String 字符串
存储类型
可以用来存储字符串、整数、浮点
存储(实现)原理
数据模型
以set a 123 为例,因为 Redis 是 KV 的数据库,它是通过 hashtable 实现的(我们把这个叫做外层的哈希)。所以每个key value键值对都会有一个dictEntry(源码位置:dict.h),里面指向了key和value的指针。next指向下一个dictEntry。
typedef struct dictEntry {
void *key; /* key 关键字定义 */
union {
void *val; uint64_t u64; /* value 定义 */
int64_t s64; double d;
} v;
struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry;
key是字符串,存储在自定义的SDS中。
value 既不是直接作为字符串存储,也不是直接存储在SDS中,而是存储在redisObject中。实际上五种常用的数据类型的任何一种,都是通过 redisObject来存储的。
SDS
Redis中字符串的底层实现。
优点:
- 不用担心内存溢出问题,如果需要会对 SDS 进行扩容。
- 获取字符串长度时间复杂度为 O(1),因为定义了 len 属性。
- 通过“空间预分配”( sdsMakeRoomFor)和“惰性空间释放”,防止多次重分配内存。
redisObject
typedef struct redisObject {
unsigned type:4; /* 对象类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */
unsigned encoding:4; /* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */
int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了*/
void *ptr; /* 指向对象实际的数据结构 */
} robj;
内部编码
字符串类型的内部编码有三种:
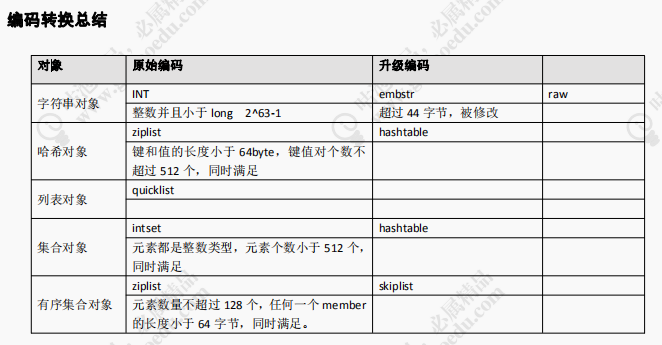
1、int,存储 8 个字节的长整型(long,2^63-1)。
2、embstr, 代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串),存储小于 44 个字节的字符串。
3、raw,存储大于 44 个字节的字符串(3.2 版本之前是 39 字节)。
embstr和raw 的区别:
embstr的使用只分配一次内存空间(因为RedisObject和SDS是连续的),而raw需要分配两次内存空间(分别为RedisObject和SDS分配空间)。
embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个RedisObject 和 SDS 都需要重新分配空间,因此 Redis 中的 embstr 实现为只读。
int 和 embstr 什么时候转化为 raw?
当int数据不再是整数,或大小超过了long的范围时,自动转化为embstr。
对于embstr,由于其实现是只读的,因此在对 embstr 对象进行修改时,都会先转化为 raw 再进行修改。
因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
Redis 内部编码的转换换过程不可逆,只能从小内存编码向大内存编码转换。
应用场景
缓存: 热点数据缓存(例如报表,明星出轨),对象缓存,全页缓存。可以提升热点数据的访问速度。
数据共享分布式: 分布式 Session
分布式锁:
全局ID:
计数器: 文章的阅读量,微博点赞数,允许一定的延迟,先写入 Redis 再定时同步到数据库。
限流: 以访问者的 IP 和其他信息作为 key,访问一次增加一次计数,超过次数则返回 false。
Hash 哈希
存储类型
包含键值对的无序散列表。value 只能是字符串,不能嵌套其他类型。
Hash与String的主要区别?
1、把所有相关的值聚集到一个key中,节省内存空间
2、只使用一个key,减少key冲突
3、当需要批量获取值的时候,只需要使用一个命令,减少内存、IO、CPU的消耗
操作命令
hset user name fuyu
hset user age 27
hmset user sex 0 birth 1993
hget user name
hmget user age sex birth
hkeys user
hlen user
hdel user
存储实现原理
Hash本身也是一个KV的结构,类似于Java中的 HashMap。
外层的哈希(Redis KV 的实现)只用到了 hashtable。当存储 hash 数据类型时,我们把它叫做内层的哈希。
内层的哈希底层可以使用两种数据结构实现:
ziplist:(压缩列表)
hashtable:(哈希表)
ziplist 压缩列表
ziplist是一个经过特殊编码的双向链表,存储上一个节点长度和当前节点长度。
通过牺牲部分读写性能,来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
当 hash 对象同时满足以下两个条件的时候,使用 ziplist 编码:
1)所有的键值对的健和值的字符串长度都小于等于64字节(一个英文字母一个字节);
2)哈希对象保存的键值对数量小于512个
hash-max-ziplist-value 64 // ziplist 中最大能存放的值长度
hash-max-ziplist-entries 512 // ziplist 中最多能存放的 entry 节点数量
当一个哈希对象超过配置的阈值(键和值的长度有>64字节,键值对个数>512个)时,会转换成哈希表(hashtable)。
hashtable哈希表
在 Redis 中,hashtable 被称为字典(dictionary),它是一个数组+链表的结构。
应用场景:
存储对象类型的数据、购物车
List 列表
存储类型
存储有序的字符串(从左到右),元素可以重复。可以充当队列和栈的角色
操作命令
元素增减:
lpush queue a
lpush queue b
lpop queue
rpop queue
blpop queue
brpop queue
取值
lindex queue 0
lrange queue 0 -1
存储(实现)原理
在早期的版本中,数据量较小时用ziplist存储,达到临界值时转换为linkedlist进行存储
3.2版本之后,统一用quicklist来存储。quicklist存储了一个双向链表,每个节点都是一个ziplist。
quicklist是 ziplist 和 linkedlist 的结合体。
应用场景
用户消息时间线 timeline
因为 List 是有序的,可以用来做用户时间线
消息队列
队列:先进先出:rpush blpop,左头右尾,右边进入队列,左边出队列。
栈:先进后出:rpush brpop
Set 集合
存储类型
String 类型的无序集合
操作命令
//添加一个或者多个元素
sadd myset a b c d e f g
//获取所有元素
smembers myset
//统计元素个数
scard myset
//随机获取一个元素
srandmember key
//随机弹出一个元素
spop myset
//移除一个或者多个元素
srem myset d e f
//查看元素是否存在
sismember myset a
存储(实现)原理
Redis用intset或hashtable存储set。如果元素都是整数类型,就用inset存储。否则就用 hashtable(数组+链表的存来储结构)。
抽奖
spop myset 随机获取元素
点赞、签到、打卡
这条微博的 ID 是 wb001,用户 ID 是 user001。
用 like:wb001 来维护 wb001 这条微博的所有点赞用户。
点赞了这条微博:sadd like:wb001 user001
取消点赞:srem like:wb001 user001
是否点赞:sismember like:wb001 user001
点赞的所有用户:smembers like:wb001
点赞数:scard like:wb001
商品标签
用 tags:i5001 来维护商品所有的标签。
sadd tags:i5001 画面清晰细腻
sadd tags:i5001 真彩清晰显示屏
sadd tags:i5001 流畅至极
商品筛选
获取差集
sdiff set1 set2
获取交集(intersection )
sinter set1 set2
获取并集
sunion set1 set2
添加包含该属性对应的手机型号
sadd brand:apple iPhone11
sad screensize:6.0-6.24 iPhone11
sad screentype:lcd iPhone11
筛选商品,苹果的,屏幕在 6.0-6.24 之间的,屏幕材质是 LCD 屏幕
sinter brand:apple screensize:6.0-6.24 screentype:lcd
共同关注,朋友圈
ZSet 有序集合
存储类型
sorted set,有序的set,每个元素有个score,score相同时,按照key的ASCII码排序。
操作命令
添加元素
zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python
获取全部元素
zrange myzset 0 -1 withscores
zrevrange myzset 0 -1 withscores
根据分值区间获取元素
zrangebyscore myzset 20 30
移除元素也可以根据score rank删除
zrem myzset php cpp
统计元素个数
zcard myzset
分值递增
zincrby myzset 5 python
根据分值统计个数
zcount myzset 20 60
获取元素
rankzrank myzset java
获取元素
scorezsocre myzset java
存储(实现)原理
同时满足以下条件时使用 ziplist 编码:
- 元素数量小于128个
- 所有member的长度都小于64字节
在ziplist的内部,按照score排序递增来存储。插入的时候要移动之后的数据。
超过阈值之后,使用 skiplist+dict 存储。
skiplist 跳跃表
应用场景
排行榜
id 为 6001 的新闻点击数加 1:zincrby hotNews:20190926 1 n6001
获取今天点击最多的 15 条:zrevrange hotNews:20190926 0 15 withscores
其他数据结构简介
BitMaps
Bitmaps 是在字符串类型上面定义的位操作。一个字节由 8 个二进制位组成。
总结
数据结构总结
编码转换总结
应用场景
- 缓存——提升热点数据的访问速度
- 共享数据——数据的存储和共享的问题
- 全局 ID —— 分布式全局 ID 的生成方案(分库分表)
- 分布式锁——进程间共享数据的原子操作保证
- 在线用户统计和计数
- 队列、栈——跨进程的队列/栈
- 消息队列——异步解耦的消息机制
- 服务注册与发现 —— RPC 通信机制的服务协调中心(Dubbo 支持 Redis)
- 购物车
- 新浪/Twitter 用户消息时间线
- 抽奖逻辑(礼物、转发)
- 点赞、签到、打卡
- 商品标签
- 用户(商品)关注(推荐)模型
- 电商产品筛选
- 排行榜