面世即顶峰的bert
从结构入手
bert的两大任务:mask lm
next sentence prediction
BERT是” Bidirectional Encoder Representations from Transformers ”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),并且其设计了两个任务来预训练该模型。
- 第一个任务是采用MaskLM的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。类似于高中的完型填空有没有
Masked LM
Masked LM的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么,如下图所示。Adherer
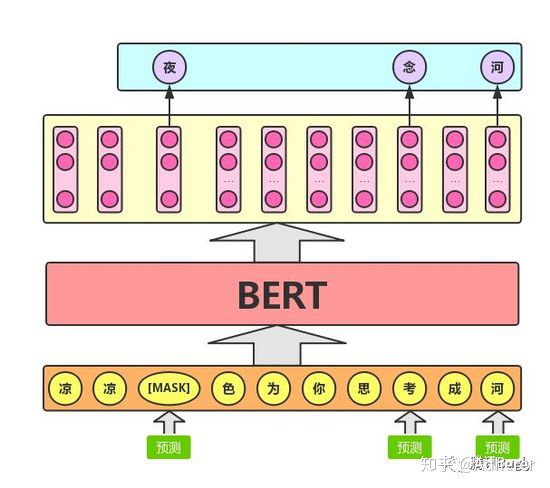
BERT 模型的这个预训练过程其实就是在模仿我们学语言的过程,思想来源于完形填空的任务。具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
Next Sentence Prediction
Next Sentence Prediction的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
- 第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入BERT的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。最后的实验表明BERT模型的有效性,并在11项NLP任务中夺得SOTA结果。BERT相较于原来的RNN、LSTM可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。Adherer

这个类似于段落重排序的任务,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。
Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
BERT是怎么用Transformer的?
之前面试被问到的一个问题:bert的双向transformer和双向LSTM的双向有什么不同?
非常的不同哈哈,那时候bert和transformer的结构都没有太理解,因此可以参考这里xsdn
bert的缺点
BERT只使用了Transformer的Encoder模块,原论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,分别是:

需要注意的是,与Transformer本身的Encoder端相比,BERT的Transformer Encoder端输入的向量表示,多了Segment Embeddings。