本篇主要内容:
- 字符编码
- Python中的数据类型有哪些
- 类型的一些常用操作及方法
一、字符编码
编码解释的大部分内容摘自廖雪峰老师教程中的讲解,点击跳转。
简单介绍:
我们知道计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
我们知道,世界上有多种语言,为了支持本国的语言,都需要各自编制一套编码;那么问题就出现了,由于每一种语言有自己的标准,在多语言混合的文本中,显示出来就会乱码。因此,Unicode就应运而生了。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
ASCII编码是用1个字节表示一个字符,而Unicode编码通常是用2个字节表示一个字符。假如我们写的文档中,都是英文字母,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。因此,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
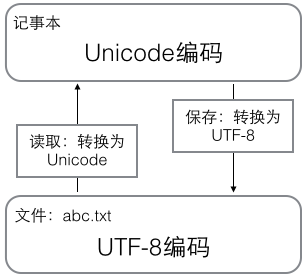
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
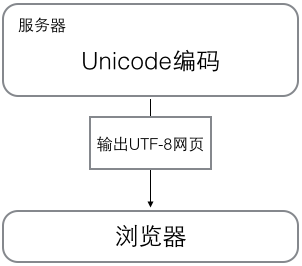
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
总结:
1、ASCII 8bit 1个字节(byte)
2、GBK 16bit 2个字节
3、Unicode 32bit 4个字节
4、Utf-8(针对Unicode的可变长度字符编码)
(1)英文字符 8bit 1个字节
(2)汉字 24bit 3个字节
(3)生僻的字符 4-6字节
注意:
Python2中默认的字符编码是ascii码。
Python3目前默认的编码是utf-8。
~ � python � ✔ � 14:41:19 Python 2.7.15 (default, Jun 17 2018, 13:05:56) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'ascii' >>> exit() ~ � python3 � ✔ � 15:42:29 Python 3.6.5 (default, Jun 17 2018, 12:26:58) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8'
二、Python中的数据类型
1、int 整形
2、bool 布尔
3、str 字符串(不可变)
4、list 列表
5、tuple 元组(不可变)
6、dict 字典
7、set 集合
三、各种类型的一些常用操作及方法
1. int 一些数学运算省略不介绍了(加减乘除,取余,地板除等)
bit_length() 整形的二进制位数(长度)
>>> a = 5
>>> a.bit_length()
3
2. bool
bool(object) # 返回对象的真假(True or False)
什么样的对象时False呢?
None,空对象('', [], (), {}, set()),即空的字符串、列表、元组、字典、集合都为False。这里需要注意 ' ' ,含有空格的字符串,值为True。
排除以上False的对象,其他都是True。
3. 字符串
3.1 索引切片
索引:下表从0开始
切片:str[起始位置:结束位置:步长] 结果不包括结束位置索引处元素,步长可以是正数,可以是负数。
s = 'hello world' print(s[0:5]) print(s[0:5:2]) print(s[5:0]) print(s[5:0:-1]) print(s[-1:-6:-1]) # 输出结果 hello hlo olle dlrow [Finished in 0.1s]
'''
对于步长为负数的情况,我经常搞混,这里说一下我个人的理解。
1. 步长为正数,从左向右取
1.1 起始位置索引处的值先出现(先出现是指相对结束位置索引处的值靠左),可以取到值。
1.2 如果起始位置索引处的值后出现,取不到值
步长为负数,想取到值:起始位置索引 < 结束位置索引
2. 步长为负数,从右向左取
2.1 起始位置索引处的值后出现,可以取到值。
2.2 如果起始位置索引处的值先出现,取不到值
步长为负数,想取到值:起始位置索引 > 结束位置索引
'''
3.2 字符串操作
常用:
1. capitalize # 字符串首字母大写
2. title # 字符串中被特殊字符分隔的部分,每部分首字母大写(中文也被当作特殊字符处理)
3. upper # 字符串中小写字母变大写
4. lower # 字符串中大写字母变小写
5. strip # 去掉字符串首尾空格,也可以自己指定字符
6. replace # 字符替换
7. split # 使用字符串中的指定符号分割字符串,以列表形式返回结果
8. find # 查找,返回匹配部分的第一个字符的索引位置;匹配不到,返回-1
9. len # 返回字符串长度
实例:
s = 'say hEllo woRld' print(s.capitalize()) #Say hello world print(s.title()) #Say Hello World print(s.upper()) #SAY HELLO WORLD print(s.lower()) #say hello world print(' hello world '.strip()) #hello world print(s.replace('say', 'speak')) #speak hEllo woRld print(s.split()) #['say', 'hEllo', 'woRld'] print(s.find('hE')) #4 print(s.find('H')) #-1 print(len(s)) #15
不常用:
1. swapcase # 大小写互相转换,字符串中大写变小写,小写变大写
2. lstrip # 去掉左边空格
3. rstrip # 去掉右边空格
4. casefold # 字符串中大写字母变小写,与lower类似(很少使用);lower对某些字符支持不够好,casefold对所有字符都有效
实例:
s = 'say hEllo woRld' print(s.swapcase()) print(' hello world '.lstrip()) print(' hello world '.rstrip()) # 输出结果 SAY HeLLO WOrLD hello world hello world
列表,元组,字典下篇文章介绍。
------以上是第三、四天的学习内容------