tensorflow_hub
武神教的这个预训练模型,感觉比word2vec效果好很多~
只需要分词,不需要进行词条化处理
总评:方便,好用,在线加载需要时间
步骤
- 文本预处理(去非汉字符号,jieba分词,停用词酌情处理)
- 加载预训练模型
- 可以加上attention这样的机制等
给一个简单的栗子,完整代码等这个项目开源一起给链接
这里直接给模型的栗子
import tensorflow as tf
import tensorflow_hub as hub
# ResourceExhaustedError: OOM when allocating tensor with shape[971177,50]
# early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10) callbacks 不能写在这里? 会报错 EagerVariableNameReuse
hub_layer = hub.KerasLayer("https://hub.tensorflow.google.cn/google/tf2-preview/nnlm-zh-dim50-with-normalization/1", output_shape=[50],
input_shape=[], dtype=tf.string,trainable = True)
model = tf.keras.Sequential()
model.add(hub_layer)
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(3, activation='softmax'))
model.summary()
model.compile(loss= 'sparse_categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(x= X_train, y= y_train, epochs= 100, validation_data= (X_dev, y_dev), batch_size= 100 ,verbose=1,callbacks= [early_stop])
#history = model.fit(train_dataset, epochs= 20, validation_data= dev_dataset) 会报错?
plot_graphs(history, metric= 'accuracy')
pred = model.predict_classes(test_online)
应该把预训练模型下载下来保存到本地,但是貌似要配置环境,会比较麻烦~
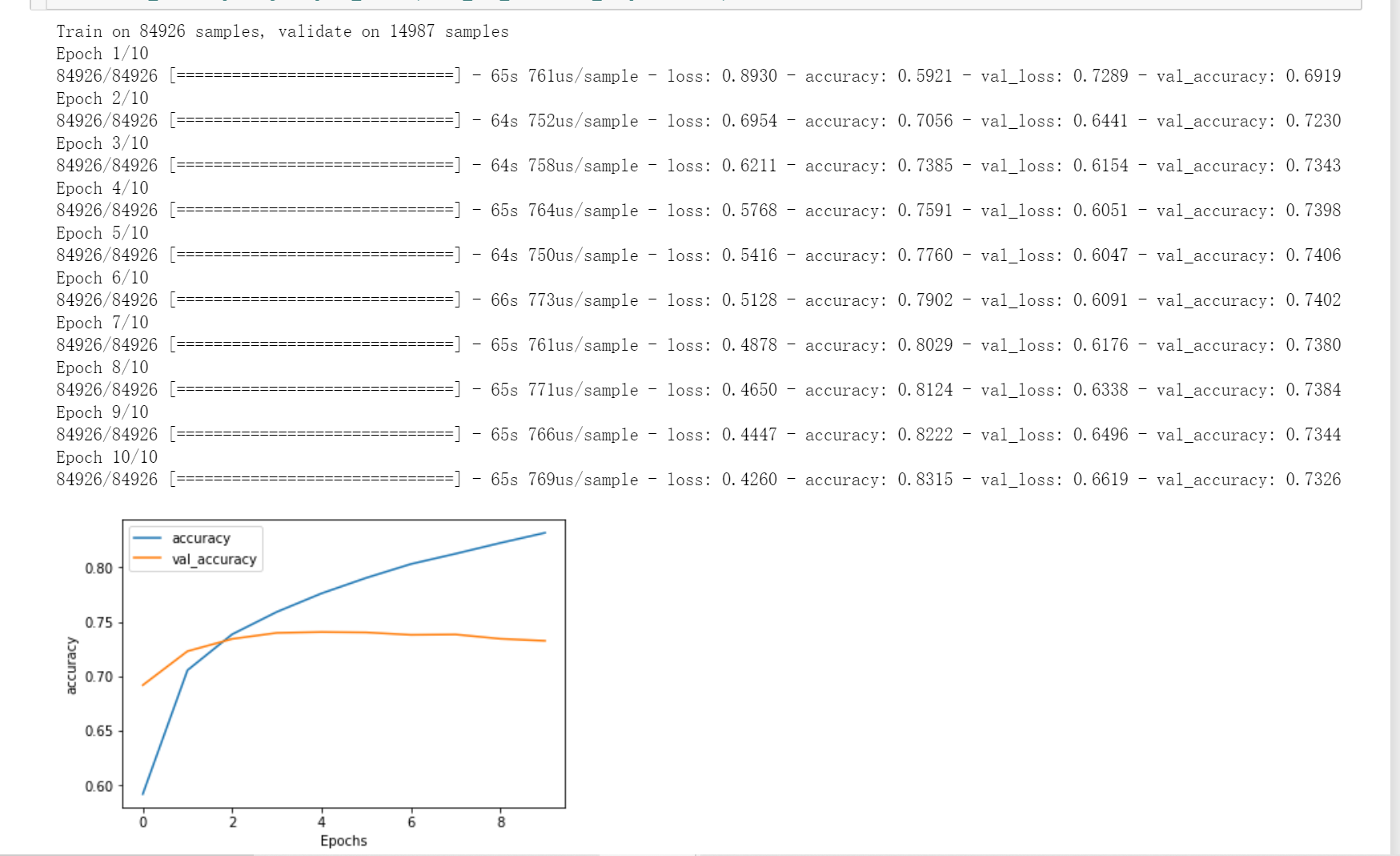
这个就迭代了10次,效果差~