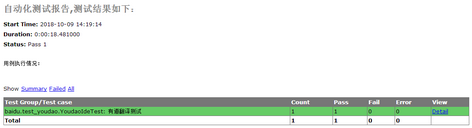
之前做过批量执行多.py文件,为了省时也做过单py文件多线程,现在做多py文件用例多线程
# coding:utf-8
import unittest
import os
import time
import HTMLTestRunner
from tomorrow import threads
# python2需要这三行,python3不需要
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# 用例路径
case_path = os.path.join(os.getcwd(), "case")#在现有路径(os.getcwd())下加个/case,找到case路径
# 报告存放路径
report_path = os.path.join(os.getcwd(), "report")
def all_case():
discover = unittest.defaultTestLoader.discover(case_path,
pattern="test*.py",
top_level_dir=None)#批量调用用例,参数分别是用例存放地址、用例名格式
return discover
@threads(3)
def run_case(all_case, report_path=report_path,nth=0):
'''执行所有的用例, 并把结果写入测试报告'''
now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
report_abspath = os.path.join(report_path, "result_"+now+".html")
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u'自动化测试报告,测试结果如下:',
description=u'用例执行情况:')
# 调用add_case函数返回值
runner.run(all_case)
fp.close()
if __name__ == "__main__":
# 用例集合
cases = all_case()
# 之前是批量执行,这里改成for循环执行
for i, j in zip(cases, range(len(list(cases)))):
run_case(i, nth=j) # 执行用例,生成报告
使用多线程之前用时35.7s:

使用之后网页并行打开执行用例,用时19s效果拔群
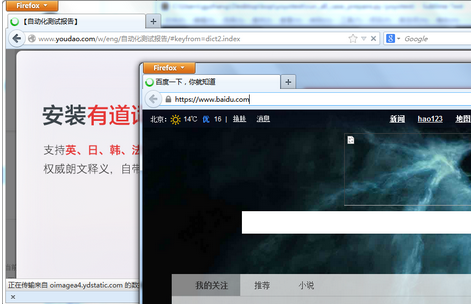

根据日期生成报告: