AMP Lab的论文
对于数据库的核心问题,如何让查询变的更快,当需要查询的数据越来越多的时候

这段写的还是很清晰的,两个思路
读的更快,比如cache,并行化,数据压缩
读的更少, 比如列存,sampling获取近似,还有本文的主题data skipping

传统的data skipping,基于partition pruning,这样粒度比较粗;
最近的系统支持,基于block的skipping,block要小的多,
DB2的BLU的block,只有1000 tuple;PowerDrill的Block有50000 tuples;Shark基于HDFS block,128M;
但是之前的block都是依赖range partition来划分block,这是很直觉的方式
本文说range partition有一些问题,
会有数据和负载的skew;无法给不同的column不同的划分;无法capture column之间的相关性

本文提出一种基于负载统计的,细粒度的,平衡size的blocks

实际看个例子是如何做partition的,对象就是图中的日志表,
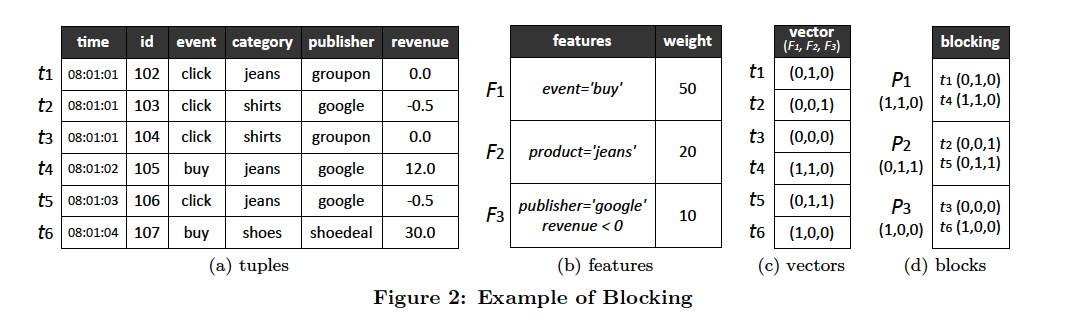
首先从真实的查询负载中,提取出一组features,这里的feature指的是filter

第二步,根据选择的features把tuple进行向量化

第三步,很关键,如何去partition,
这里说,尽量把不满足相同features的tuple划分进同一个block,
因为你要skip,所以如果某个block中的所有tuples都不满足某个feature,那么查询如果包含改feature,就可以简单的skip掉

下面就是一些实现细节,
首先如何根据负载提取Filter,
关键是下面两个指标,
同时这也是对于场景的假设,如果不满足,那么这个方法就是无效的

这里具体的抽取算法就不说了,感兴趣的看原文
然后就是Blocking Partition的流程,比较容易理解
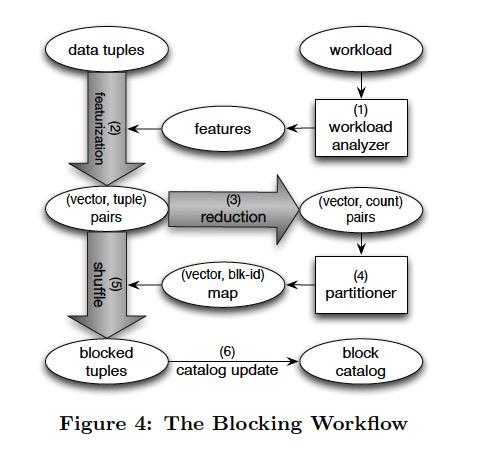
具体的划分算法,这里也不展开了,具体参考原文
然后这篇论文的Related Work写的不错,
首先,之前的数据库partition,都是基于Range或hash,而本文提出的一种独特的细粒度划分方式,虽然17也提出一种基于workload的细粒度划分,但目的不同,他是为了避免跨机器的事务

对于Skip技术,
传统的Oracle或PG,都是基于Partition Pruning
类似28,34,BrightHouse,会使用SMA,来对block进行pruning,
对于完全不相干,C1,直接可以过滤掉
C2,全相关,那需要scan
关键是C3,部分相关,这个很复杂,如何判断是否要过滤,SMA是否可以answer查询
所以大部分系统不会区分C2和C3,这篇Paper也没有区分

和物化视图做比较,因为都需要pre-computation
物化视图,要预算,但不会做partition;本文做预算的目的主要是做partition,而不是记录预算的聚合值,本身目的不一样
所以使用的空间大小明显不一样,物化视图的空间占用和成本要大很多
而且本文在抽取feature的时候,是同时看column和value,这个是不同的,一般都不会这么做,因为这样的限制太强,有利有弊
