##一,lvs+keepalived 与HAproxy+keepalived
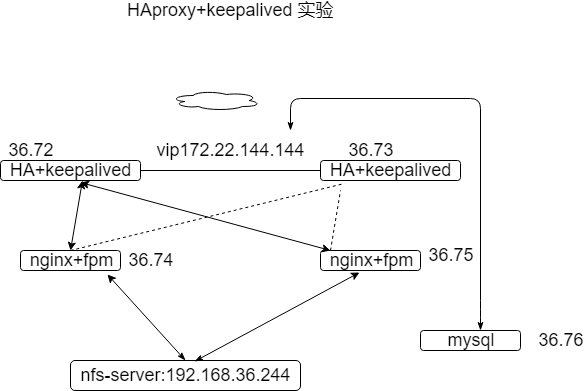
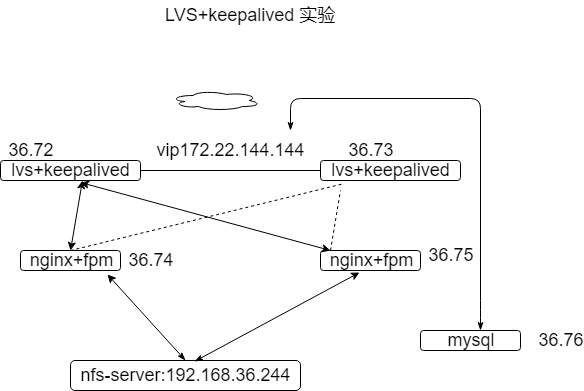
##二,实验操做:
nfs挂载:
nfs挂载,在后端创建用户,用户名及id与服务器nginx一致,并对导出的目录为该用户放开权限
/home/nfstestdir 192.168.222.0/24(rw,sync,all_squash,anonuid=1000,anongid=1000)
NFS权限参数配置 ro 只读访问 rw 读写访问 sync 所有数据在请求时写入共享 async NFS在写入数据前可以相应请求 secure NFS通过1024以下的安全TCP/IP端口发送 insecure NFS通过1024以上的端口发送 wdelay 如果多个用户要写入NFS目录,则归组写入(默认) no_wdelay 如果多个用户要写入NFS目录,则立即写入,当使用async时,无需此设置。 hide 在NFS共享目录中不共享其子目录 no_hide 共享NFS目录的子目录 subtree_check 如果共享/usr/bin之类的子目录时,强制NFS检查父目录的权限(默认) no_subtree_check 和上面相对,不检查父目录权限 all_squash 共享文件的UID和GID映射匿名用户anonymous,适合公用目录。 no_all_squash 保留共享文件的UID和GID(默认) root_squash root用户的所有请求映射成如anonymous用户一样的权限(默认) no_root_squas root用户具有根目录的完全管理访问权限 anonuid=xxx 指定NFS服务器/etc/passwd文件中匿名用户的UID anongid=xxx 指定NFS服务器/etc/passwd文件中匿名用户的GID
nginx +fpm
配置重点,php-fpm 配置启动用户为nginx ,这样php可以以相同的用户处理nfs上的文件
配置参考其他博文:https://www.cnblogs.com/g2thend/p/10884579.html
lvs+keepalived
keepalived 配置2个vip,一个走网站服务,一个走数据库。和图示不同,只是ip 有改动,注意所有ip 为同一局域网下
cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
2222@qq.com
}
notification_email_from admin@loaclhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id test73
vrrp_skip_check_adv_addr
# vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER
interface eth1
virtual_router_id 51
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1q2w3e4r
}
virtual_ipaddress {
# 192.168.36.179
192.168.36.179 dev eth1 label eth1:0
192.168.36.180 dev eth1 label eth1:1
}
}
virtual_server 192.168.36.180 3306 {
delay_loop 5
lb_algo rr #调度算法
lb_kind DR #集群类型NAT|DR|TUN
nat_mask 255.255.255.0 #子网掩码,可选项。
#persistence_timeout 50
protocol TCP #|UDP|SCTP
#sorry_server <IPADDR> <PORT>
real_server 192.168.36.76 3306 { #RS地址和端口
weight 1
TCP_CHECK {
connect_port 3306
connect_timeout 3
nb_get_retry 2
delay_before_retry 1
}
}
}
virtual_server 192.168.36.179 80 {
delay_loop 5
lb_algo rr #调度算法
lb_kind DR #集群类型NAT|DR|TUN
nat_mask 255.255.255.0 #子网掩码,可选项。
#persistence_timeout 50
protocol TCP #|UDP|SCTP
#sorry_server <IPADDR> <PORT>
real_server 192.168.36.74 80 { #RS地址和端口
weight 1
HTTP_GET {
url {
path /index.html
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
# connect_ip <IP ADDRESS>
# connect_port <PORT>
# bindto <IP ADDRESS>
# bind_port <PORT>
}
}
real_server 192.168.36.75 80 { #RS地址和端口
weight 1
HTTP_GET {
url {
path /index.html
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
# connect_ip <IP ADDRESS>
# connect_port <PORT>
# bindto <IP ADDRESS>
# bind_port <PORT>
}
}
}
###2,haproxy +keepalived
此时keepalived只是作为单点故障恢复,不做lvs负载均衡,所以不用配置vrrp_instance.
haproxy配置
cat /etc/haproxy/haproxy.cfg global maxconn 100000 chroot /usr/local/haproxy stats socket /var/lib/haproxy/haproxy.sock1 mode 600 level admin process 1 stats socket /var/lib/haproxy/haproxy.sock2 mode 600 level admin process 2 #仅限本机,根据传送的信号关闭进程等 uid 1990 #nobody /sbin/nologin gid 1990 #useradd -s /sbin/nologin haproxy 更换uid pid daemon nbproc 2 #启动进程数,与cpu保持一致 #nbthread 2 #指定每个haproxy进程开启的线程数,默认为每个进程一个线程 使用版本>v1.8 #看线程 pstree #ulimit-n 65535 #设置每进程所能够打开的最大文件描述符数目 #cpu-map 1 0 #第一个进程绑定到0核心上 #cpu-map 2 1 #cpu-map 3 2 #cpu-map 4 3 pidfile /run/haproxy.pid spread-checks 2 #后端server状态check,随机提前或延迟百分比时间,建议2-5(20%-50%)之间,默认0不延迟 log 127.0.0.1 local3 info #没有专门日志 vim /etc/rsyslog.conf #imudp 模块打开 接收端口打开 #local3.* /var/log/haproxy_xxxx.log systemctl restart rsyslog defaults option http-keep-alive #会话保持 option forwardfor #头部添加客户端源地址 ip透传 #后端服务器需要记录客户端真实ip, 需要在HTTP请求中添加”X-Forwarded-For”字段; #haproxy自身的健康检测机制访问后端服务器时, 不应将记录访问日志,可用except来排除127.0.0.0,即haproxy本身 #option httpclose #启http协议中服务器端关闭功能, 每个请求完毕后主动关闭http通道, 使得支持长连接,使得会话可以被重用,使得每一个日志记录都会被记录 #option dontlognull #如果产生了一个空连接,那这个空连接的日志将不会记录. maxconn 100000 #最大并发 mode http #全局默认转发模式,listen 区域可重写该变量 timeout connect 60s #TCP之前 (请求到后端,不能建立连接 timeout client 600s #空连接时间 timeout server 600s #tcp之后(请求已转发) 后端处理较长,建议设置久时间 timeout check 10s #心跳检测时间 #timeout http-request 10s #默认http请求超时时间 #timeout queue 1m #默认队列超时时间, 后端服务器在高负载时, 会将haproxy发来的请求放进一个队列中 #当与后端服务器的会话失败(服务器故障或其他原因)时, 把会话重新分发到其他健康的服务器上; 当故障服务器恢复时, 会话又被定向到已恢复的服务器上; #还可以用”retries”关键字来设定在判定会话失败时的尝试连接的次数 #option redispatch #retries 3 #当haproxy负载很高时, 自动结束掉当前队列处理比较久的链接. #option abortonclose #设置默认的负载均衡方式 #balance source #balnace leastconn listen stats mode http bind 0.0.0.0:9999 stats enable log global #option httplog #日志格式 #maxconn 10 #统计页面默认最大连接 #stats hide-version #隐藏统计页面上的haproxy版本信息 #stats refresh 30s #监控页面自动刷新时间 #stats realm LTC Haproxy #统计页面密码框提示文本 stats uri /haproxy-status stats auth haadmin:1q2w3e4r #手工启动/禁用后端服务器, 可通过web管理节点 stats admin if TRUE #设置haproxy错误页面 errorfile 400 /usr/local/haproxy/errorfiles/400.http errorfile 403 /usr/local/haproxy/errorfiles/403.http errorfile 408 /usr/local/haproxy/errorfiles/408.http errorfile 500 /usr/local/haproxy/errorfiles/500.http errorfile 502 /usr/local/haproxy/errorfiles/502.http errorfile 503 /usr/local/haproxy/errorfiles/503.http errorfile 504 /usr/local/haproxy/errorfiles/504.http listen web_port bind *:80 #填写具体的地址端口(可绑定多网卡分流 mode tcp log global #option forwardfor server web1 192.168.36.74:80 weight 2 check port 9000 inter 3000 fall 2 rise 5 #健康检查后端php:9000 server web2 192.168.36.75:80 weight 3 check port 9000 inter 3000 fall 2 rise 5 #健康检查后端php:9000
keepalived
主备配置文件需改变 state MASTER 状态,优先级页需要改变,默认为抢占模式,即主故障后备生效,主恢复后备因为优先级再次失效
global_defs { notification_email { 2222@qq.com } notification_email_from admin@loaclhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id test73 vrrp_skip_check_adv_addr # vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 } vrrp_instance VI_1 { state MASTER interface eth1 virtual_router_id 51 priority 50 advert_int 1 authentication { auth_type PASS auth_pass 1q2w3e4r } virtual_ipaddress { # 192.168.36.179 192.168.36.179 dev eth1 label eth1:0 192.168.36.180 dev eth1 label eth1:1 } }
keepalived 监控脚本
#keepalived 再改变状态即 MASTER 或 BACKUP 时执行脚本 cat /etc/keepalived/notify.sh #!/bin/bash contact='2012@qq.com' notify() { mailsubject="$(hostname) to be $1, vip 转移" mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1" echo "$mailbody" | mail -s "$mailsubject" $contact } case $1 in master) notify master ;; backup) notify backup ;; fault) notify fault ;; *) echo "Usage: $(basename $0) {master|backup|fault}" exit 1 ;; esac 调用方法 vrrp_instance 中调用 notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" #判断本机是否可用,对vs权重进行调整,进而改变VIP的位置
(根据第三方文件判断本机服务是否正常) #主配置文件中声明 vrrp_script chk_down { script "/bin/bash -c '[[ -f /etc/keepalived/down ]]' && exit 7 || exit 0" #script "/usr/bin/killall -0 nginx" #根据文件是否存在测试进程是否活跃 interval 1 weight -20 fall 3 rise 5 timeout 2 } #vrrp_instance 中调用 track_script { #chk_down chk_nginx }