Query Simplification: Graceful Degradation for Join-Order Optimization
这篇的related work可以参考,列的比较全面,
Query图分为下面几种,

Graph Simplification算法,
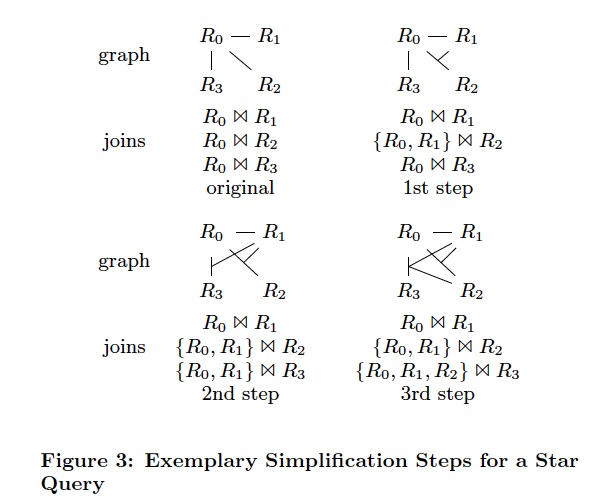

Heuristic
Optimization of Large Join Queries: Combining Heuristic and Combinatorial Techniques
这篇文章的主要观点,结合Combinatorial和Heuristic
Combinatorial意思是组合
组合优化问题就是,在状态空间中寻找一个最优的状态,状态的cost由cost function来决定
Combinatorial优化算法主要分为两种,
Iterative算法,这里主要是指repeat,不断随机重试,以找到更优解

退火算法,

Heuristic算法,
首先,Augmentation Heuristic
初始只有第一张关系表,
然后一张张往上加,加哪一个取决于chooseNext函数

下面给出一些可以用作chooseNext的指标,论文说实验结果是3的效果最好

KBZ Heuristic
算法分为三个部分,
R,给定一个rooted tree,给出optimal join ordering
T,给定一个join tree,遍历所有的root,用R找出每个rooted tree的optimal
G,给定一个join graph,可能cyclic,找出一个spanning tree(生成树),调用T

Local Improvement
分而治之,表数太多的时候,穷举的代价很高,但是切分成小的cluster,就会简单许多
同样这样也无法得到最优解,cluster可以重合

最后如果把两个技术结合起来?


II和SA就是两种基本的Combinatorial方法,
SAA,SAK分别把augmentation和KBZ两种Heuristic方法用于SA,用于产生一个较优的initial state
IAI,IKI,用Heuristic的方法产生每一轮迭代的initial state
IAL,加入local improvement
AGI,KBI,先用Heuristic产生state,再用Iterative去优化
A New Heuristic for Optimizing Large Queries
查询优化的目的是避免worst plans,而不是找到best plan,在这样的假设下,启发式算法可能会达到比较好的效果
当前基于combinatorial优化技术(比如iterative或退火)的cost-based searching,已经取得了一定的效果,但是当前的方法并没有利用queries中inherent的semantic information
所以基本的思路就是,在当前cost-based searching的基础上利用semantic information,从而提出Goo算法,Greedy Operator Ordering
这是一种,Greedy的bottom up算法
Node关键属性是Size,Edge关键属性是Selectivity

Goo的目的是逐渐合并各个node,
合并的标准是,每次都是找产生中间结果最小的edge进行合并
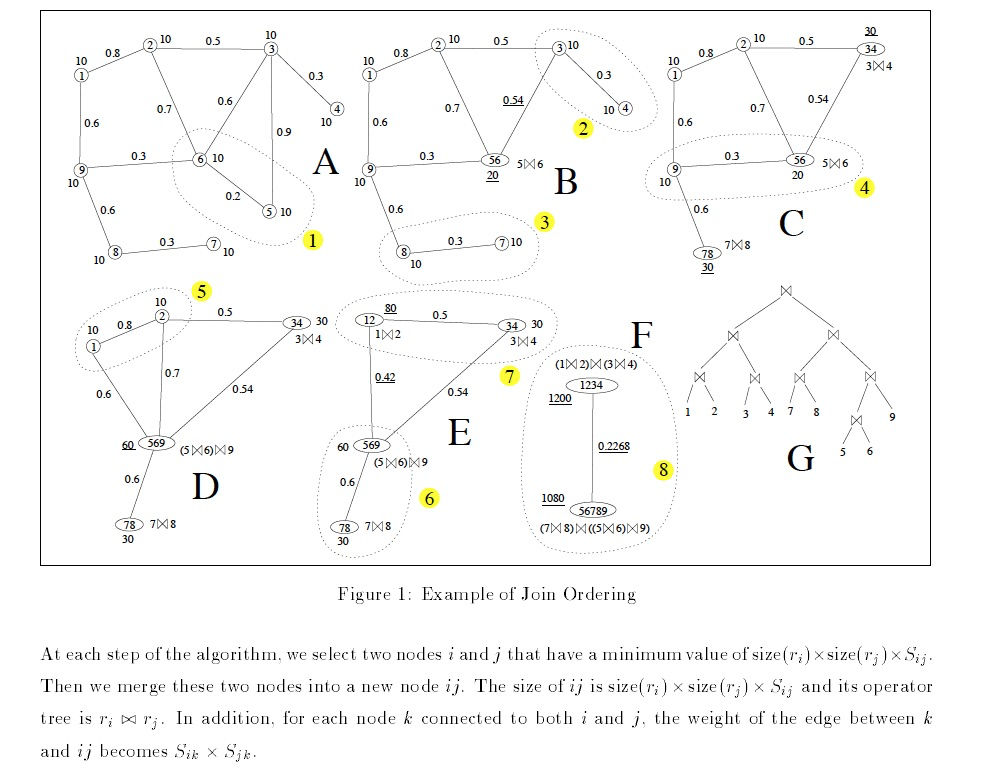
很明显,Goo产生的肯定不是最优解
一般的思路都是,基于启发式的结果,进行进一步的调整和优化,找到更优解,
比如,增加一组rules,bottom up的试图apply这些rules得到更好的结果

Polynomial Heuristics for Query Optimization
One line of work adapts randomized techniques and combinatorial heuristics to address this problem.
These techniques consider the space of plans as points in a high-dimensional space, that can be “traversed” via transformations (e.g., join commutativity and
associativity).
Reference [13] surveys different such strategies, including iterative improvement, simulated annealing, and genetic algorithms.
These techniques can be seen as heuristic variations of transformation-based exhaustive enumeration algorithms.
Another line of work implements heuristic variations of dynamic programming. These approaches include reference [14] (which performs dynamic programming for a
subset of tables, picks the best k-table join, replaces it with a new “virtual” table, and repeats the procedure until all tables are part of the final plan),
reference [15] (which simplifies an initial join graph by disallowing non-promising join edges and then exhaustively searches the resulting, simpler problem using [8]), and references [16], [17] (which greedily build join trees one table at a time).
本文首先给出一个分类,比较新颖,
启发式是优化的基本技术,分为对于Transformation-based技术的启发式优化,和动态规划的启发式优化
其中Heuristic DP算法都是基于graph的,可以采用iterative的方式,根据cost等信息降低搜索空间等,或者用Greedy算法
但是文中说除了greedy的方案,其他的性能都太差
所以文中给出一个通用的Greedy算法框架,ERM

P包含所有Plan,目的就是不断的merge plan,最终只剩下一个plan,这个就是Greedy算法的目的,参考GOO
算法叫ERM,分为3个阶段,
首先要找出可以用于merge的所有plan,关键是Valid函数,不同要求下,valid定义不一样
边上的例子,给出linear tree和bushy tree的差异


第二个阶段是Ranking,即Maximizes函数,
如果挑出合并哪两个plan是最优的,
有如下函数可以选择,本文提出MinSize,考虑tuples本身的长度,效果更好些
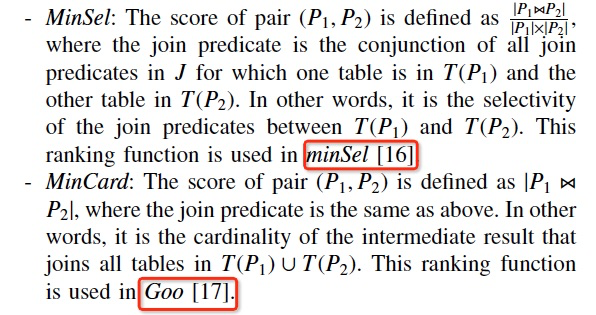

第三个阶段Merging,即merge函数
简单的直接用join链接两个plan即可

但是merge可以更加flexible,
文中用Swith-HJ,考虑hashjoin的join顺序,Swith-Idx,考虑index所带来的影响
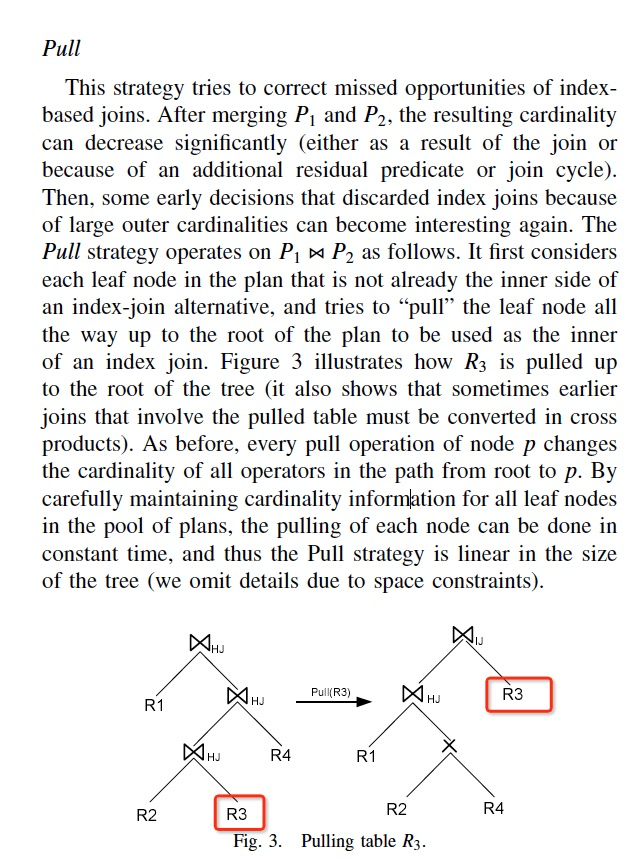
还提出Push,Pull两种方式,
Push,
过程简单的看下图,要把P2 push到P1的R3上,而不是直接的join链接
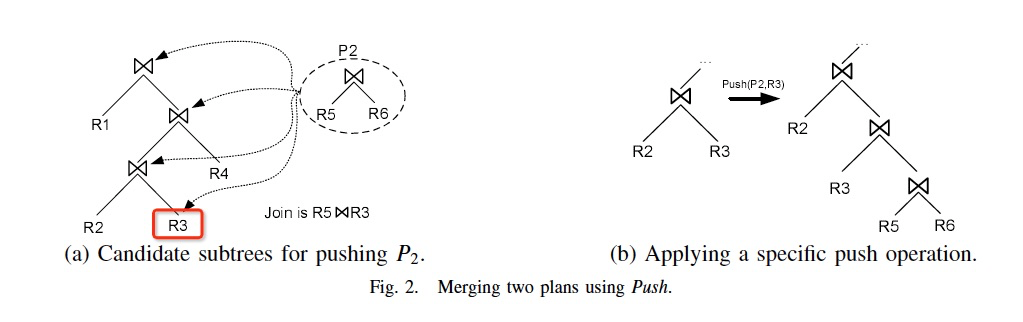
Push的好处,修正Greedy的局部限制

同时还有Pull,
以及把Push和Pull加入算法的BSizePP,

后续文中还讨论了,Beyond Join Reordering,包含Group-by,Semi-join,Outer-join等
Iterative
Iterative Dynamic Programming: A New Class of Query Optimization Algorithms
本文提出的IDP算法,算是DP的Heuristic优化,

先看下标准的DP和Greedy算法是怎么样的


看下两者结合的算法,
IDP1
如果在有限的资源,内存,有限的时间里面,去做DP
比如当前的内存只够做k-way的,做到k+1 way就crash了
给出的方法是,做到k-way后,用Greedy算法直接挑一个最优的plan,继续,其他的都不考虑
算法中,红色部分是DP,蓝色部分是Greedy,这里注意optPlan仅仅保留P,最优的plan


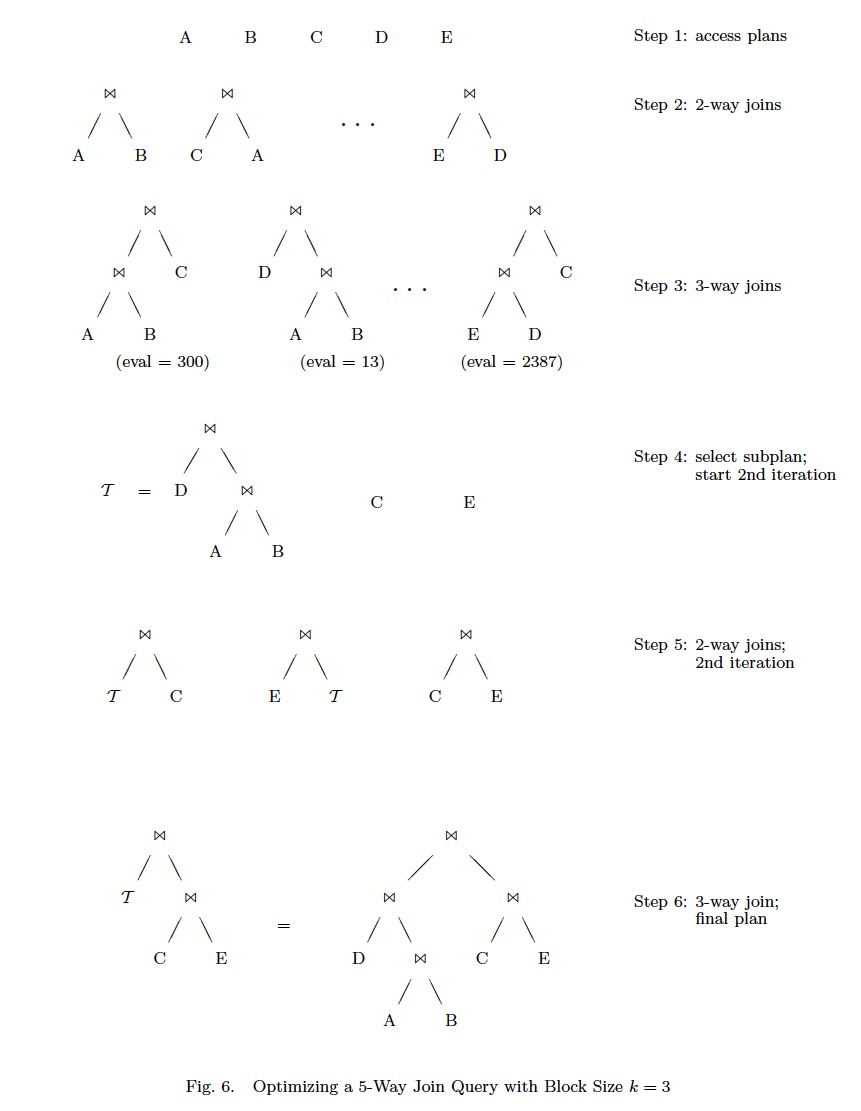
实际看个例子,k=3
IDP2
先Greedy后DP的算法,

算法如下,
先用Greedy算法找出K个左右tables的block,再用DP优化这个block
然后把block放回todo里面,继续这个流程,直到最终得到一个plan

这里,算法存在变体,
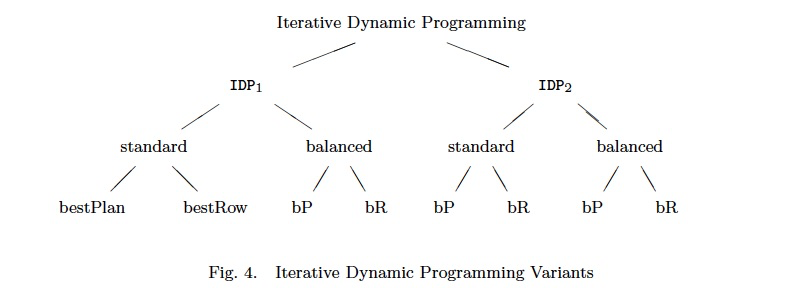
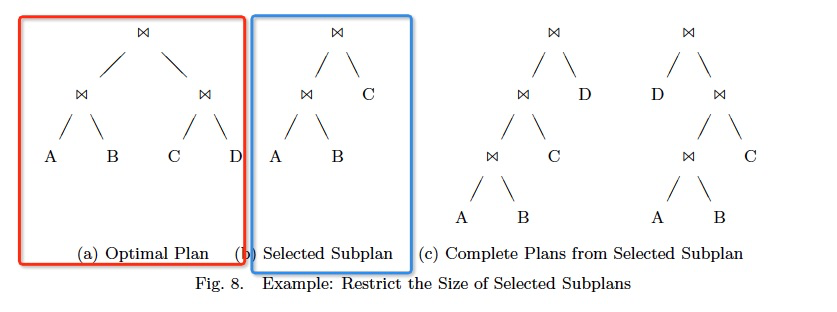
standard和balanced,是否限制k的大小,k太大会影响最终plan的优化效果,
比如,对于下面的例子,最优plan是a
但是如果k=3,那么选中的子plan是b,那么最终只会产生右边的两个plan
如果k=2,就能生成最优的plan
bestPlan和bestRow,是否仅仅保留一个最优的plan
