前面感觉真的好乱,想哪,写哪。这里慢慢整理……
SQL Having 语句
还是前面的那两个表:
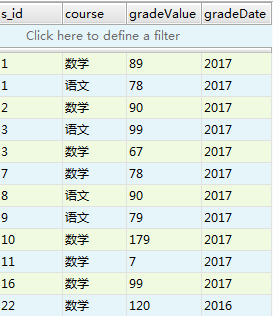
grade表:
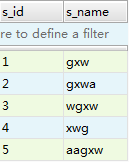
student表:
我们需要查找这里的s_id下的gradeValue的和,这就要分组查询了 :select sum(gradeValue) as nums from grade group by s_id
这里分组查找完毕,但是需要筛选其中gradeValue的和大于100的。怎么筛选。一般都是用 where做子句来筛选,如 where 字段>80;
但是这里的where关键字无法与聚合函数一起使用,才产生了having。
eg: select sum(gradeValue) as nums from grade group by s_id having nums>100;
扯到这,提一下聚合函数: sum(),avg(),count(),max(),min() 等,这些函数呢,都是作用在多条数据上,产生的结果。这里呢就不能用where了。
SQL where group by ,having 区别?
having子句:
having 子句和group by 一起使用时,实现结果是先分组,然后在进行条件查找。SQL 语句编写顺序也一个样,having子句必须写在group by
子句后面。
where子句:
where子句和group by 一起使用时,是先执行 where语句的,然后在走分组语句。SQL编写,where必须在group by 前面。
看看图:
where +group by
select s_id ,gradeValue from grade where gradeValue>80 group by s_id

having +group by
select s_id ,gradeValue from grade group by s_id having gradeValue>80

通过2个图很容易看出,where在分组前就执行,效果没有达到预期,having在分组后,执行选择条件。