ELK安装
ELK解决方案:elasticSearch + LogStash + Kibana = ELK Stack
ElasticSearch官网:elastic.co
ElasticSearch:是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
准备:
安装es之前需要安装jdk,2.3.5版本,jdk要求在1.8以上
jdk安装:wget http://download.java.net/java/jdk8u162/archive/b03/binaries/jdk-8u162-ea-bin-b03-linux-x64-24_oct_2017.tar.gz
解压:tar -zxvf jdk-8u162-ea-bin-b03-linux-x64-24_oct_2017.tar.gz -C /usr/local/
配置环境变量:vim /etc/profile
添加如下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_162
export PATH=$JAVA_HOME/bin:$PATH
刷新配置:source /etc/profile
安装es:
打开网址:https://www.elastic.co/downloads/past-releases

下载:
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.5/elasticsearch-2.3.5.tar.gz
解压:
tar -zxvf elasticsearch-2.3.5.tar.gz -C /usr/local/
启动之前需要修改配置: vim elasticsearch.yml
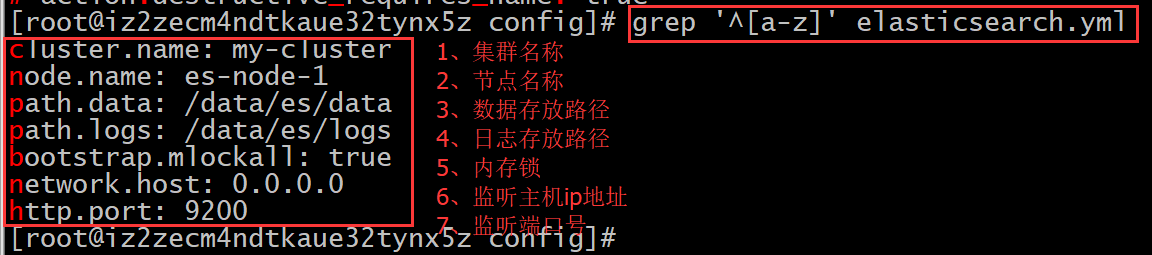
创建对应的数据和日志目录:
#创建一个data目录,用于存放data数据和logs日志:
mkdir /data/es/data mkdir /data/es/logs
或者
mkdir -vp /data/es/{data,logs}
查看目录结构:
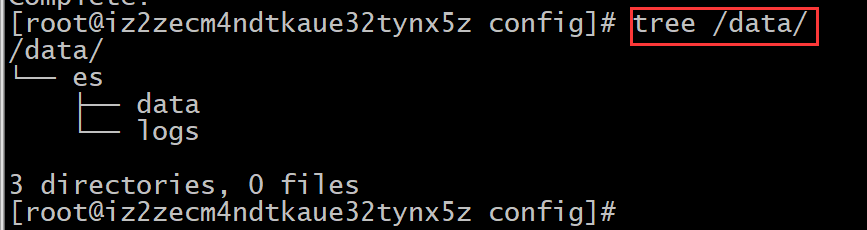
【在多台机器上执行下面的命令】
cat /etc/passwd|grep 用户名,用于查找某个用户
cat /etc/group|grep 组名,用于查找某个用户组
groups 查看当前登录用户的组内成员
groups hadoop01 查看hadoop01用户所在的组,以及组内成员
whoami 查看当前登录用户名
#es启动时需要使用非root用户,所有创建一个hadoop01用户: useradd hadoop01 #为hadoop01用户添加密码:
passwd hadoop01 #给相应的目录添加权限 chown -R hadoop01:hadoop01/{hadoop01,data}
说明:新创建的用户会在/home下创建一个用户目录hadoop01
usermod --help 修改用户这个命令的相关参数
userdel hadoop01 删除用户hadoop01
rm -rf hadoop01 删除用户所在目hadoop01
上面的几个命令只有root账号才可以使用,如果你不知道自己的系统上面的命令在什么位置可以使用如下命令查找其路径:
locate useradd
启动es:./elasticseatch -d
-d 是后台运行
浏览器测试访问:http://192.168.200.101:9200/
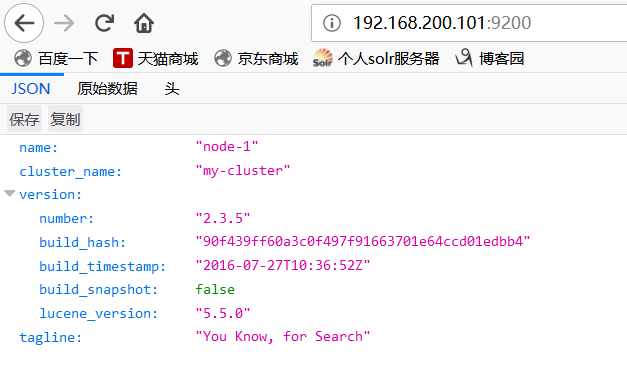
查看日志:cd /usr/local/elasticsearch-2.3.5/logs
执行 less my-cluster.log(集群名称.log)
启动程序报错:
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000006fff80000, 2863661056, 0) failed; error=’Cannot allocate memory’ (errno=12) #There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (malloc) failed to allocate 2863661056 bytes for committing reserved memory. # An error report file #with more information is saved as: # /home/raini/IdeaProjects/spark_mllib/hs_err_pid19206.log
内存不足: 减少启动程序所需内存,或加大内存,如关闭一些程序。

ELK收集nginx日志并用高德地图展示出IP
http://blog.51cto.com/liqingbiao/1940469
如何和es进行交互:
restful API:linux的curl工具
开发语言的API:java、JavaScrip、.NET、PHP、Python、Ruby
安装CURL工具
curl 的官网下载地址:http://curl.haxx.se/download/
1.下载:wget https://curl.haxx.se/download/curl-7.57.0.tar.gz
2.解压:tar -xzvf curl-7.57.0.tar.gz
3.安装:
cd curl-7.57.0
./configure
make
make install
4.完成
测试:curl -i -XGET 'http://www.baidu.com'
-i参数 表示为携带请求头信息
-XGET 参数 表示为get请求方式
curl方式和es进行交互:
查询:
curl -i -XGET 'http://192.168.200.101:9200/_count?pretty' -d '
{
"query":{
"match_all":{}
}
}'
解释:
-i:显示请求头
-XGET:请求方式
http://192.168.200.101:9200:IP+端口
_count:查询的内容
pretty:输出的样式
安装es交互插件head:
在bin目录下执行 ./plugin install mobz/elasticsearch-head
./plugin install file:///home/bigdata/elasticsearch-head-master.zip
测试访问:http://192.168.200.101:9200/_plugin/head/

安装es监控插件kopf:
./plugin install lmenezes/elasticsearch-kopf
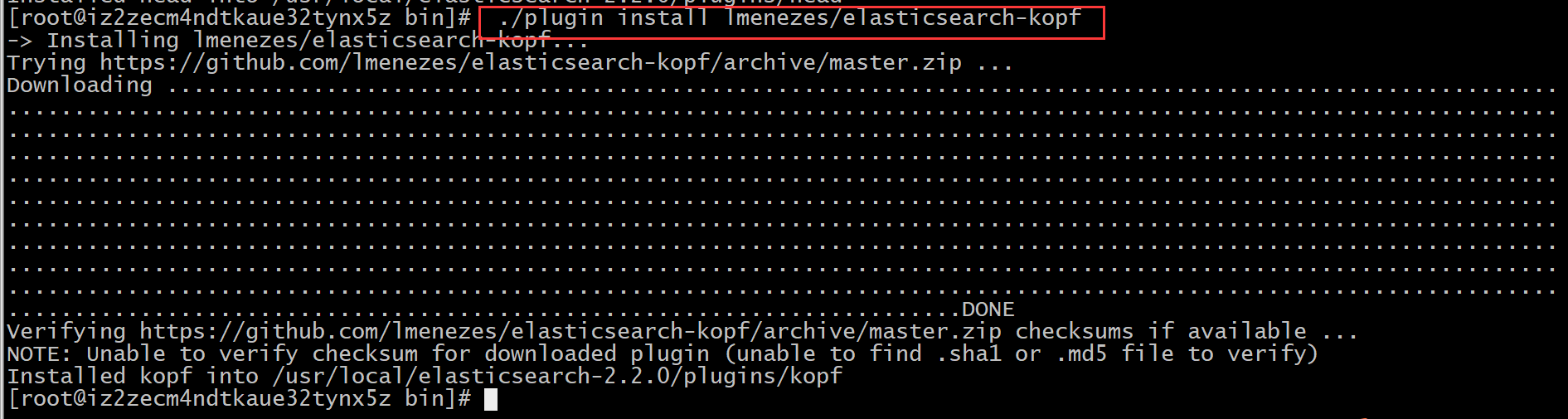
测试访问:http://192.168.200.101:9200/_plugin/kopf/
RESTful接口URL的格式:
http://localhost:9200/<index>/<type>/[<id>]
其中index、type是必须提供的。
id是可选的,不提供es会自动生成。
index、type将信息进行分层,利于管理。
index可以理解为数据库;type理解为数据表;id相当于数据库表中记录的主键,是唯一的。

偶数就会造成脑裂
防止脑裂的配置:
-
Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
-
Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
-
Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。