后创建文件夹,把我们需要的资源放进去。这里采用的是cifar-10数据集(http://www.cs.toronto.edu/~kriz/cifar.html),由60000张32*32的RGB彩色图片构成,共10个分类,50000张用来训练模型,10000张做测试,交叉验证。所有资源可以在这里下载:https://help.aliyun.com/document_detail/51800.html。实验目的是:利用cifar-10数据集训练模型,然后给定一张图片让机器自己识别它是哪一类。
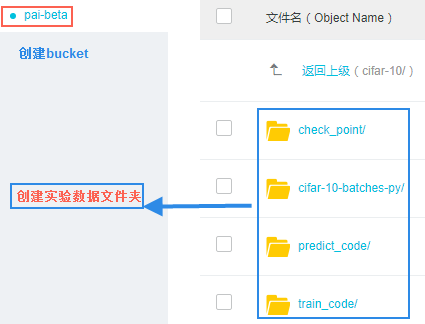
如图,创建四个文件夹:1)check_point:用来存放实验生成的模型。2)cifar-10-batches-py:用来存放训练数据以及预测集数据,对应的是下载下来的数据源cifar-10-batcher-py里面的文件和预测图片bird_bullocks_oriole.jpg文件,放在一起就行。3)train_code:用来存放训练代码,也就是cifar_pai.py。4)predict_code:用来存放预测代码cifar_predict_pai.py。
训练模型
一切准备好之后,我们就可以进行实验了。可以看上面的图,点击训练模块,进行参数设置:python代码文件选择train_code/cifar_pai.py文件,数据源目录选择cifar-10-batches-py文件夹,输出目录选择check_point文件夹。然后右键点击该模块,选择“执行该节点”,开始训练模型。这个过程大约需要20分钟左右。右键点击模块可以查看日志,执行完之后模块会有一个绿色的勾,表示完成。生成的模型在check_point/model/文件夹下(注意文中红色部分,设置参数时注意选择正确,否则会报错)。
预测结果
模型训练完成,接下来就是利用模型进行图片分类。设置预测模块的参数:python代码文件这里要选择predict_code/cifar_predict_pai.py文件,数据源目录和输出目录和上面一样选择对应文件夹。这里执行该节点会报错,查看日志会显示如下结果:
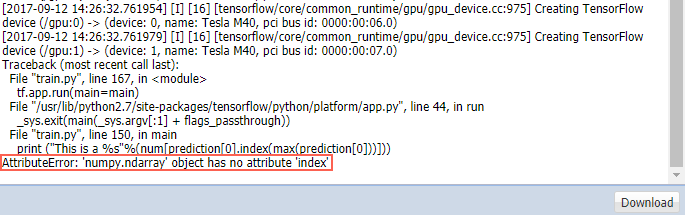
报错原因是ndarray没有Index函数,需要把下载的cifar_predict_pai.py修改:
1 # Predict 2 prediction = model.predict([img]) 3 print (prediction[0]) 4 print (prediction[0]) 5 #print (prediction[0].index(max(prediction[0]))) 6 num=['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck'] 7 8 #注释掉这行:
9 # print ("This is a %s"%(num[prediction[0].index(max(prediction[0]))])) 10 #改为下面代码: 11 print ("This is a %s"%(num[np.argmax(prediction[0])]))
应该是python2和3版本差异问题。修改完之后再上传到oss相应目录,再次运行节点前先删除check_point下stdout文件夹(不要删model,训练的模型可以继续用),等待执行结束可以到logview查看预测结果。
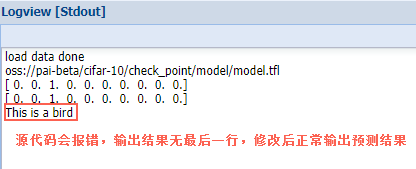
这样就完成了训练模型和结果预测。其实整个实验过程比较简单,毕竟图形化界面操作体验很好,再加上是案例,提供代码,所以目的就是熟悉阿里PAI深度学习的操作步骤和实验流程,这并不是“深度学习入门xx”,只是一个案例,因为即使不懂代码和原理一样可以得到结果。机器学习是一门很深的课程,它所涉及到的很多算法原理才是学习的重点,了解常用算法的分类和不同算法的适用场景才能发挥机器学习的价值,解决了实际问题才是机器学习的根本所在。
~到此为止~