- pandas cookbook
- rename()
- .sort_values(ascending)
- 日期处理
- subset
- .isin()
- 运算符的使用
- agg()
- counting
- drop_duplicates()
- .value_counts().
- group
- pivot_table()
- set_index()
- sort_index()
- ret_index()
- loc
- iloc
- 可视化
- 缺失值
- 创建一个数据框
- to_csv
- list comprehension
- Reading multiple data files
- 添加列
- ffill()
- reindex()
- columns重命名
- df.pct_change()
- add()
- concat()
- merge
- merge_ordered:
- merge_asof
- Analyzing Police Activity with pandas
pandas cookbook
rename()
给df的列重命名,字典的键值对的形式
df.rename(columns={
"原名":"新名",
"原名":"新名",
"原名":"新名"
......
}
inplace=true
)
.sort_values(ascending)
ascend=True,默认,ascend=False
和r里面的arrange一样的功能
排序函数,可以安照升序和降序进行排序,还可以同时指定两个
homelessness_reg_fam = homelessness.sort_values(["region", "family_members"], ascending=[True, False])
日期处理
to_datetime[format=]
subset
提取子集
- 提取一个子集的时候使用一个["列名"]
- 提取多个子集的时候使用两个括号[["列名1","列2..,"列名n"]]
原理也很简单就是外部先生成一个list,完事提取子list - 可以只用逻辑运算筛选特定的子集 ,此时返回true or false,那么就可以进一步提取
例如df["height"]>168,那么提取大于168的就可以使用df[df["height"]>168]
常见的有>,<,==,and,&...
.isin()
类似于r里面的%in% ,判断是否存在,可以进行过滤
运算符的使用
可以直接进行两列+-*/。。
df.[""]+df.[""]
agg()
可以直接基于列计算统计量

除了一般的列之外,时间序列也是同样适用的
The .agg() method allows you to apply your own custom functions to a DataFrame, as well as apply functions to more than one column of a DataFrame at once, making your aggregations super efficient.可以使用agg自定义函数
agg里面可以同时计算几个统计量,不是限定一个
- Cumulative statistics累计统计
- .cumsum()
- .cummax()
counting
drop_duplicates()
去除重复的行
参数
- subset: 列名,可选,默认为None,subset=["",""...""]
- keep: {‘first’, ‘last’, False}, 默认值 ‘first’
- first: 保留第一次出现的重复行,删除后面的重复行。
- last: 删除重复项,除了最后一次出现。
- False: 删除所有重复项。
-inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。(inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。
.value_counts().
查看有多少的不同值,并计算每个值中多多有重复值的数量
group
Grouped summary statistics
sales_by_type = sales.groupby("type")["weekly_sales"].sum()
分组之后可以选取特定特征进行统计运算
可以使用多个变量进行分组,可以统计指定特征的统计值
sales_by_type_is_holiday = sales.groupby(["type", "is_holiday"])["weekly_sales"].sum()
额原来的汇总的是这么来的
unemp_fuel_stats = sales.groupby("type")[["unemployment", "fuel_price_usd_per_l"]].agg([np.min, np.max, np.mean, np.median])
<script.py> output:
unemployment fuel_price_usd_per_l
amin amax mean median amin amax mean median
type
A 3.879 8.992 7.973 8.067 0.664 1.107 0.745 0.735
B 7.170 9.765 9.279 9.199 0.760 1.108 0.806 0.803
pivot_table()
数据透视表
print(sales.pivot_table(values="weekly_sales", index="department", columns="type", aggfunc=aggfunc=[np.sum,np.mean],fill_value=0, margins=True))
- Values可以对需要的计算数据进行筛选
- aggfunc参数可以设置我们对数据聚合时进行的函数操作
- fill_value填充空值,margins=True进行汇总
- columns:有点类似于group的意思
可以生成一个数据透视表
set_index()
- 函数原型:DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
- keys:列标签或列标签/数组列表,需要设置为索引的列
- drop:默认为True,删除用作新索引的列
- append:默认为False,是否将列附加到现有索引
- inplace:默认为False,适当修改DataFrame(不要创建新对象)
- verify_integrity:默认为false,检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能。
设置多个索引
# Index temperatures by country & city
temperatures_ind = temperatures.set_index(["country", "city"])
# List of tuples: Brazil, Rio De Janeiro & Pakistan, Lahore
rows_to_keep = [("Brazil", "Rio De Janeiro"), ("Pakistan", "Lahore")]
# Subset for rows to keep
print(temperatures_ind.loc[rows_to_keep])
<script.py> output:
date avg_temp_c
country city
Brazil Rio De Janeiro 2000-01-01 25.974
Rio De Janeiro 2000-02-01 26.699
Rio De Janeiro 2000-03-01 26.270
Rio De Janeiro 2000-04-01 25.750
Rio De Janeiro 2000-05-01 24.356
... ... ...
Pakistan Lahore 2013-05-01 33.457
Lahore 2013-06-01 34.456
Lahore 2013-07-01 33.279
Lahore 2013-08-01 31.511
Lahore 2013-09-01 NaN
[330 rows x 2 columns]
sort_index()
默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
注意:sort_index()可以完成和df. sort_values()完全相同的功能,但python更推荐用只用df. sort_index()对“根据行标签”和“根据列标签”排序,其他排序方式用df.sort_values()
ret_index()
还原索引
loc
#平时可以写的几种方法
print(temperatures_srt.loc[("Pakistan", "Lahore"):("Russia", "Moscow")])
print(temperatures_srt.loc[:, "date":"avg_temp_c"])
iloc
这个切片是不包括最后一项的
取前5行的化,前面的0可以省略
print(temperatures.iloc[:5, 2:4])
可视化
# Histogram of conventional avg_price
avocados[avocados["type"] == "conventional"]["avg_price"].hist()
# Histogram of organic avg_price
avocados[avocados["type"] == "organic"]["avg_price"].hist()
# Add a legend
plt.legend(["conventional", "organic"])
# Show the plot
plt.show()

缺失值
isna().any():判断哪些列存在缺失值
isna().sum():统计每个样本的缺失值的个数,完事画个图,查看缺失值哪个样本多
.dropna()移除缺失值
fillna()填充缺失值
创建一个数据框
[{}]
# Create a list of dictionaries with new data
avocados_list = [
{"date": "2019-11-03", "small_sold": 10376832, "large_sold": 7835071},
{"date": "2019-11-10", "small_sold": 10717154, "large_sold": 8561348},
]
# Convert list into DataFrame
avocados_2019 = pd.DataFrame(avocados_list)
# Print the new DataFrame
print(avocados_2019)
或者创建一个字典列表
# Create a dictionary of lists with new data
avocados_dict = {
"date": ["2019-11-17", "2019-12-01"],
"small_sold": [10859987, 9291631],
"large_sold": [7674135, 6238096]
}
# Convert dictionary into DataFrame
avocados_2019 = pd.DataFrame(avocados_dict)
# Print the new DataFrame
print(avocados_2019)
to_csv
pd.to_csv(),写入csv文件
pd.read_csv(filepath_or_buffer,header,parse_dates,index_col)
- 路径
- 列名
- 解析索引
- 设置索引
list comprehension
这个功能好强大啊
[expr for iter in iterable if cond_expr]
- [expr]:最后执行的结果
- [for iter in iterable]:这个可以是一个多层循环
- [if cond_expr]:两个for间是不能有判断语句的,判断语句只能在最后;顺序不定,默认是左到右。
Reading multiple data files
同时读多个文件的时候可以使用循环,但是没有用上python强大的列表解析
# Import pandas
import pandas as pd
# Create the list of file names: filenames
filenames = ['Gold.csv', 'Silver.csv', 'Bronze.csv']
# Create the list of three DataFrames: dataframes
dataframes = []
for filename in filenames:
dataframes.append(pd.read_csv(filename))
# Print top 5 rows of 1st DataFrame in dataframes
#输出指定的第几个数据集
print(dataframes[2].head())
添加列
df.['列名']=新列值
ffill()
用.ffill()方法进行的操作则是先重新索引得到一个新的DataFrame,再前向填充缺失值
与使用method=fill有一定的差别
reindex()
重新指定索引
columns重命名
temps_c.columns = temps_c.columns.str.replace('F', 'C')
这里注意要先str
df.pct_change()
DataFrame.pct_change(periods=1, fill_method=‘pad’, limit=None, freq=None, **kwargs)
因此第一个值的位置是NAN
表示当前元素与先前元素的相差百分比,当然指定periods=n,表示当前元素与先前n 个元素的相差百分比。
add()
可以直接加到df的每一列上面
DataFrame.add(other, axis='columns', level=None, fill_value=None)
concat()
拼接两个df,可以横向拼接,可以纵向拼接
pd.concat()
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
axis='columns'
表示按列合并
keys:合并时同时增加区分数组的键
这个是纵向拼接
join:{'inner','outer'},默认为“outer”。如何处理其他轴上的索引。outer为并集和inner为交集。
merge
一个类似于关系数据库的连接(join)操作的方法merage,可以根据一个或多个键将不同DataFrame中的行连接起来
DataFrame1.merge(DataFrame2, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’))
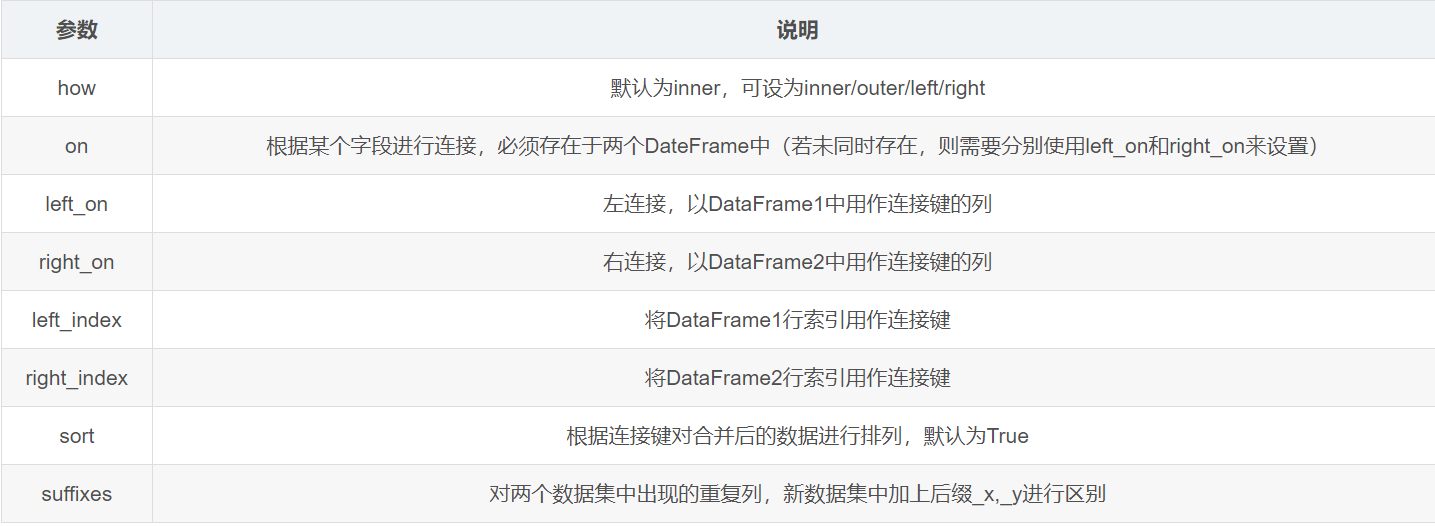
我觉得这个函数不好用
需要搞清楚join,merge,concat什么时候用,区别与联系
join方法提供了一个简便的方法用于将两个DataFrame中的不同的列索引合并成为一个DataFrame。其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left
merge_ordered:
函数允许组合时间序列和其他有序数据。 特别是它有一个可选的fill_method关键字来填充/插入缺失的数据。
merge_asof
Similar to pd.merge_ordered(), the pd.merge_asof() function will also merge values in order using the on column, but for each row in the left DataFrame, only rows from the right DataFrame whose 'on' column values are less than the left value will be kept.
Analyzing Police Activity with pandas
一个实例