1,基本原理
阶段1
基于JavaScript的代码库,使用这套代码库可以进行页面的交互操作,并且可以重复地在不同浏览器上进行各种测试操作,通过不断改进和优化,这个代码库逐渐成为Selenium Core。Selenium Core为Selenium Remote Control (RC) 和 Selenium IDE提供了坚实的核心基础能力
缺点:
Selenium无法突破浏览器沙盒的限制
阶段2
2016,Google的工程师Simon Stewart开启了WebDriver的项目,此项目可以让测试工具调用浏览器和操作系统本身提供的内置方法,以此来绕过JavaScript环境的沙盒限制
阶段3
Selenium和WebDriver两个项目进行合并,至此,Selenium2.0出现了 (Selenium2.0 = Selenium + WebDriver)
阶段4
Selenium3.0诞生,实现了把核心API跟客户端driver进行分离,同时去掉用的越来越少的Selenium RC功能
Selenium1.0测试步骤
Selenium1.0 (Selenium RC或 Remote Control)工具的核心部分是基于JavaScript代码库实现的
Selenium 1.0的自动化测试执行步骤如下:
1、测试人员基于Selenium支持的编程语言编写好测试脚本程序
2、测试人员执行测试程序
3、测试脚本程序发送访问网站的HTTP请求给Remote Control Server (RC)
4、RC收到请求后,访问被测试网站并获取网页数据内容,并在网页中插入Selenium Core的JavaScript代码库,然后返回给测试人员执行测试的浏览器
5、测试脚本在浏览器内部再调用Selenium Core来执行测试代码逻辑,最后记录测试的结果,完成测试。
以上的第4步是基于浏览器的JavaScript安全机制--同源策略,为了绕过浏览器的安全机制,Selenium1使用了代理方法来解决此问题,实现机制具体如下:
1、执行测试脚本,脚本向Selenium Server发起请求,要求和Selenium Server建立连接
2、Selenium Server的 Launcher 启动浏览器,向浏览器中插入Selenium Core 的JavaScript代码库,并把浏览器的代理设置为 Selenium Server 的 HTTP Proxy
3、测试脚本向 Selenium Server 发送 HTTP 请求,Selenium Server 对请求进行解析,然后通过 HTTP Proxy 发送JS命令通知 Selenium Core 执行操作浏览器的动作
4、Selenium Core 接收到指令后,执行测试脚本指定的网页操作命令
5、浏览器收到新的页面请求信息(在第4步中,Selenium Core 的操作可能引发新的页面请求),于是发送HTTP请求给 Selenium Server 的 HTTP Proxy,请求新的Web页面
6、由于 Selenium Server 在启动浏览器时将浏览器的代理访问地址设置为 Selenium Server 的 HTTP Proxy,所以 Selenium Server 会接收到所有由它启动的浏览器发送的请求。 Selenium Server接收到浏览器发送的HTTP请求后,重组HTTP请求,获取对应的Web页面
7、Selenium Server 的HTTP Proxy 把接收到的Web页面返回给浏览器
通过以上步骤,达到了将 Selenium Core 的JaveScript 代码库插入到被测试网页的目的,然后就可以基于此代码库在被测网页中进行各种自动化测试操作了
WebDriver 的实现原理
WebDriver直接利用了浏览器的内部接口来操作浏览器。
对于不同平台中的不同浏览器,必须依赖浏览器内部的 Native Component (原生组件)来实现把对WebDriver API 调用转化为对浏览器内部接口的调用。
Selenium 1.0采用JavaScript的合成事件来处理网页元素的操作,例如要单击某个页面元素,要先使用JavaScript 定位到这个元素,然后触发单击事件。
而 WebDriver 使用的是系统的内部接口或函数,首先是找到这个元素的坐标位置,并在这个坐标点触发一个鼠标左键的单击操作.
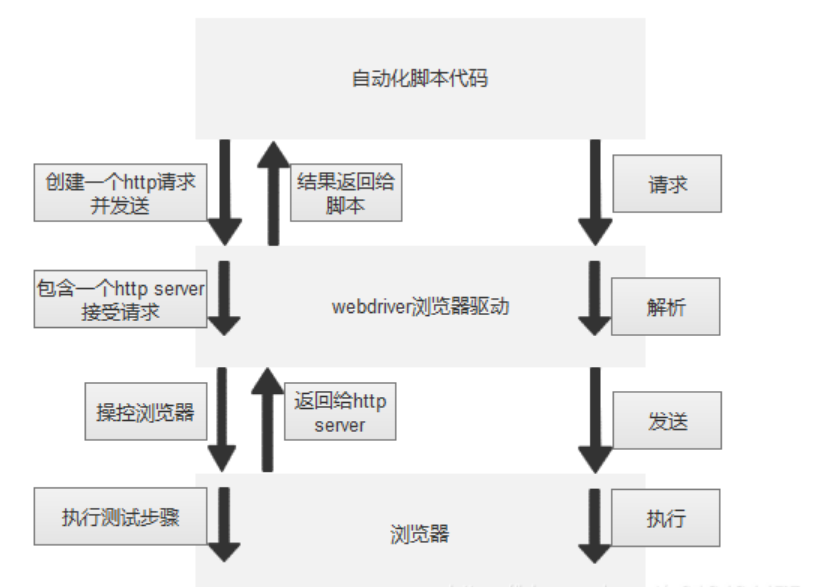
用Selenium实现自动化,主要需要三个东西:
1.自动化测试代码:自动化测试代码发送请求给浏览器的驱动(比如火狐驱动、谷歌驱动)
2.浏览器驱动:它来解析这些自动化测试的代码,解析后把它们发送给浏览器
3.浏览器:执行浏览器驱动发来的指令,并最终完成工程师想要的操作。
测试代码中包含了各种期望的对浏览器界面的操作,例如点击。测试代码通过给Webdriver发送指令,让Webdriver知道想要做的操作,而Webdriver根据这些操作在浏览器界面上进行控制,由此测试代码达到了在浏览器界面上操作的目的
Selenium脚本执行时后端实现的流程:
1.对于每一条Selenium脚本,一个http请求会被创建并且发送给浏览器的驱动
2.浏览器驱动中包含了一个HTTP Server,用来接收这些http请求
3.HTTP Server接收到请求后根据请求来具体操控对应的浏览器
4.浏览器执行具体的测试步骤
5.浏览器将步骤执行结果返回给HTTP Server
6.HTTP Server又将结果返回给Selenium的脚本,如果是错误的http代码我们就会在控制台看到对应的报错信息
WebDriver基于的协议:JSON Wire protocol
JSON Wire protocol是在http协议基础上,对http请求及响应的body部分的数据的进一步规范。body部分主要传送具体的数据,在WebDriver中这些数据都是以JSON的形式存在并进行传送的,这就是JSON Wire protocol。所以在Client和Server之间,只要是基于JSON Wire Protocol来传递数据,就与具体的脚本语言无关了,这样同一个浏览器的驱动就即可以处理Java语言的脚本,也可以处理Python语言的脚本了
参考url:
谷歌浏览器驱动
示例代码:
import time
from selenium import webdriver
driver = webdriver.Chrome('/path/to/chromedriver') # Optional argument, if not specified will search path.
driver.get('http://www.google.com/');
time.sleep(5) # Let the user actually see something!
search_box = driver.find_element_by_name('q')
search_box.send_keys('ChromeDriver')
search_box.submit()
time.sleep(5) # Let the user actually see something!
driver.quit()
安装
#selenium
pip install selenium
#安装指定的ChromeDriver
#https://sites.google.com/a/chromium.org/chromedriver/downloads
#下载指定的驱动版本放在/usr/bin or /usr/local/bin 路径下,或者在调用时指定路径