目前的数仓大概分为离线数仓和实时数仓。离线数仓一般是T+1的数据ETL方案;实时数仓一般是分钟级别甚至更短的时间内的ETL方案。实时数仓一般是将上游业务库的数据通过binlog等形式,实时抽取到Kafka,进行实时ETL。但目前主流的实时数仓也会细分为两类,一类是标准的实时数仓,所有的ETL过程都通过Spark或Flink等实时计算、落地,也就是说数据从binlog抽取到kafka,后续所有的ETL都是读取kafka、计算、写入kafka的形式串联起来的,这种符合完整的数仓定义;还有一类是简化的实时数仓,ETL简化为有限的两层,binlog落地到kafka之后,Spark或Flink读取kafka计算完指标后落地HBase等存储供外部查询分析,当然也有通过Kylin或Druid来完成指标计算的。
那么“准实时数仓”又是一种什么方案呢?
其实“准实时数仓”是离线数仓的一种简单的升级,它将离线的、天级别的ETL过程,缩短为小时或半小时级,但同时又对外提供实时的ODS层数据查询。缩短离线数仓的计算频率比较简单,就是每小时或半小时增量抽取数据,MERGE到ODS层,后续的ETL过程与离线数仓完全一致。
“对外提供实时的ODS层数据查询”有什么使用场景呢?
互联网公司的业务库一般都是MySQL,数据量比较大的情况下,会进行分库分表;每个业务库又会有不同的MySQL实例。如果想跨产品查询数据就会非常麻烦,那谁会跨产品查询数据呢?客服系统。客服系统一般可以查询到某用户所有的信息,如果用户的信息分布在不同的MySQL实例、不同的库、不同的表,查询起来一定会涉及到sharding-jdbc,如果各个产品的sharding字段不同、算法不同,查询一定会比较慢且非常复杂。此时就会需要有一个数据库把这些数据汇总到一块,而数仓的ODS层比较适合做这个工作。
“准实时数仓”的两个功能会涉及两个技术难点:1)数据的增量抽取和增量MERGE;2)提供实时查询接口。下面针对这两个技术难点分别介绍对应的解决方案。
数据的增量抽取和MERGE。
其实增量抽取还算简单,就是根据数据的某个字段进行增量抽取,这个字段可能是自增的ID或者更新时间。两者有什么不同呢?
可以按照ID抽取的表,其中的数据一般不做更新,只是简单的追加。那是不是只需要记录上次抽取的最大ID,下一次从整个ID开始抽取就可以了呢?当然不是。
现在有以下场景:USER_LOGIN_HISTORY表有10个分表,分别为USER_LOGIN_HISTORY_0~ USER_LOGIN_HISTORY_9,其中ID是自增的,比如是auto_increment类型。但假如现在有3个并发事务,分配了3个ID值,比如是1/2/3。但这3个并发事务还没提交的情况下,又来了3个并发事务,他们的ID应该是4/5/6。假如后面3个事务,提前提交,那么在进行增量抽数据的时候,当前ID的最大值是6,,很不巧,此时正值进行增量抽取数据,ID为1/2/3的数据并没有抽取进来。那么这3个事务的数据就再也抽取不过来了!因为下次抽取时,ID的最大值是6,应该会从7开始抽取!
此时应该从上次抽取数据ID的最小值开始抽取,虽然有重复数据,但却可以保证抽取的数据不会丢失。也就是说,如果当前批次是3,则应该从批次1抽取数据的最小ID开始抽取。这是为什么呢?请看下图。
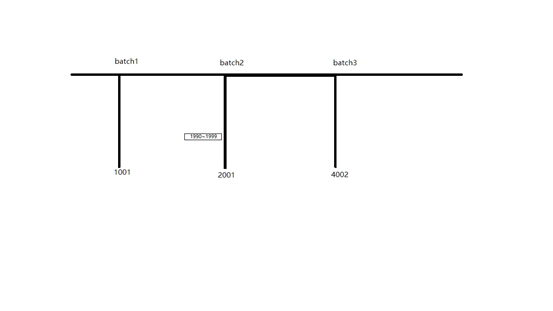
Batch1/batch2/batch3抽取时,MySQL表当前的最大ID分别是1001/2001/4002。Batch2抽取时应该是抽取1001~2001的数据,但很不巧的是,此时ID范围在1990~1999的10条数据还没有提交,抽取时就会漏掉。Batch3抽取时应该从哪里开始抽取呢?1001,1990,还是2001?
理想的情况应该从1990开始抽取,因为只是漏了1990~1999的数据。但怎么才能确定漏了哪些数据呢?答案是不知道。因为你根本不知道抽数时,哪些事务还没有提交。很显然应该从1001开始抽取。其实简单来说就是每次都要抽取两个batch的数据,来避免事务的影响。那一定就是两个batch吗?其实此处设置为两个batch,其实是假设事务的最大持续时间小于每个batch的间隔时间的。对于准实时仓库来说,每个batch一般都是小时或半小时,都会比事务最大持续时间大,所以两个batch就够了。如果batch时间间隔很小,那么久多向前推几个batch就行了。
数据增量抽取后,MERGE就比较简单了,其实就是用增量数据表与ODS全量表进行FULL JOIN,以增量数据为准就行了。但还需要考虑的是业务库的表是否允许物理删除,比如我们是不允许物理删除的,所以FULL JOIN就行了。允许物理删除就比较麻烦了,增量抽取是无法查询到已经删除的数据的!怎么办呢?可以使用binlog把业务库的Delete数据抽取到另外一张表,再用它来清洗ODS全量表就好了。
按照数据更新时间抽取,与上面的方案差不多,但有一点需要注意。抽取的时候,只能限制时间的最小值,而不能限制最大值。比如某个batch抽取时,当前时间是“2019年2月22日18:00:00.153”,因为从计算当前时间到实际抽取可能还是会相差几毫秒或者几秒,那么这期间更新的数据就可能会丢失,因为这些数据可能每次都会在这个间隔内被更新掉!
实时查询接口。
实时且跨产品、跨库、跨表查询的系统一般都是中后台业务系统,这类系统的特点就是查询数据源多、查询结果数据量比较小。一般都是查询某个或某些用户的数据。这可以通过sharding-jdbc或ElasticSearch全文检索来实现。sharding-jdbc虽然可能会有问题,但实施起来比较简单,配置好sharding规则、写好sql就可以了。
ElasticSearch全文检索就比较麻烦了,由于ES没有完善的sql接口,所以只能先将所需的数据汇总好,这又涉及到多表实时关联汇总的问题。假设某个查询结果涉及上游3张表,他们之间的关联条件又不同,在实时汇总时,如果其中一张表的数据没有到,另外两张表就无法入库,只能是先缓存数据等所有数据到达时再次汇总,实施难度还是比较大的。
当然也可以将所需的所有业务库,抽取到某一个MySQL库,进行查询。数据量比较大时,这种方案就会很糟糕。
那比较好的方案是什么呢?我们可以把数据按照逻辑表(分库分表整合后的表)通过binlog实时抽取到Phoenix,前台业务系统通过Phoenix的JDBC接口实时查询。由于Phoenix支持索引,我们可以像使用MySQL一样查询Phoenix,当然了SQL可能需要优化。
由于Phoenix底层是基于HBase做的,可以承载海量数据的读写;而且HIVE也可以映射Phoenix进行离线查询。 这样我们就把实时查询和离线分析的需求进行了统一!那么这个方案有没有什么问题呢?还是有一点需要考虑的:实时抽取的准确性如何保证呢?也就是说,binlog到Phoenix过程中,如果某一条更新日志丢失了该怎么办呢?
很显然可以用增量抽取的数据,补充到Phoenix中。那按照上面的增量抽取、补数逻辑是不是就没事了呢?
其实还是有问题的,仍然是事务的问题,只不过这次是补数时的事务问题。增量数据一般比较大,那么耗时就比较久,假设为3分钟,那么这个时间段内,实时更新的数据会不会被覆盖掉呢?很显然,一定会。既然会覆盖,补数时就判断一下主键相同的数据的更新时间喽,以时间最大的为准。这还是有问题的,因为Phoenix默认是不开启事务的,也就是说,判断的时候,增量数据是最新的,但更新到Phoenix时,增量数据就不一定是最新的了,因为这个时间差内,实时数据进来了。
那就开启Phoenix的事务呗,开启应该能解决这个问题,但目前Phoenix的事务机制还是Beta版本,而且这还可能带来性能问题和死锁问题。
那怎么解决实时数据和离线增量数据相互覆盖的问题了?有没有两全其美的方案呢?
熟悉HBase的同学一定知道,HBase有时间戳的概念,通过时间戳又支持多版本的查询。通过Phoenix插入HBase时,所有列的时间戳都是RegionServer的当前时间,也就是说同一ID插入时,时间戳是递增的,查询时只能查询到最新的数据。那这个跟上面的问题有啥关系呢?
如果我们把数据的更新时间映射到Phoenix底层HBase表的时间戳,是不是就完美解决事务的问题了呢?很简单,数据的更新时间映射到HBase的时间戳,实时数据和增量数据,只需要简单的插入Phoenix就好了,Phoenix查询时只会查询最新的数据!
然而,理想是完美的,现实是残酷的,目前Phoenix不支持不同字段映射到HBase的时间戳!
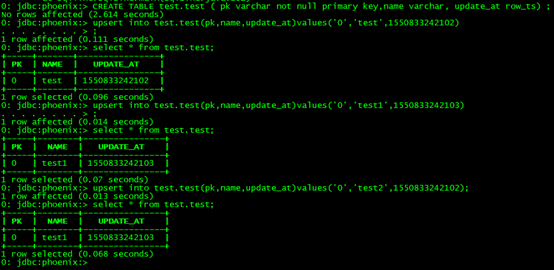
没办法,只能改源码喽。通过修改Phoenix源码,我们使Phoenix支持了ROW_TS这一特殊的字段类型,这个类型的值会写入HBase的时间戳,也就是说Phoenix插入数据时可以自由指定时间戳!下面是改造后的结果,很显然,符合预期。
至此,“准实时数仓”的方案就介绍完了,下面通过架构图简单总结一下。
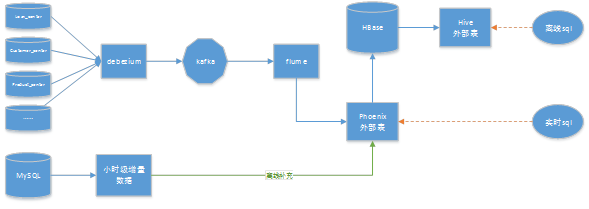
1) 上游MySQL的binlog通过Debezium (或Canal)和flume实时写入Phoenix。新增字段时,实时修改Phoenix表结构
2) 按照数据更新时间,每小时抽取MySQL增量数据,将该部分数据批量MERGE到Phoenix
3) 每天自动创建Hive到Phoenix表的外部表(也可以创建Hive到Phoenix底层HBase表的外部表),进行后续的ETL过程。
4) 实时查询平台通过JDBC连接Phoenix,按照主键或索引实时查询数据