单表操作
***********************
1. group by 分组
分组指的是:将所有记录按照某个字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等.
select 聚合函数,选取的字段 from 表名 group by 选取的字段;
group by :是分组的关键字
group by 必须和聚合函数(count)出现
where 条件语句和group by 分组语句的先后顺序:
where > group by > having **************
例子:
单独使用group by 分组
select post from employee group post;
我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数
// 创建表字段
create table employee(
id int not null unique auto_increment,
emp_name varchar(20) not null,
sex enum('male','female') not null default 'male', # 大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, # 一个部门一个屋子
depart_id int
);
// 创建表数据
insert into employee(emp_name,sex,age,hire_date,post,salary,office,depart_id) values
-> ('nick','male',18,'20170301','老男孩驻上海虹桥最帅',7300.33,401,1), # 以下是教学部
-> ('jason','male',78,'20150302','teacher',1000000.31,401,1),
-> ('sean','male',81,'20130305','teacher',8300,401,1),
-> ('tank','male',73,'20140701','teacher',3500,401,1),
-> ('oscar','male',28,'20121101','teacher',2100,401,1),
-> ('mac','female',18,'20110211','teacher',9000,401,1),
-> ('rocky','male',18,'19000301','teacher',30000,401,1),
-> ('成龙','male',48,'20101111','teacher',10000,401,1),
->
-> ('歪歪','female',48,'20150311','sale',3000.13,402,2), # 以下是销售部门
-> ('丫丫','female',38,'20101101','sale',2000.35,402,2),
-> ('丁丁','female',18,'20110312','sale',1000.37,402,2),
-> ('星星','female',18,'20160513','sale',3000.29,402,2),
-> ('格格','female',28,'20170127','sale',4000.33,402,2),
->
-> ('张野','male',28,'20160311','operation',10000.13,403,3), # 以下是运营部门
-> ('程咬金','male',18,'19970312','operation',20000,403,3),
-> ('程咬银','female',18,'20130311','operation',19000,403,3),
-> ('程咬铜','male',18,'20150411','operation',18000,403,3),
-> ('程咬铁','female',18,'20140512','operation',17000,403,3)
-> ;
Query OK, 18 rows affected (0.01 sec)
// 打印表数据
+----+----------+--------+-----+------------+----------------------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+----------+--------+-----+------------+----------------------+--------------+------------+--------+-----------+
| 1 | nick | male | 18 | 2017-03-01 | 老男孩驻上海虹桥最帅 | NULL | 7300.33 | 401 | 1 |
| 2 | jason | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 3 | sean | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
| 4 | tank | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 5 | oscar | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 |
| 6 | mac | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 |
| 7 | rocky | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 |
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 |
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 |
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 |
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
| 16 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 |
| 17 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 |
| 18 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 |
+----+----------+--------+-----+------------+----------------------+--------------+------------+--------+-----------+
18 rows in set (0.00 sec)
聚合函数
聚合函数聚合的是组的内容,若是没有分组,则默认一组.
count() 计数
1.以性别为例,进行分组,统计一下男生和女生的人数是多少:
select count(id), sex from employee group by sex;
/* 选取的字段与聚合函数互换位置
+-----------+--------+
| count(id) | sex |
+-----------+--------+
| 10 | male |
| 8 | female |
+-----------+--------+
2 rows in set (0.00 sec) */
select sex,count(id) from employee group by sex;
/* 选取的字段在前,聚合字段在后
+--------+-----------+
| sex | count(id) |
+--------+-----------+
| male | 10 |
| female | 8 |
+--------+-----------+
2 rows in set (0.00 sec)
max()最大值
2.对部门进行分组,求出每个部门年龄最大的那个人
select depart_id,max(age) from employee group by depart_id;
/*
+-----------+----------+
| depart_id | max(age) |
+-----------+----------+
| 1 | 81 |
| 2 | 48 |
| 3 | 28 |
+-----------+----------+
3 rows in set (0.00 sec) */
min()最小值
求最小的
sum()求和
求和
select depart_id ,sum(age) from employee group by depart_id;
/*
+-----------+----------+
| depart_id | sum(age) |
+-----------+----------+
| 1 | 362 |
| 2 | 150 |
| 3 | 100 |
+-----------+----------+
3 rows in set (0.01 sec)
avg平均数
根据depart_id进行分组,获得组内平均年龄
select depart_id,avg(age) from employee group by depart_id ;
/*
+-----------+----------+
| depart_id | avg(age) |
+-----------+----------+
| 1 | 45.2500 |
| 2 | 30.0000 |
| 3 | 20.0000 |
+-----------+----------+
3 rows in set (0.00 sec)
2. having 过滤
表示对group by 之后的数据,进行再一次的二次筛选
执行优先级从高到低 : where > group by > having *************
1. where 发生在分组group by 之前,因而where中可以有任意字段,但绝对不能使用聚合函数
2. having 发生在 group by 之后,因而having 中可以使用分组的字段,无法直接获取到其他字段,可以使用聚合函数.
1.将筛选平均年龄大于 35 的分组
select depart_id ,avg(age) from employee group by depart_id having avg(age)>35 ;
/*
+-----------+----------+
| depart_id | avg(age) |
+-----------+----------+
| 1 | 45.2500 |
+-----------+----------+
1 row in set (0.00 sec) */
// 利用 as 语法更改字段头
select depart_id,avg(age) as pj from employee group by depart_id having pj > 35;
/*
+-----------+---------+
| depart_id | pj |
+-----------+---------+
| 1 | 45.2500 |
+-----------+---------+
1 row in set (0.00 sec)
3. order by排序5
单行排序
默认是升序排列,asc(升序) desc(降序)
order by 字段名 asc(升序) desc(降序)
按单列排序
SELECT * from employee order BY salary;
SELECT * from employee ORDER BY salary ASC;
SELECT * from employee ORDER BY salary DESC;
按多列排序:先按照age排序,如果年纪相同,则按照薪资排序
SELECT * from employee ORDER BY age, salary DESC;
多行排序
根据前后的优先级进行排序
select * from employee order by age desc,id desc;
先对age进行降序, 如果有相同的age, 则根据id进行降序排列
/*
+----+----------+--------+-----+------------+----------------------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+----------+--------+-----+------------+----------------------+--------------+------------+--------+-----------+
| 3 | sean | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
| 2 | jason | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 4 | tank | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 |
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 |
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
....
4. limit分页
限制查询的记录数
语法:
limit 行数据索引,取多少条
// 行数据索引从0开始计算
取出表中的前5条数据
select * from employee limit 0,5;
/*
+----+----------+------+-----+------------+----------------------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+----------+------+-----+------------+----------------------+--------------+------------+--------+-----------+
| 1 | nick | male | 18 | 2017-03-01 | 老男孩驻上海虹桥最帅 | NULL | 7300.33 | 401 | 1 |
| 2 | jason | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 3 | sean | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
| 4 | tank | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 5 | oscar | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 |
+----+----------+------+-----+------------+----------------------+--------------+------------+--------+-----------+
5 rows in set (0.00 sec)
取出 11-15 的数据
select * from employee limit 10,5;
/*
+----+----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 |
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 |
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
+----+----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
5 rows in set (0.00 sec)
5.总结
使用的顺序***************************
select * from 表名 where 条件 group by 条件 having 条件 order by 条件 limit 条件;
where > group by > having > order by > limit
UNIQUE
创建唯一索引的目的不是为了提高访问速度,而只是为了避免数据出现重复。唯一索引可以有多个但索引列的值必须唯一,索引列的值允许有空值。如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该使用关键字UNIQUE
多表操作
*****************************
外键
外键是指引用另外一个表中的一列或多列数据,被引用的列应该具有主键约束或者唯一性约束。外键用来建立和加强两个表数据之间的连接
使用的原因:
1. 减少占用的空间
2. 只需要修改外键一次,对应表中的数据就会相应的修改
关联关系
实际开发中,需要根据实体的内容设计数据表,实体间会有各种关联关系,所以根据试题设计的数据表也存在各种关联关系,mysql中数据表的关联关系有三种;
多对一
多对一是数据表中最常见的
像是:部门与员工之间的关系,一个部门可以有多个员工,一个员工不能属于多个部门.
也就是说,部门表中的一行可在员工表有多个匹配行,员工表在部门表却只能有一个
表之间的关系是由外键建立的,多对一的表关系中,应该将外键建立在多的一方.
注意:可以在多的一方设置外键保存另外一方的主键。
使用方法
constraint 随意的外键名 foreign key (想要外键约束的字段) references 引用约束的表(约束的字段)
例子
// 创建部门表
create table department(
id int auto_increment primary key,
name varchar(32) not null default''
)charset utf8;
// 添加数据
insert into department (name) values ('研发部');
insert into department (name) values ('运维部');
insert into department (name) values ('前台部');
insert into department (name) values ('小卖部');
// 创建用户信息表
create table userinfo(
id int auto_increment primary key,
name varchar(32) not null default '',
depart_id int not null default 1,
// 给信息表添加外键,对应部门表
constraint fk foreign key (depart_id) references department(id)
)charset utf8;
// 插入数据
insert into userinfo(name,depart_id) values('dasha',1),('ersha',2),('sansha',1),('sisha',3);
/* mysql> select * from department;
+----+--------+
| id | name |
+----+--------+
| 1 | 研发部 |
| 2 | 运维部 |
| 3 | 前台部 |
| 4 | 小卖部 |
+----+--------+
4 rows in set (0.00 sec)
*/
/* mysql> select * from userinfo;
+----+--------+-----------+
| id | name | depart_id |
+----+--------+-----------+
| 1 | dasha | 1 |
| 2 | ersha | 2 |
| 3 | sansha | 1 |
| 4 | sisha | 3 |
+----+--------+-----------+
4 rows in set (0.00 sec)
*/
多对多
比如学生与课程的关系,一个学生可以有多个课程,一门课程也可以供多个学生选择.
即学生表的一行在课程表中可以有许多匹配行,课程表的一行在学生表中也有许多匹配行.
通常情况下,为是实现这种关系,需要定义一张中间表,称为连接表,该表会存在两个外键,分别参照课程表与学生表
需要注意的是: 连接表的两个外键都是可以重复的,但是两个外键之间的关系是不能重复的,所以这两个外键又是连接表的联合主键
例子
// 创建男生表
create table boy (
id int auto_increment primary key,
b_name varchar(32) not null default ''
)charset utf8;
// 添加数据
insert into boy (b_name) values ('dasha'),('ersha'),('sansha');
// 创建女生表
create table girl (
id int auto_increment primary key,
g_name varchar(32) not null default ''
)charset utf8;
// 添加数据
insert into girl (g_name) values ('xi'),('shui'),('xxx');
// 创建中间表/连接表
create table boygirl(
id int auto_increment primary key,
b_id int not null default 1,
g_id int not null default 1,
// 给boy_girl表中的g_id设置外键,指向boy(id)
constraint kk foreign key (b_id) references boy(id),
// 给boy_girl表中的b_id设置外键,指向boy(id)
constraint kf foreign key (g_id) references girl(id)
)charset utf8;
// 添加数据
insert into boygirl (b_id,g_id) values (1,2),(2,3),(1,3);
/* mysql> select * from boy;
+----+--------+
| id | b_name |
+----+--------+
| 1 | dasha |
| 2 | ersha |
| 3 | sansha |
+----+--------+
3 rows in set (0.00 sec)
*/
/* mysql> select * from girl;
+----+--------+
| id | g_name |
+----+--------+
| 1 | xi |
| 2 | shui |
| 3 | xxx |
+----+--------+
3 rows in set (0.00 sec)
*/
/* mysql> select * from boygirl;
+----+------+------+
| id | b_id | g_id |
+----+------+------+
| 1 | 1 | 2 |
| 2 | 2 | 3 |
| 3 | 1 | 3 |
+----+------+------+
3 rows in set (0.00 sec)
*/
一对一
例如:人与身份证之间的关系就是一对一的关系,一人对应一张身份证,一张身份证只对应一人.
首先区分主从关系,从表需要主表的存在才有意义,身份证为从表.
应用:
1. 分割具有很多列的表
2. 由于安全原因隔离表的一部分
3. 保存临时的数据,可以直接删除该表
// 创建人物表
create table user (
id int auto_increment primary key,
name varchar(32) not null default ''
)charset utf8;
// 插入数据
insert into user (name) values('zhu'),('gou'),('she');
//创建信息表
create table priv(
id int auto_increment primary key,
salary int not null default 0,
userid int not null default 1
// 设置外键,添加人物表的id
constraint pr foreign key (userid) references user(id),
unique(userid)
);
// 添加信息
insert into priv (salary,uid) values (2000,1),(2800,2),(5000,3);
/*
mysql> select * from priv;
+----+--------+-----+
| id | salary | uid |
+----+--------+-----+
| 1 | 2000 | 1 |
| 2 | 2800 | 2 |
| 3 | 5000 | 3 |
+----+--------+-----+
3 rows in set (0.00 sec)
多表联查
通过外键连接多个表,使用连接查询输出表中的内容
创建两个表:
CREATE TABLE `a_table` (
`a_id` int(11) DEFAULT NULL,
`a_name` varchar(10) DEFAULT NULL,
`a_part` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf
CREATE TABLE `b_table` (
`b_id` int(11) DEFAULT NULL,
`b_name` varchar(10) DEFAULT NULL,
`b_part` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
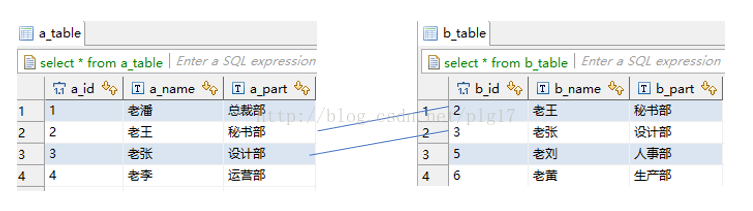
外连接
首先说明外连接不同于内连接的一个性质:外连接查询与表的顺序有关
创建两个表
// 创建表1 tt
create table tt (
id int auto_increment primary key,
name varchar(32) not null default ''
)charset utf8;
// 添加数据
insert into tt (name) values ('研发部'),('运维部'),('前台部'),('小卖部');
// 创建表2 ss 并给ss添加外键
create table ss(
id int auto_increment primary key,
name varchar(32) not null default '',
tt_id int not null default 0,
constraint ttss foreign key (tt_id) references tt(id)
) charset utf8;
// 添加数据
insert into ss (name,tt_id) values ('小明',1),('小红',2),('小军',3),('小白',4),('小丽',1),('小胡',2);
// 查询tt
mysql> select * from tt;
+----+--------+
| id | name |
+----+--------+
| 1 | 研发部 |
| 2 | 运维部 |
| 3 | 前台部 |
| 4 | 小卖部 |
+----+--------+
4 rows in set (0.00 sec)
// 查询ss
mysql> select * from ss;
+----+------+-------+
| id | name | tt_id |
+----+------+-------+
| 1 | 小明 | 1 |
| 2 | 小红 | 2 |
| 3 | 小军 | 3 |
| 4 | 小白 | 4 |
| 5 | 小丽 | 1 |
| 6 | 小胡 | 2 |
+----+------+-------+
6 rows in set (0.00 sec)
1. 左连接left join on
left join on 接受左表的所有行,并用这些行与右表进行匹配
select * from 表a lift join 表b on 表a.字段 = 表b.字段;
执行结果
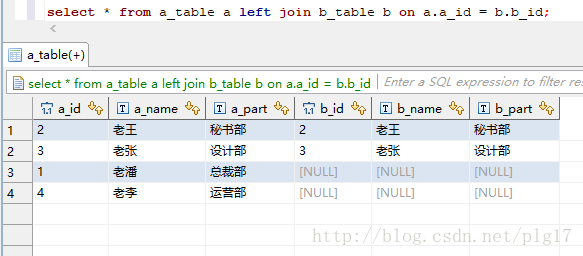
说明:
left join是 left outer join的简写 ,全称是 左外连接,外连接的一种
左连接,左表(a_table)的记录将会全部显示处理啊,而右表(b_table)只会显示符合搜索条件的记录,右表记录不足的地方均为null.
代码
select ss.name,tt.name from ss left join tt on ss.tt_id = tt.id;
/*
+------+--------+
| name | name |
+------+--------+
| 小明 | 研发部 |
| 小丽 | 研发部 |
| 小红 | 运维部 |
| 小胡 | 运维部 |
| 小军 | 前台部 |
| 小白 | 小卖部 |
+------+--------+
6 rows in set (0.00 sec)
2. 右连接right jion on
与左外连接完全相同,只不过是用右表来评价左表 ,左表记录不足的地方均为NULL
select * from 表a right join 表b on 表a.字段 = 表b.字段 ;
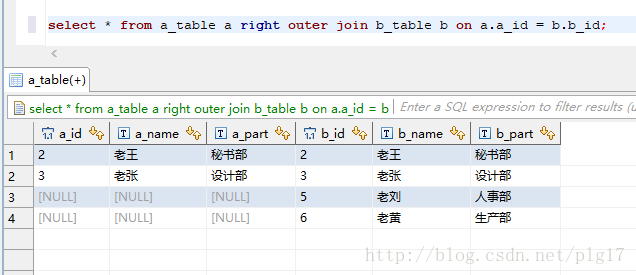
说明
right join是right outer join的简写,它的全称是右外连接,是外连接中的一种
左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
select ss.name,tt.name from ss right join tt on ss.tt_id = tt.id;
/*
+------+--------+
| name | name |
+------+--------+
| 小明 | 研发部 |
| 小丽 | 研发部 |
| 小红 | 运维部 |
| 小胡 | 运维部 |
| 小军 | 前台部 |
| 小白 | 小卖部 |
+------+--------+
6 rows in set (0.00 sec)
可三表联查
后面加上left 或right即可.
3. 全连接
全外连接
MySQL目前不支持此种方式,可以用其他方式替代解决。
内连接
首先说明内连接的一个重要性质:内连接查询结果与表的顺序无关
关键字: inner join on
语句:
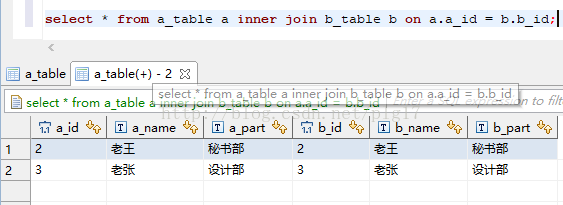
select * from a_table a inter join b_table on a.a_id = b.b_id;
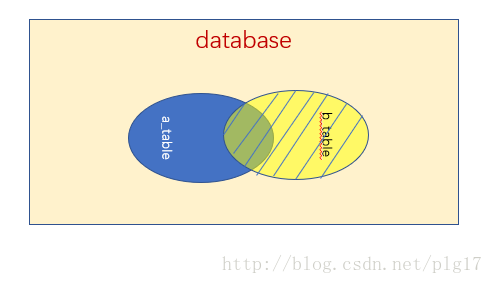
说明: 组合两个表中的数据,返回关联字段相符的记录,也就是返回两个表的交集部分(阴影)

代码
select * from ss inner join tt on ss.tt_id = tt.id;
/*
+----+------+-------+----+--------+
| id | name | tt_id | id | name |
+----+------+-------+----+--------+
| 1 | 小明 | 1 | 1 | 研发部 |
| 5 | 小丽 | 1 | 1 | 研发部 |
| 2 | 小红 | 2 | 2 | 运维部 |
| 6 | 小胡 | 2 | 2 | 运维部 |
| 3 | 小军 | 3 | 3 | 前台部 |
| 4 | 小白 | 4 | 4 | 小卖部 |
+----+------+-------+----+--------+
6 rows in set (0.00 sec)