原理
通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。哇~
(为何有种相见恨晚的赶脚??)
- 就是发送GET请求,获取HTML
- 解析HTML获取数据
步骤
- 根据url获取HTML数据
- 解析HTML,获取目标信息
- 存储数据
- 重复第一步
必备基础知识
- python基础知识,随便找个博客或者看官方文档都行,我在datacamp上面又看了一遍
- HTML语法格式,这个可以参考一下尚硅谷的谷粒学院那个老师讲的,真的觉得老师讲的思路清晰,他后面讲python全栈也很清晰,b战上有的,名字忘记了,姓李。
基础知识可以参考一下崔庆才老师的官方博客,基本知识点都提到了,就是不太深,但是作为入门够了.
几个重要概念
- url:统一资源定位符==请求的协议(http/https) + 网站的域名 + 资源的路径 + 参数
举个例子:https://blog.csdn.net/pleasecallmewhy/article/details/8922826
这个链接的中文释义就是,可以https这个协议访问的资源,位于主机blog.csdn.net上,存在主机的这个/pleasecallmewhy/article/details/8922826位置上
就可以深刻理解统一资源定位符的概念了
-
HTTP:超文本传输协议
- 以明文的形式传输
- 效率更高,但不安全
-
HTTPS:HTTP + SSL(安全套接子字层)
- 传输之前数据先加密,之后解密获取内容
- 效率较低,但是安全
- HTTP协议之请求
- 1.请求行
- 2.请求头
-
User_Agent:用户代理:对方服务器能够通过user_agent知道当前请求对方资源的是什么浏览器
-
Cookie:用来存储用户信息的,每次请求会被携带上发送给对方的浏览器
-
要获取登录后才能访问的页面
-
对方的服务器会通过Cookie来判断我们是一个爬虫
-
请求体(get没有,post有)
携带数据 -
HTTP协议之响应
- 1.响应头
- Set-Cookie:对方服务器通过该字段设置cookie到本地
- 2.响应体
- url地址对应的响应
get请求和post请求的区别
-
①get请求无请求体,post有
-
②get请求把数据放到URL地址中
-
③post请求change用于登录注册
-
④post请求携带的数据量比get请求大,多,常用于传输大文本
因此第一阶段的学习目标
1.request库
2.beautifulsoup库
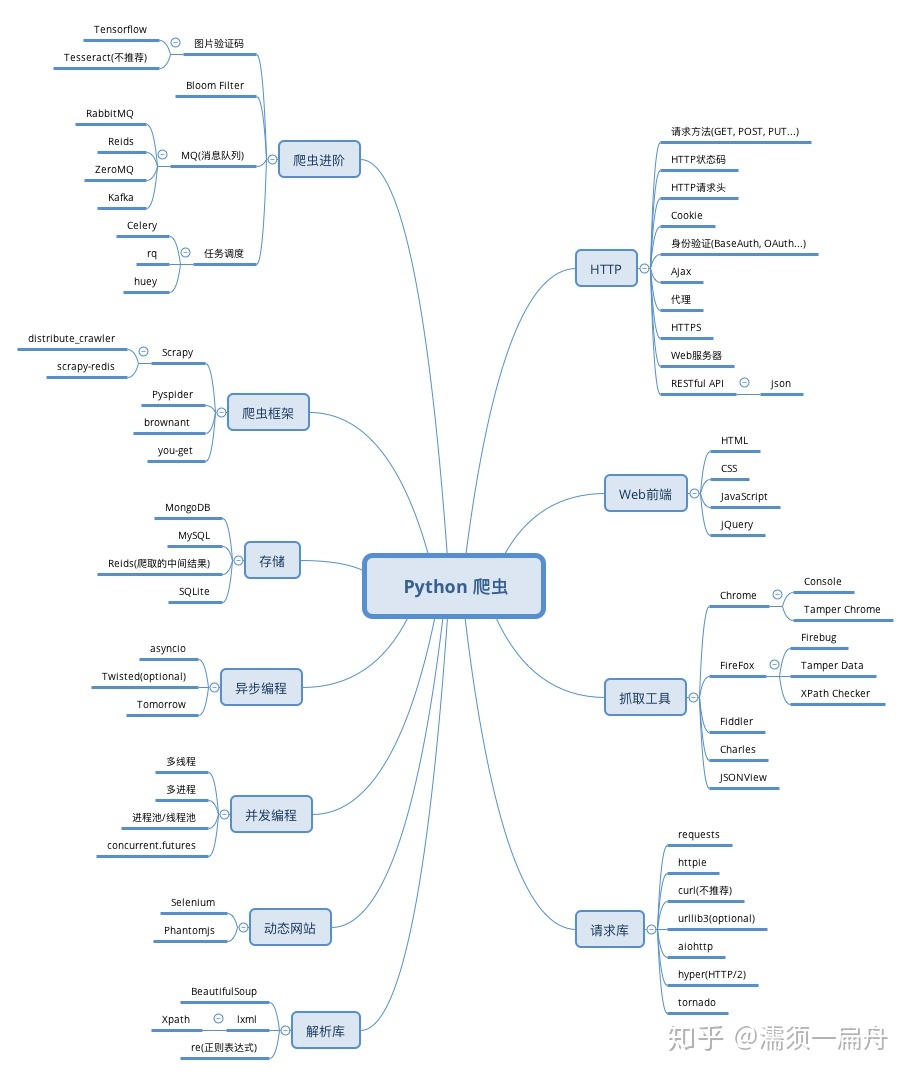
从知乎找到了一张图,我感觉很详细