Calcite Version:1.26.0
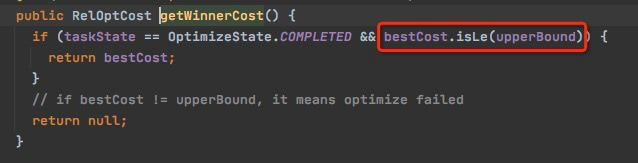
初始的cost

加入RelNode的时候,需要更新subset的cost
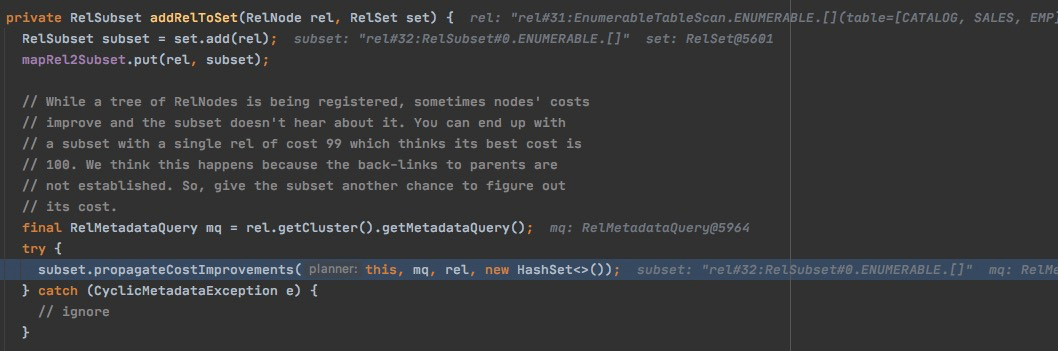
RelSubset
找出traits想匹配的subsets,
然后逐一更新cost,
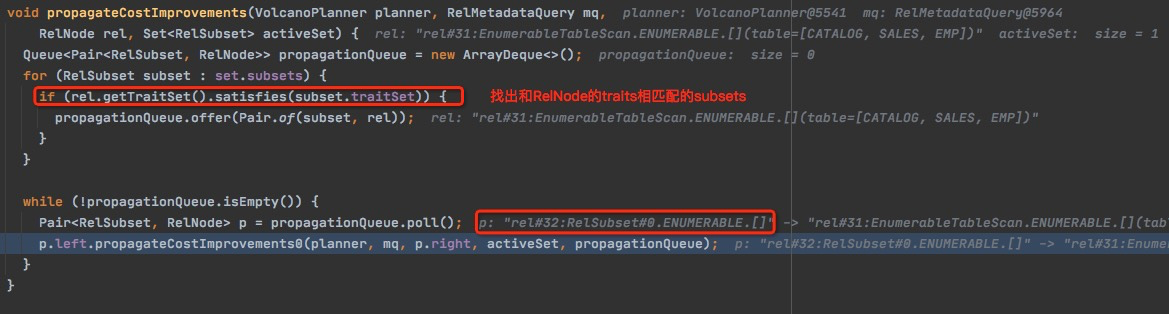
propagateCostImprovements0

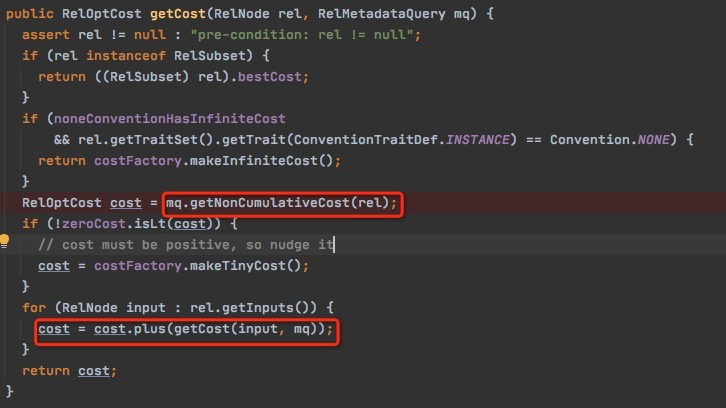
getCost
叠加所有input的cost,所以input的cost是inf,按叠加后也是inf
这里注意,Convention为None的时候,cost就是inf,所以只有当RelNode转成Enumerable后,才有cost
所以只有TopDown到叶子节点,才会生成并更新subset的bestcost,因为没有input的cost是inf了
nonCumulativeCostHandler这里是codegen产生的,

RelMetadataProvider
RelOptCluster-> setMetadataProvider(DefaultRelMetadataProvider.INSTANCE);
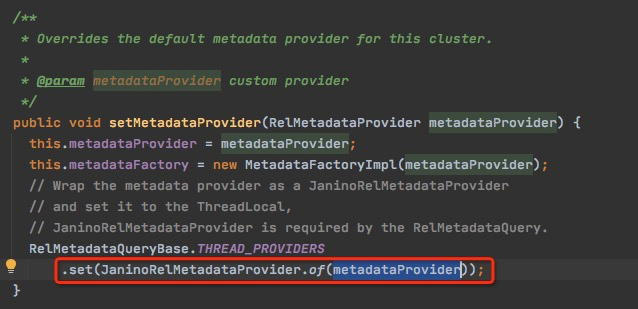
这步就是在初始化的时候将JaninoRelMetadataProvider的provider,设置成DefaultRelMetadataProvider.INSTANCE

DefaultRelMetadataProvider
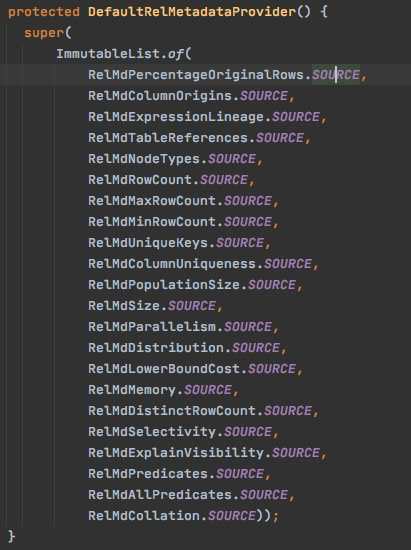
其中,RelMdPercentageOriginalRows
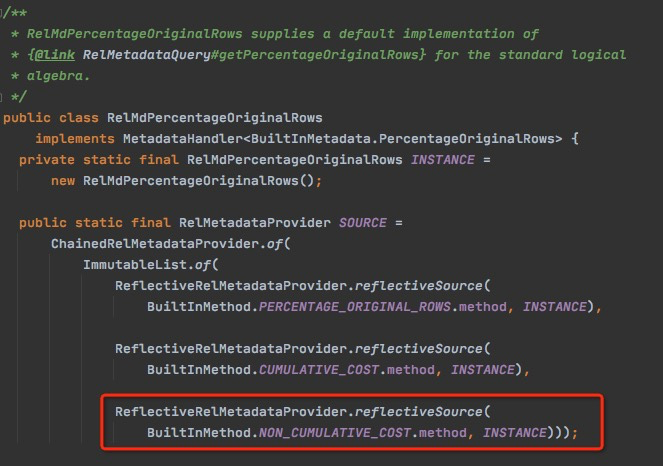
这里包含了对于getNonCumulativeCost的实现,

下面看下如果Codegen的,
前面的revise,调用到create,
创建Key,包含Def和provider
Def,获取哪个method的handle
provide,包含所有method和实现类的对应关系
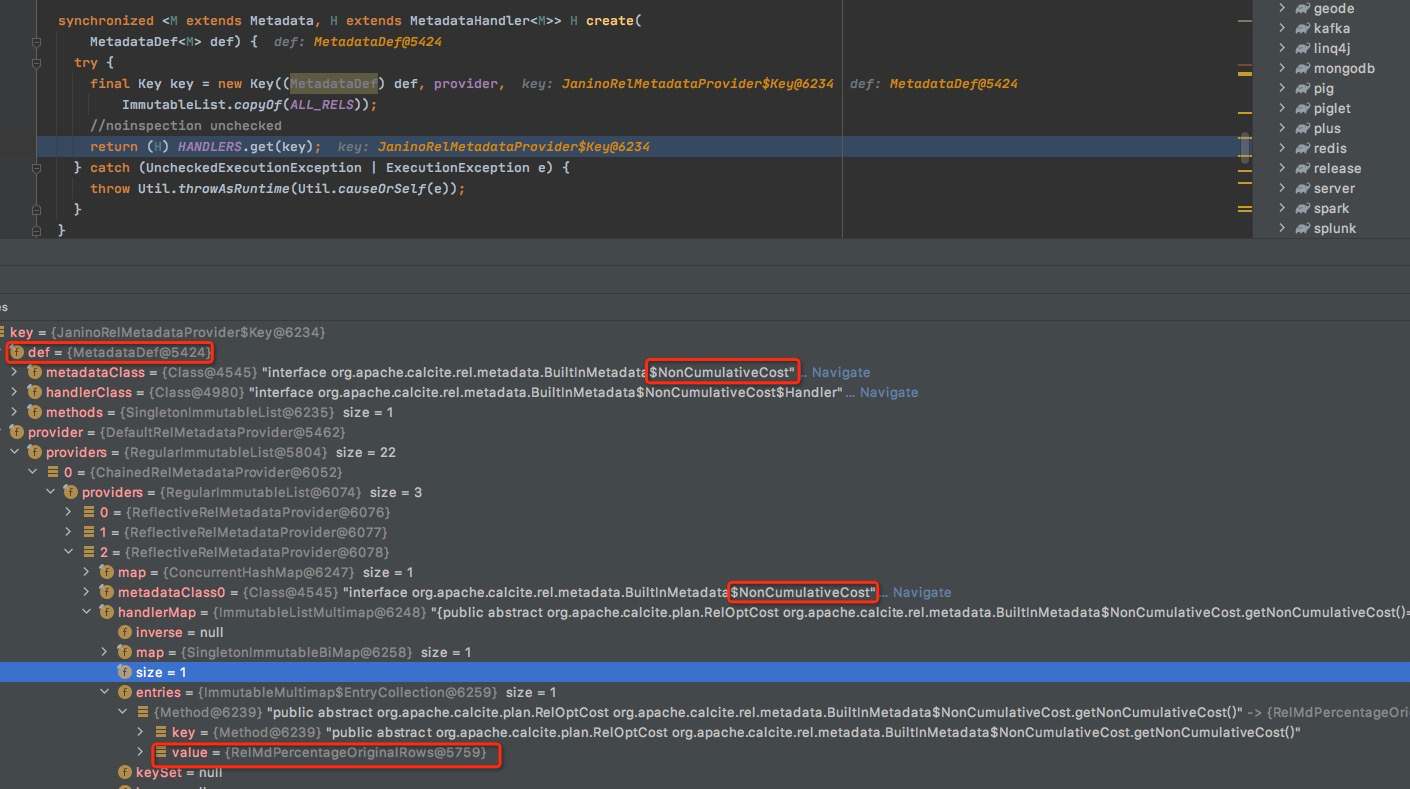
Handles是个cache,

cache中没有,调用load3创建,
前面生成handle的name,和相应的provider
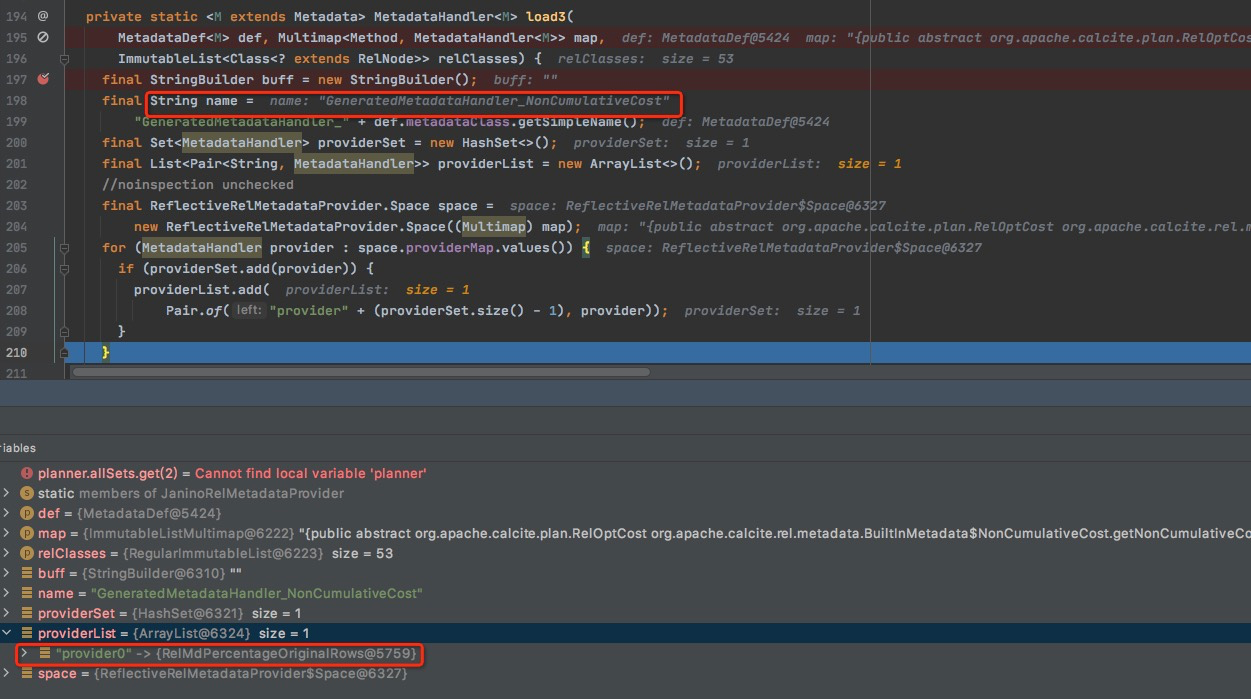
最终通过,字符串拼接,codegen出来的代码主要是,
搞了这么多,其实就是为了为不同的RelNode生成不同的处理函数,避免手写switch case。
private org.apache.calcite.plan.RelOptCost getNonCumulativeCost_( org.apache.calcite.rel.RelNode r, org.apache.calcite.rel.metadata.RelMetadataQuery mq) { switch (relClasses.indexOf(r.getClass())) { default: return provider0.getNonCumulativeCost((org.apache.calcite.rel.RelNode) r, mq); case 3: return getNonCumulativeCost(((org.apache.calcite.plan.hep.HepRelVertex) r).getCurrentRel(), mq); case -1: throw new org.apache.calcite.rel.metadata.JaninoRelMetadataProvider$NoHandler(r.getClass()); } }
看下这个的codegen,更明显一些,为不同的重载函数,
private java.lang.Double getRowCount_( org.apache.calcite.rel.RelNode r, org.apache.calcite.rel.metadata.RelMetadataQuery mq) { switch (relClasses.indexOf(r.getClass())) { default: return provider0.getRowCount((org.apache.calcite.rel.RelNode) r, mq); case 2: return provider0.getRowCount((org.apache.calcite.plan.volcano.RelSubset) r, mq); case 3: return getRowCount(((org.apache.calcite.plan.hep.HepRelVertex) r).getCurrentRel(), mq); case 4: case 5: case 9: case 17: case 21: case 22: case 23: case 29: case 33: case 41: case 45: case 46: case 47: return provider0.getRowCount((org.apache.calcite.rel.SingleRel) r, mq); case 6: case 24: case 30: return provider0.getRowCount((org.apache.calcite.rel.core.Aggregate) r, mq); case 7: case 31: return provider0.getRowCount((org.apache.calcite.rel.core.Calc) r, mq); case 8: case 32: return provider0.getRowCount((org.apache.calcite.rel.core.Correlate) r, mq); case 10: case 25: case 34: return provider0.getRowCount((org.apache.calcite.rel.core.Filter) r, mq); case 11: case 35: return provider0.getRowCount((org.apache.calcite.rel.core.Intersect) r, mq); case 12: case 27: case 36: case 48: return provider0.getRowCount((org.apache.calcite.rel.core.Join) r, mq); case 13: case 37: return provider0.getRowCount((org.apache.calcite.rel.core.Minus) r, mq); case 14: case 26: case 38: return provider0.getRowCount((org.apache.calcite.rel.core.Project) r, mq); case 15: case 39: return provider0.getRowCount((org.apache.calcite.rel.core.Sort) r, mq); case 18: case 28: case 42: return provider0.getRowCount((org.apache.calcite.rel.core.TableScan) r, mq); case 19: case 43: return provider0.getRowCount((org.apache.calcite.rel.core.Union) r, mq); case 20: case 44: return provider0.getRowCount((org.apache.calcite.rel.core.Values) r, mq); case -1: throw new org.apache.calcite.rel.metadata.JaninoRelMetadataProvider$NoHandler(r.getClass()); } }
computeSelfCost
getNonCumulativeCost最终还是调用到computeSelfCost
所以cost,取决于不同的RelNode的computeSelfCost实现
这里注意,AbstractConverter的cost也是inf

比如对于Filter,computeSelfCost

getRowCount又是要codegen,调用到RelMDRowCount,


propagateCostImprovements0
cost传播的过程,
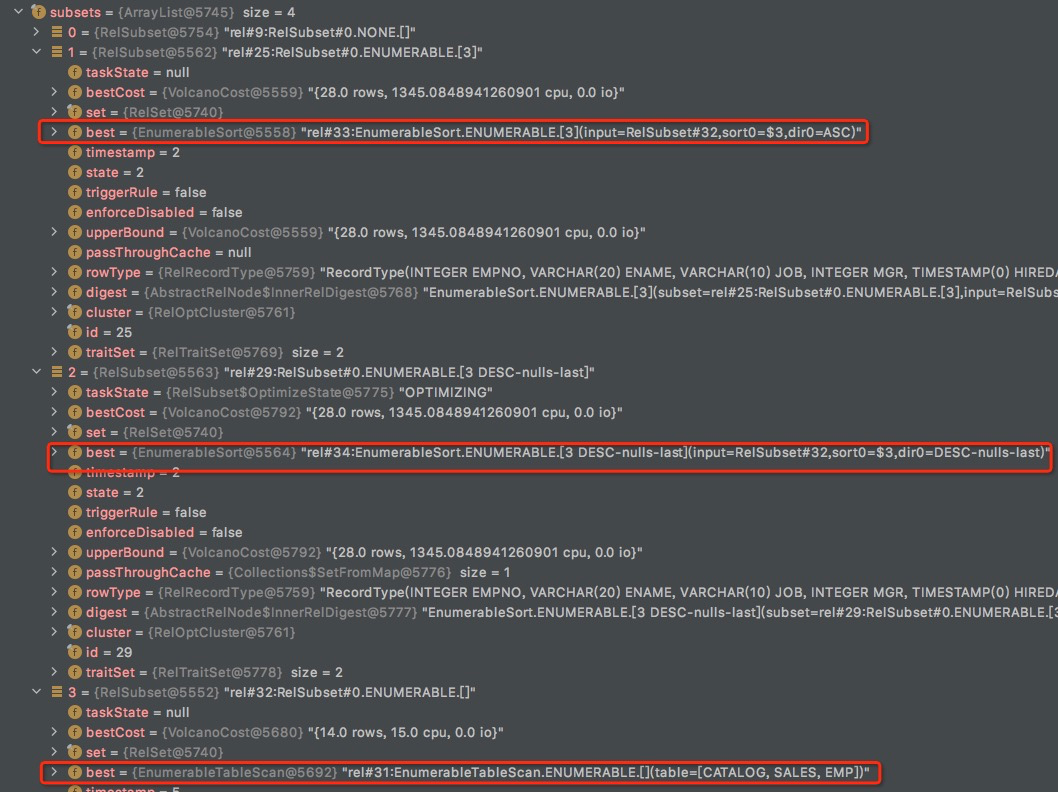
rel#31:EnumerableTableScan.ENUMERABLE.[](table=[CATALOG, SALES, EMP])的subset是,rel#32:RelSubset#0.ENUMERABLE.[]
getParents的逻辑,是找parents里面以rel#32为input的,如果不是以rel#32为input,也没有理由propagate
对于每个parent,取所在RelSet的所有subsets,和parent的traits比较,相符合的放入队列
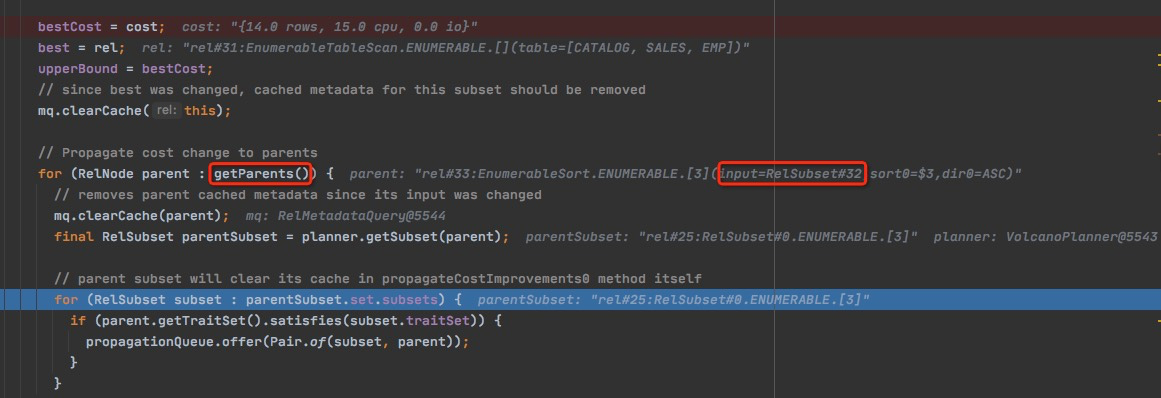
对于parent,不光需要propagate他的subset,同一个set中traits符合的都需要propagate
这个理论上也不会有一样的subset,所以看着是废话,
但是这里satisfies的逻辑,不是完全一样,只需要startwith就行,
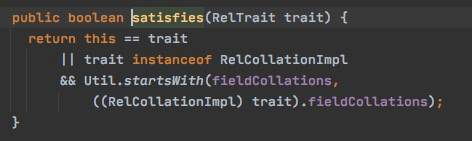
所以对于,rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last],rel#32:RelSubset#0.ENUMERABLE.[]也是satisfies的
所以这里结果是,有点出乎意料,

当前,rel#32:RelSubset#0.ENUMERABLE.[]完成propagate,继续
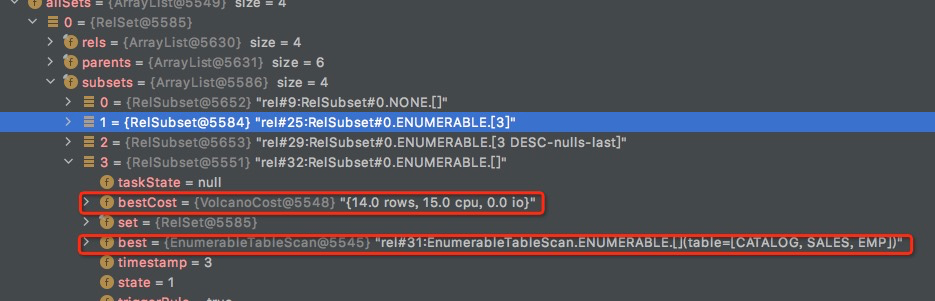
完成rel#29和rel#25的propagate,
注意上面33,34虽然也对32创建了propagate,但是都没有31cost低,所以32的best还是31
继续propagate,

直到root,完成propagate,
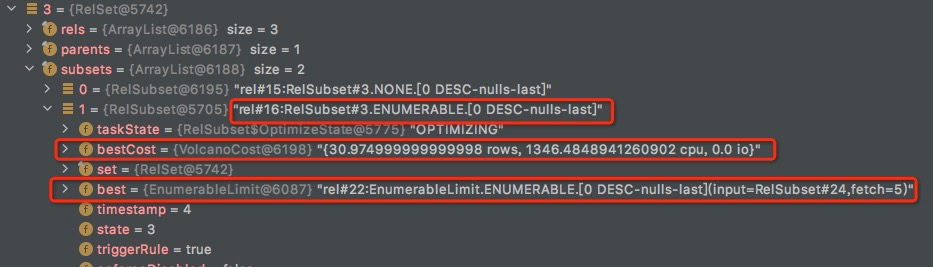
注意这里的Root是Subset,应该说经过一遍Register后,Plan上说有的节点都变成SubSet,为何要将RelNode变成SubSet?
因为在优化过程中,随着cost的变化,SubSet虽然不变,但是作为best的RelNode的是可以变的
为什么不用RelSet作为Root?RelSet只是个理论上的概念,现实中的数据都是带物理属性的,比如convention
这里有个设计比较麻烦?
找Subset所关联的RelNode是很麻烦的,要到Set.Rels里面去找和subset的traits匹配的所有RelNode
RelSet中所包含的Relnode,虽然在逻辑上是等价的,但是在物理上确实属于不同的subset
在物理属性上,Root的物理属性是最关键的,因为这个是最终输出给用户的,底下的所有的物理属性都是由这个决定的
所以在subset的state如果是Required,是个很强的约束,无论其他的subset是怎么样的traits,但最终还是要通过converter转换成满足required
所以这里的cost的propagate,就是沿着bottomup,一路更新cost和并试图去更新subset的best
这也是cost model,通过rule增加不同算子的目的,所以在addRelToSet后,都会试图去更新cost。
prune
subset.upperBound,表示这个group的cost的上限,初始化的时候是inf
当前产生bestcost的时候,会将bestcost赋值给upperBound,当有一个plan产生这样的cost,那么大于这个cost的plan都可以ignore了
onProduce也会被更新,
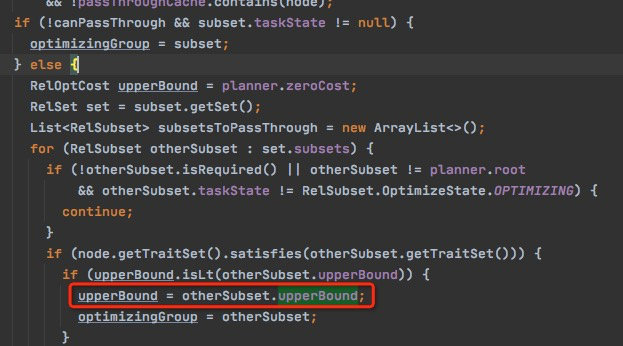
startOptimize时,也会调整upperBound的值,

OptimizeInput1
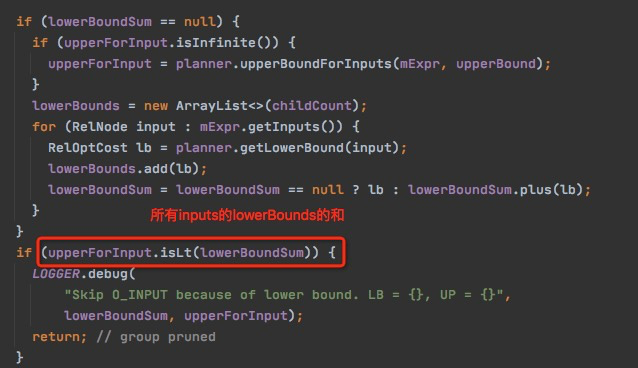
这里的mExpr表示待优化的算子,group表示mExpr属于的真正被优化的subset
这个mExpr是否有优化的价值,取决于当前subset.upperBound - cost(mExpr) 是否大于0
意思是如果mExpr本身的cost都已经大于subset.upperBound,那么该mExpr的input就没有继续优化的价值了
下面的例子中,
group.upperBound是rel#31:EnumerableTableScan.ENUMERABLE.[](table=[CATALOG, SALES, EMP])的bestcost
这里mExpr,rel#33:EnumerableSort.ENUMERABLE.[3](input=RelSubset#32,sort0=$3,dir0=ASC)本身的cost已经大于这个upperBound,所以没有比较继续OptimizeInput了

对于OptimizeInputs,prune的逻辑复杂些,
OptimizeGroup
首先,OptimizeGroup的参数upperBound,
在root首次调用OptimizeGroup的时候,传入的是inf
在OptimizeInput调用OptimizeGroup的时候,传入的是upperForInput,合乎情理

两种情况下,都会终止继续优化该group,一种是该group已经完成优化了;一种是在优化中,但是传入的upperForInput比现有的group.upperBound小