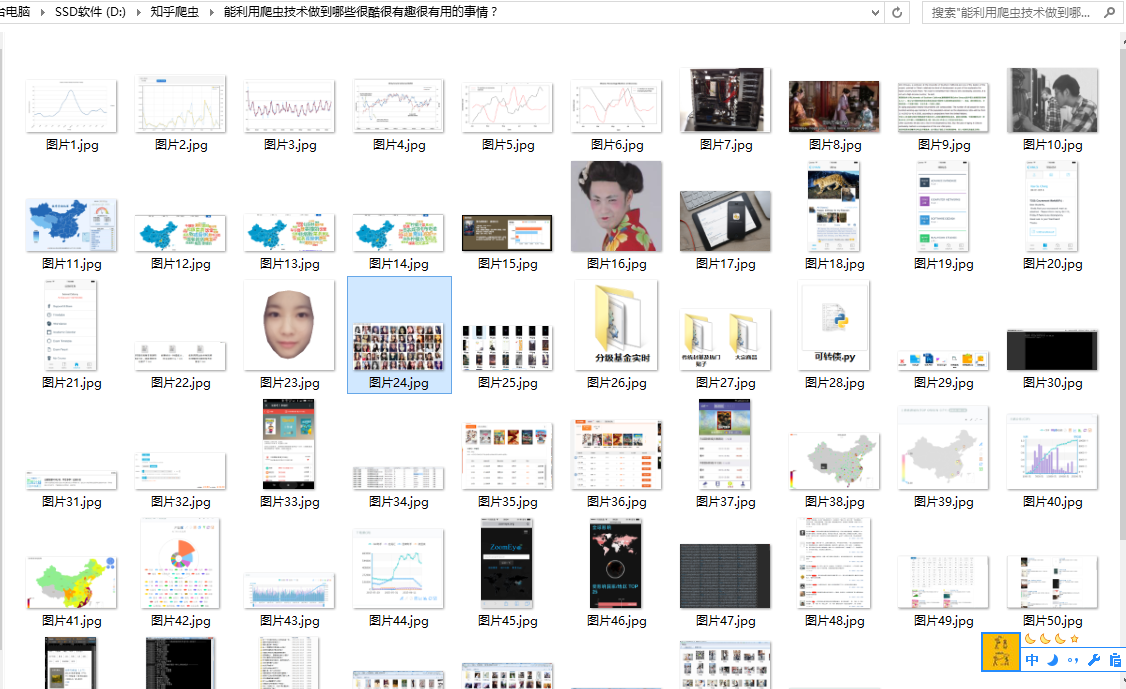
在知乎上看到一个问题 能利用爬虫技术做到哪些很酷很有趣很有用的事情?发现蛮好玩的,便去学了下正则表达式,以前听说正则表达式蛮有用处的,学完后觉得确实很实用的工具。问题评论下基本都是python写的爬虫,我看了下原理,感觉爬一个简单的静态网页还是挺容易的。就是获取网站html源码,然后解析需要的字段,最后拿到字段处理(下载)。想起我学java的时候有个URL类好像有这个功能,便去翻了下api文档,发现URLConnection果然可以获取html源码。
首先从核心开始写,获取网页源码
package mothed; import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.URL; import java.net.URLConnection; /** * 爬取网页源代码 * @author ganhang * */ public class Spider { public static String GetContent(String url) { // 定义一个字符串用来存储网页内容 String result = ""; BufferedReader in = null; try { URL realUrl = new URL(url); // 初始化链接 URLConnection connection = realUrl.openConnection(); // BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8")); // 用来临时存储抓取到的每一行的数据 String line; while ((line = in.readLine()) != null) { // 遍历抓取到的每一行并将其存储到result里面 System.out.println(line); result += line; } } catch (Exception e) { System.out.println("GetContent出现异常!" + e); e.printStackTrace(); } // 使用finally来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return result; } }
然后是解析获得的Content得到想要的字段,题目,答案中的图片链接
package bean; import java.util.ArrayList; import java.util.regex.Matcher; import java.util.regex.Pattern; import mothed.Spider; /** * 知乎图片bean * @author ganhang * */ public class ZhiHuBean { public String zhihuUrl;// 网页链接 public String question;// 问题名; public ArrayList<String> zhihuPicUrl;// 图片链接 public String getQuestion() { return question; } public void setQuestion(String question) { this.question = question; } public ArrayList<String> getZhihuPicUrl() { return zhihuPicUrl; } public void setZhihuPicUrl(ArrayList<String> zhihuPicUrl) { this.zhihuPicUrl = zhihuPicUrl; } // 构造方法初始化数据 public ZhiHuBean(String url) throws Exception { zhihuUrl = url; zhihuPicUrl = new ArrayList<String>(); // 判断url是否合法 if (isZhuHuUrl(url)) { url=getRealUrl(url); System.out.println("正在抓取知乎链接:" + url); // 根据url获取该问答的细节 String content = Spider.GetContent(url); //System.out.println("content:"+content); Matcher m; // 匹配标题 m = Pattern.compile("zh-question-title.+?<h2.+?>(.+?)</h2>").matcher(content); if (m.find()) { question = m.group(1); } // 匹配答案图片链接 m = Pattern.compile("</noscript><img.+?src="(https.+?)".+?").matcher(content); boolean isFind; while (isFind= m.find()) { zhihuPicUrl.add(m.group(1)); } }else throw new Exception("网址有误!请输入知乎网址!"); } // 处理url String getRealUrl(String url) { // 将http://www.zhihu.com/question/22355264/answer/21102139 //转化成http://www.zhihu.com/question/22355264 Matcher m = Pattern.compile("(\d*)/answer/(\d*)").matcher(url); if (m.find()) { return "http://www.zhihu.com/question/" + m.group(1); } else { return url; } } //判断知乎网址 boolean isZhuHuUrl(String url){ if(url.startsWith("http://www.zhihu.com/question/")){ return true; }else return false; } }
获得链接后就开始下载了
1 package mothed; 2 3 import java.io.DataInputStream; 4 import java.io.File; 5 import java.io.FileOutputStream; 6 import java.io.FileWriter; 7 import java.io.IOException; 8 import java.net.URL; 9 import java.util.ArrayList; 10 11 import bean.ZhiHuBean; 12 /** 13 * 下载器 14 * @author ganhang 15 * 16 */ 17 public class DownLoad { 18 // 传入zhiHuBean,创建文件夹,并下载图片 19 public static boolean downLoadPics(ZhiHuBean zhiHuBean, String filePath) throws Exception { 20 // 文件路径+标题 21 String dir = filePath + zhiHuBean.getQuestion(); 22 // 创建 23 File fileDir = new File(dir); 24 fileDir.mkdirs(); 25 // 获取所有图片路径集合 26 ArrayList<String> zhiHuPics = zhiHuBean.getZhihuPicUrl(); 27 // 初始化一个变量,用来显示图片编号 28 int i = 1; 29 // 循环下载图片 30 for (String zhiHuPic : zhiHuPics) { 31 URL url = new URL(zhiHuPic); 32 // 打开网络输入流 33 DataInputStream dis = new DataInputStream(url.openStream()); 34 String newImageName = dir + "/" + "图片" + i + ".jpg"; 35 // 建立一个新的文件 36 FileOutputStream fos = new FileOutputStream(new File(newImageName)); 37 byte[] buffer = new byte[1024]; 38 int length; 39 System.out.println("正在下载......第 " + i + "张图片......请稍后"); 40 // 开始写入 41 while ((length = dis.read(buffer)) > 0) { 42 fos.write(buffer, 0, length); 43 } 44 dis.close(); 45 fos.close(); 46 System.out.println("第 " + i + "张图片下载完毕......"); 47 i++; 48 } 49 return true; 50 } 51 }
测试类
package test; import java.util.ArrayList; import mothed.DownLoad; import bean.ZhiHuBean; /** * 抓取知乎图片并下载 * * @author ganhang * */ public class ZhiHuSpiderTest { public static void main(String[] args) throws Exception { /** * 爬知乎图片,并下载到本地 */ // 链接注意用http String url = "http://www.zhihu.com/question/27621722"; // 获取ZhiHuBean ZhiHuBean myZhihu = new ZhiHuBean(url); // 获取ZhiHuBean中的图片列表 ArrayList<String> picList = myZhihu.getZhihuPicUrl(); // 打印结果 System.out.println("标题:" + myZhihu.getQuestion()); System.out.println(""); //定义下载路径 String addr = "D:/知乎爬虫/"; System.out.println("即将开始下载图片到"+addr+myZhihu.getQuestion()); System.out.println(""); System.out.println("开始下载................"); System.out.println(""); // 把图片下载到本地文件夹 DownLoad.downLoadPics(myZhihu, addr); System.out.println(""); System.out.println("图片下载完毕,请到"+addr+myZhihu.getQuestion()+"里去看看吧!!!"); } }
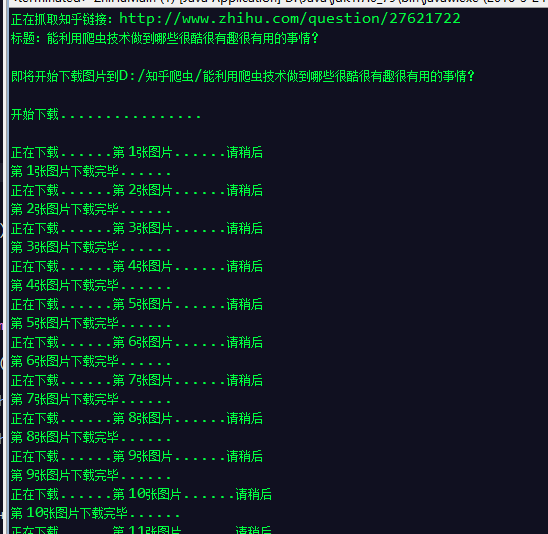
打开文件夹就可以慢慢欣赏图片了。。