时间:JSong 时间:2018.01.14
文章很长,理论和实现都讲的很细,大家可以先收藏,有时间再看。
在上一篇文章中,我们对LendingClub的数据有了一个大致的了解,这次我将带大家把10万多条、145个字段的原始数据一步一步处理成建模所需输入的数据。
我们先按照上次一样导入数据,这里我将逾期15天以上的都当作正类
import pandas as pd
import numpy as np
import reportgen as rpt
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
# 字段的中文对照表,暂时只翻译了一部分
datadict=pd.read_excel('.\LendingClubData\LCDataDictionary.xlsx')
columnnew=dict(zip(datadict.loc[datadict['中文名称'].notnull(),'LoanStatNew'],datadict.loc[datadict['中文名称'].notnull(),'中文名称']))
data=pd.read_csv('.\LendingClubData\LoanStats_2016Q4.csv',skiprows=1)
data=data.rename(columns=columnnew)
data['target']=data['target'].replace({'Current':np.nan,'Fully Paid':0,'Charged Off':1,'Late (31-120 days)':1,'In Grace Period':np.nan,
'Late (16-30 days)':1,'Default':np.nan})
data=data.loc[data['target'].notnull(),:]
1、评分卡简介
在进行下一步操作之前,我们先来解构一下评分卡。
贷款机构(含银行、信用卡、互联网金融等)的主要目标之一是让贷款产生更多的利润,由于违约的存在,这里就需要在市场份额和利润之间做一个平衡。评分卡本质是在量化借款人的违约可能性,通过评分卡,我们能更好的把控这个平衡。
一般我们把逾期 n 天以上的称为坏人,反之是好人。贷款机构在全面掌握信息后,对借款人按时和按约定还款的可能性作出有洞见的预测。我们希望这些预测有更多区分度,而不是好人可能性高或低这么简单(每个机构的策略都不同,或保守或偏激,所以需要预测结果有足够区分度)。
令 X 是所有的特征数据(先验知识),G 是好人,B是坏人。给定相应数据 x ,有条件概率 p(G|x) 和 p(B|x)表示给定特征数据下好人和坏人的概率。
有时候我们更多的考虑事件的发生比率 :
由 Bayes 定理,我们可以得到:
其中f(x)表示申请者具有属性向量 x 的概率,p_G 和 p_B 表示先验知识中好人和坏人的概率, f(x|G) 和 f(x|B) 被称为似然函数,描述属性向量有多大可能性落在好和坏的群体中。把上述公式代入发生比率,还可得:
其中 o_{pop}=p_G/p_B 称为总体发生比率(population odds),I(x)称为信息比率,当其大于1时,表明属性x的借款人更可能是好人。
上述表达式其实就是Bayes 评分卡构建的所有理论了,其假设条件弱,应用范围广,但准确率不高。接下来我们会介绍逻辑回归等方法,这些方法只支持数值变量,不支持因子变量等,于是在建模之前,除了特征筛选外,我们还需要对数据进行编码。
2、特征工程
我把整个特征工程分为四个步骤
- 数据清洗(预处理)
- 特征衍生
- 特征编码
- 特征筛选
2.1 数据清洗
因为业务关系,我这里的预处理操作主要来源于知乎专栏 《风险狗的数据分析之路》。主要的预处理如下:
1、贷后的相关变量除了target变量,其余直接剔除,因为贷后表现在客户申请时是没有的,如果进入模型实际上就成了未来变量;2、缺失率太高的变量直接剔除,本文是按65%的阈值来剔除的;3、数值变量中所有值方差太小接近常量的变量剔除,因为不能提供更多信息;4、按业务逻辑完全不可解释的变量直接剔除,5、分类变量中unique值大于20的直接剔除。
先剔除与建模无关的变量(待最后一步来操作)
# 实际执行顺序放在特征衍生的后面
var_drop=list(set(data.columns) & set(datadict.loc[datadict['类别'].isnull(),'LoanStatNew']))
data=data.drop(var_drop,axis=1)
剔除缺失率过高的变量
# 去除缺失率大于65%的字段
thr=0.65
missing_pct=data.apply(lambda x : (len(x)-x.count())/len(x))
data=data.loc[:,missing_pct[missing_pct<thr].index]
# 另也可以直接用下面这种方法
#data=data.dropna(thresh=len(data) * thr,axis=1)
剔除unique值过少或过多的变量
# 每个字段的unique数目
nunique=data.apply(pd.Series.nunique)
data=data.loc[:,nunique!=1]
#log=[is_numeric_dtype(data[c].dtype) or nunique[c]<20 for c in data.columns]
#data=data.loc[:,log]
缺失值处理
涉及到实现上的一些处理,我们放在第三步中处理
# 实际执行顺序在 WOE 编码前
# 缺失值处理
# 对于连续变量,这里我们随意填入
for v in continuous_var:
s=list(data[v].dropna().unique())
data[v]=data[v].map(lambda x : np.random.choice(s,1)[0] if pd.isnull(x) else x)
# 也可以直接用
#from sklearn.preprocessing import Imputer
#data.loc[:,continuous_var]=Imputer(strategy='mean').fit_transform(data.loc[:,continuous_var])
# 对于因子变量,这里我们填入众数
for v in categorical_var:
s=data[v].value_counts().argmax()
data[v]=data[v].fillna(s)
data=data.reset_index(drop=True)#便于后续数据处理,不解释
data0=data.copy()#备份用
无量纲化
- 标准化:
- 极差化
# 此处只作为演示用,不实际操作
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
tmp=StandardScaler().fit_transform(data.select_dtypes(include=['float64']))
tmp=MinMaxScaler().fit_transform(data.select_dtypes(include=['float64']))
2.2 特征衍生
data['放款日期']=pd.to_datetime(data['放款日期'])
data['信用报告最早日期']=pd.to_datetime(data['信用报告最早日期'])
data['days']=(data['放款日期']-data['信用报告最早日期']).map(lambda x:x.days)
data=data.drop(['放款日期','信用报告最早日期'],axis=1)
2.3 特征编码的理论介绍
我把特征的类型分为五种:
| 类型 | 名称 | 描述 |
|---|---|---|
| number | 连续变量 | 数值型,例如收入、贷款金额等 |
| category | 因子变量 | 数值或者字符串,例如学历、年龄、基础等级等 |
| datetime | 时间变量 | 日期和时间,例如放款日期等 |
| text | 文本变量 | 字符串,例如产品评论等 |
| text_st | 结构化文本变量 | 例如样本的ID等,需要剔除或者再处理的变量 |
自己写了一个函数 type_of_var ,放在工具箱 reportgen 中用来识别变量的类型
# 此处category_detection 设为False,所有数值类型全部当成连续变量
VarType=rpt.analysis.type_of_var(data,category_detection=False)
VarType=pd.Series(VarType)
continuous_var=list(VarType[VarType=='number'].index)
continuous_var.remove('target')
print('连续变量有:
',' , '.join(continuous_var))
categorical_var=list(VarType[VarType=='category'].index)
print('因子变量有:
',' , '.join(categorical_var))
datetime_var=list(VarType[VarType=='datetime'].index)
print('时间变量有:
',' , '.join(datetime_var))
text_var=list(VarType[VarType=='text'].index)
print('文本变量有:
',' , '.join(text_var))
输出如下:
>连续变量有:
>bc_open_to_buy , bc_util , days , mo_sin_old_il_acct , mo_sin_old_rev_tl_op , mo_sin_rcnt_tl , mths_since_last_delinq , mths_since_recent_bc , num_accts_ever_120_pd , num_actv_rev_tl , num_bc_sats , num_il_tl , num_rev_accts , num_rev_tl_bal_gt_0 , num_sats , num_tl_30dpd , num_tl_90g_dpd_24m , num_tl_op_past_12m , pct_tl_nvr_dlq , percent_bc_gt_75 , tot_cur_bal , tot_hi_cred_lim , total_bal_ex_mort , total_bc_limit , total_rev_hi_lim , 冲销数量 , 年收入 , 总贷款笔数 , 总贷款金额 , 月负债比 , 过去24个月的交易数目。 , 过去6个月内被查询次数 , 银行卡帐号数目
>因子变量有:
>房屋所有权
特征编码的对象包含因子变量和连续变量,对于连续变量,主要有如下几种方式
2.3.1 标准化
就是上文讲的无量纲化
2.3.2 二值化
首先设定一个阈值,大于阈值的设为1,否则设为0
# 不做演示,不实际执行
from sklearn.preprocessing import Binarizer
Binarizer_var=[]
Binarizer(threshold=3).fit_transform(data.loc[:,Binarizer_var])
2.3.3 特征分箱
特征分箱包含将连续变量离散化和将多状态的离散变量合并成少状态。
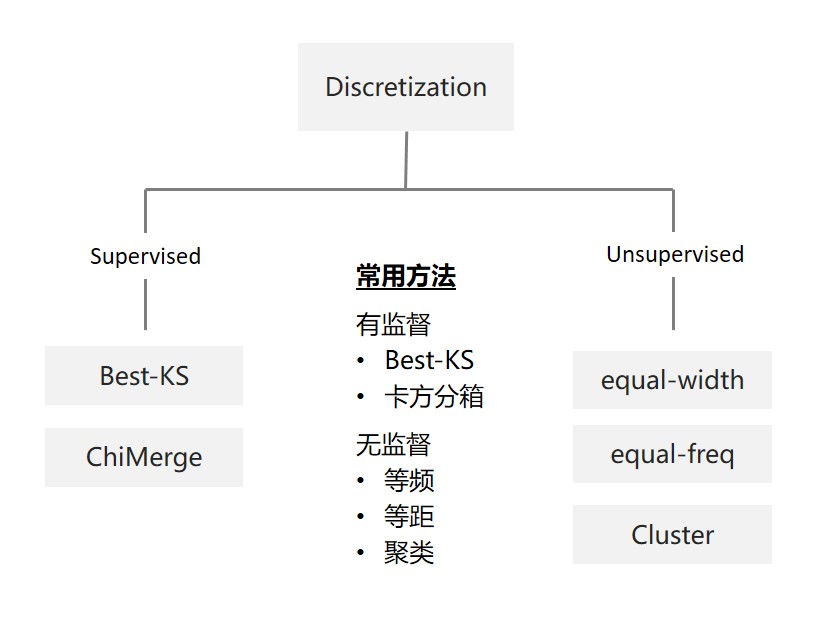
这里我们只介绍卡方分箱(ChiMerge)
自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想:对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
详细的分箱算法如下:

它们的Python实现方法如下:
# 只做演示,不实际执行
# 卡方分箱
from reportgen.utils import Discretization
dis=Discretization(method='chimerge',max_intervals=20)
dis.fit_transform(x,y)
# 等距分箱
pd.cut(x,bins=10)
# 等频分箱
pd.qcut(x,bins=10)
对于因子变量,主要有如下几种方式
2.3.4 LabelEncoder
这个比较简单,就是直接将整数来替换类别,例如在性别中用 1 替换男,用 2 替换女
# 只做演示,不实际执行
from sklearn.preprocessing import LabelEncoder
LabelEncoder().fit_transform(data.loc[:,categorical_var])
2.3.5 哑编码
哑编码是一种状态编码,属于一对多的特征映射。简单点讲,它将性别映射为两个变量:是否是男性、是否是女性。它解决了 LabelEncoder 中序的问题,比如在 LabelEncoder 中,女性用2表示,但明显不可能是2倍的男性。这里提供两种哑编码的实现方法,pandas和sklearn。它们最大的区别是,pandas默认只处理字符串类别变量,sklearn默认只处理数值型类别变量(需要先 LabelEncoder )
# 只做演示,不实际执行
# pandas 的方法,drop_first 是为了防止共线性
pd.get_dummies(data.loc[:,categorical_var],prefix=categorical_var,drop_first=True)
# sklearn 的方法
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
Enc_ohe, Enc_label = OneHotEncoder(), LabelEncoder()
Enc_ohe.fit_transform(Enc_label.fit_transform(data.loc[:,categorical_var]))
2.3.6 WOE编码
在第一节中我们介绍了 总体发生比率 和 信息比率:
前者反映了还没有任何关于借款人的已知信息时,我们对该借款人是好人的可能性认知。后者很好的度量了借款人信息对好人可能性的贡献程度,其自然对数 ln(I(x)) 是评估向量x携带信息的一种有效途径,我们将这个数值称之为 x 提供的证据权重(weights of evidence,WOE)
如果一个特征有K个类别,且用(g_k)和(b_k)表示第k类中好人和坏人的数量,用(n_G)和(n_B)表示好人和坏人的数量,则 WOE 可以表示为:
WOE的值越大代表对应的变量对“是好人”的贡献就越大,反之,越小就代表对应的变量对“是坏人”的贡献越大。所以WOE值可以作为特征的一种编码方式。
from reportgen.utils import WeightOfEvidence
woe_iv={}# 用于之后的特征选择
for v in categorical_var:
woe=WeightOfEvidence()
woe.fit(data[v],data['target'])
data[v]=woe.transform(data[v])
2.4 特征编码
LendingClub 的数据类型很多,理论上讲它的特征编码有很多种组合方式,比如
- 因子变量哑变量,连续变量标准化
- 因子变量WOE编码,连续变量标准化
- 连续变量离散后再WOE编码,同时因子变量 WOE 编码
不过为了节省篇幅,这里我们采用最后一种方式,全部 WOE 编码。其代码如下
from reportgen.utils import WeightOfEvidence
from reportgen.utils import Discretization
max_intervals=8
N=len(data)
woe_iv={}# 用于之后的特征选择
for v in categorical_var:
# 如果因子数过多,则先进行分箱
if not(isinstance(data[v].iloc[0],str)) and len(data[v].unique())>20:
dis=Discretization(method='chimerge',max_intervals=max_intervals)
dis.fit(data[v],data['target'])
data.loc[:,v]=dis.transform(data[v])
woe=WeightOfEvidence()
woe.fit(data[v],data['target'])
woe_iv[v]={'woe':woe.woe,'iv':woe.iv}
data[v]=data[v].replace(woe.woe).astype(np.float64)
for v in continuous_var:
if len(data[v].unique())>max_intervals:
dis=Discretization(method='chimerge',max_intervals=max_intervals,sample=1000)
dis.fit(data[v],data['target'])
data.loc[:,v]=dis.transform(data[v])
woe=WeightOfEvidence()
woe.fit(data[v],data['target'])
woe_iv[v]={'woe':woe.woe,'iv':woe.iv}
data[v]=data[v].replace(woe.woe).astype(np.float64)
2.5 特征选择的理论介绍
特征选择的标准是该特征与目标的相关性,与目标相关性高的特征,应当优选择。按照选择形式可以将特征选择的方法分为三种:
- 过滤法,按照相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- 包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- 嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
除此之外,还有一个需要处理的是共线性问题。
2.5.1 Filter:卡方统计量
卡方检验常用于两个变量之间的显著性检验,假定fo、fe分别为观察频数和期望频数,则卡方统计量的计算公式为:
当我们计算了所有变量的卡方统计量后,可以用p值来筛选变量,也可以用衍生的V相关系数来筛选:
其中R代表列联表的行数,C代表列联表的列数。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#from reportgen.utils import chi2
#选择K个最好的特征,返回选择特征后的数据
# sklearn 的chi2只支持两个类别的特征,建议换成reportgen中的chi2
SelectKBest(chi2, k=2).fit_transform(X, y)
2.5.2 Filter:信息量(Info Value, IV)
如果想考察某个特征区分好坏借款人的表现,我们可以用该特征的均值之差来表示
然而这个差并没有考虑到某些x值的信息量远高于其他的情况,于是我们可以用权重之差来判断
这被称为散度,也类似于相对熵(进行了对称处理)。将散度离散化便得到信息量(IV) . 如果一个特征有K个类别,且用(g_k)和(b_k)表示第k类中好人和坏人的数量,用(n_G)和(n_B)表示好人和坏人的数量,则 IV 可以表示为:
一般IV值越大,该特征越要保留。
from reportgen.utils import WeightOfEvidence
woe=WeightOfEvidence()
woe.fit(x,y)
iv=woe.iv
注:卡方统计量和熵的关系
注意到卡方统计量等价于:
而 fo/N 可以看成是联合分布的概率,fe/N 可以看成是乘积分布的概率,又
所有我们有
从这个角度来看,卡方距离是 p(x,y) 和 p(x)p(y) 之间信息量的某种近似。
2.5.3 Wrapper:递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe=RFE(estimator=LogisticRegression(),n_features_to_select=2)
rfe.fit_transform(X, y)
2.5.4 Embedded: 基于分类模型的特征选择法
使用基模型,除了筛选出特征外,同时也进行了降维。这里我们用sklearn中的SelectFromModel来完成。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
#带L1惩罚项的逻辑回归作为基模型的特征选择
sf=SelectFromModel(LogisticRegression(penalty="l1",C=0.1))
sf.fit_transform(X, y)
#树模型中GBDT也可用来作为基模型进行特征选择,
from sklearn.ensemble import GradientBoostingClassifier
sf=SelectFromModel(GradientBoostingClassifier())
sf.fit_transform(X,y)
2.5.5 共线性问题
详见我的文章
2.6 特征选择
由于我们上一步采用的是 WOE 编码,所以这里选用信息量 IV 作为准则。
iv_threshould=0.005
varByIV=[k for k,v in woe_iv.items() if v['iv'] > iv_threshould]
print('剩余%d个变量'%len(varByIV))
print(varByIV)
X=data.loc[:,varByIV]
y=data['target']
输出结果如下:
剩余28个变量
['月负债比', 'tot_hi_cred_lim', 'bc_util', 'mths_since_last_delinq', '年收入', 'num_actv_rev_tl', 'bc_open_to_buy', 'total_rev_hi_lim', 'num_tl_90g_dpd_24m', '银行卡帐号数目', 'num_rev_tl_bal_gt_0', 'tot_cur_bal', '冲销数量', 'mo_sin_old_rev_tl_op', 'total_bc_limit', 'percent_bc_gt_75', 'pct_tl_nvr_dlq', '房屋所有权', '总贷款金额', 'num_rev_accts', '过去24个月的交易数目。', 'num_tl_op_past_12m', '过去6个月内被查询次数', 'mo_sin_rcnt_tl', 'mths_since_recent_bc', '总贷款笔数', 'mo_sin_old_il_acct', 'days']
至于共线性问题,简单点可以线看一下条件数,用于检测是否存在共线性,然后再用岭回归来确定需要剔除的变量
print('条件数 = %.3f'%np.linalg.cond(X))
# 输出为:条件数 = 8.682
条件数很小,一般至少要大于100才说明存在共线性。如果不放心的话,还可以看看岭回归的岭迹:
from sklearn.linear_model import Ridge
plt.figure()
n_alphas = 20
alphas = np.logspace(-1,4,num=n_alphas)
coefs = []
for a in alphas:
ridge = Ridge(alpha=a, fit_intercept=False)
ridge.fit(X2, y)
coefs.append(ridge.coef_)
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
handles, labels = ax.get_legend_handles_labels()
plt.legend(labels=labels)
plt.show()
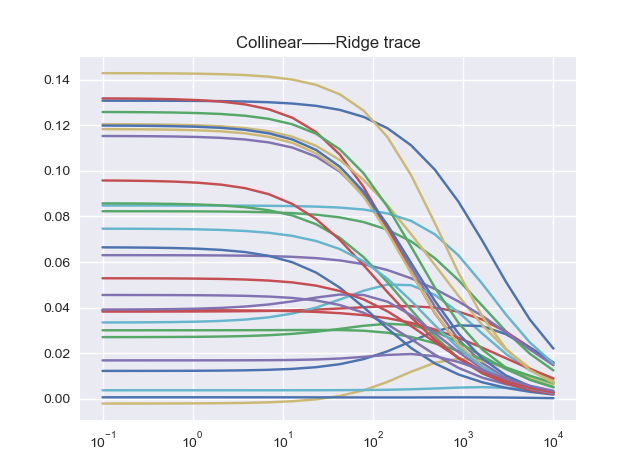
可以看出所有的特征都很稳定,不存在波动。
3、建模
本文对模型部分不做详细介绍,都用默认参数。详细可参见 JSong 的公众号文章一切从逻辑回归开始
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import auc,roc_curve
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
lr=LogisticRegression()
lr.fit(X_train,y_train)
y_train_proba=lr.predict_proba(X_train)
y_train_label=lr.predict(X_train)
y_test_proba=lr.predict_proba(X_test)
y_test_label=lr.predict(X_test)
from sklearn.metrics import accuracy_score
print('训练集准确率:{:.2%}'.format(accuracy_score(y_train_label,y_train)))
print('测试集准确率:{:.2%}'.format(accuracy_score(y_test_label,y_test)))
# ROC曲线和KS统计量
fpr, tpr, thresholds=roc_curve(y_train,y_train_proba[:,1],pos_label=1)
auc_score=auc(fpr,tpr)
w=tpr-fpr
ks_score=w.max()
ks_x=fpr[w.argmax()]
ks_y=tpr[w.argmax()]
fig,ax=plt.subplots()
ax.plot(fpr,tpr,label='AUC=%.5f'%auc_score)
ax.set_title('Receiver Operating Characteristic')
ax.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6))
ax.plot([ks_x,ks_x], [ks_x,ks_y], '--', color='red')
ax.text(ks_x,(ks_x+ks_y)/2,' KS=%.5f'%ks_score)
ax.legend()
fig.show()
#密度函数和KL距离
kl_div_score1=rpt.utils.entropyc.kl_div(y_train_proba[y_train==0,0],y_train_proba[y_train==1,0])
kl_div_score2=rpt.utils.entropyc.kl_div(y_train_proba[y_train==1,0],y_train_proba[y_train==0,0])
kl_div_score=kl_div_score1+kl_div_score2
fig,ax=plt.subplots()
sns.distplot(y_train_proba[y_train==0,0],ax=ax,label='good')
sns.distplot(y_train_proba[y_train==1,0],ax=ax,label='bad')
ax.set_title('KL_DIV = %.5f'%kl_div_score)
ax.legend()
fig.show()
输出结果如下
训练集准确率:72.44%
测试集准确率:72.51%
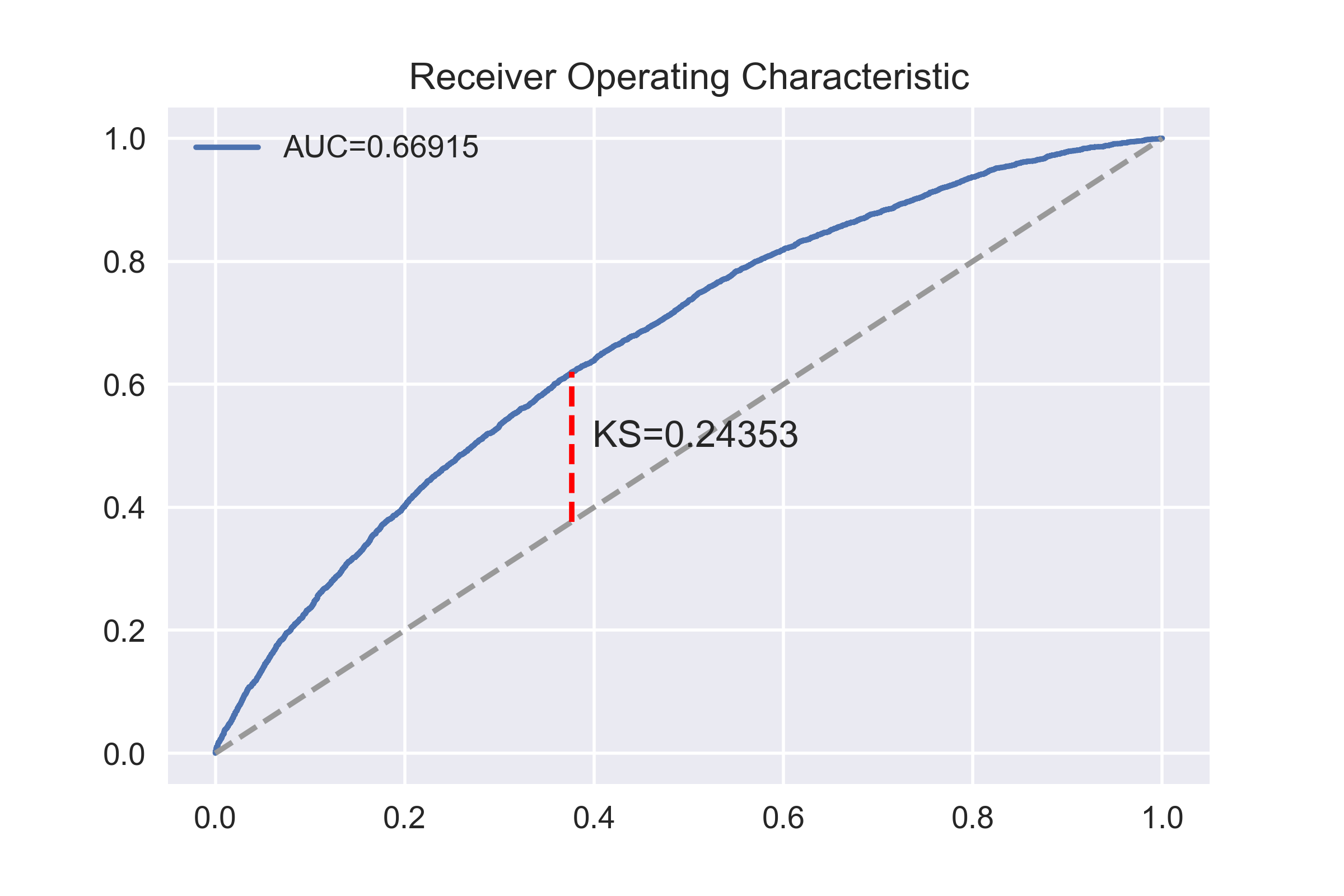
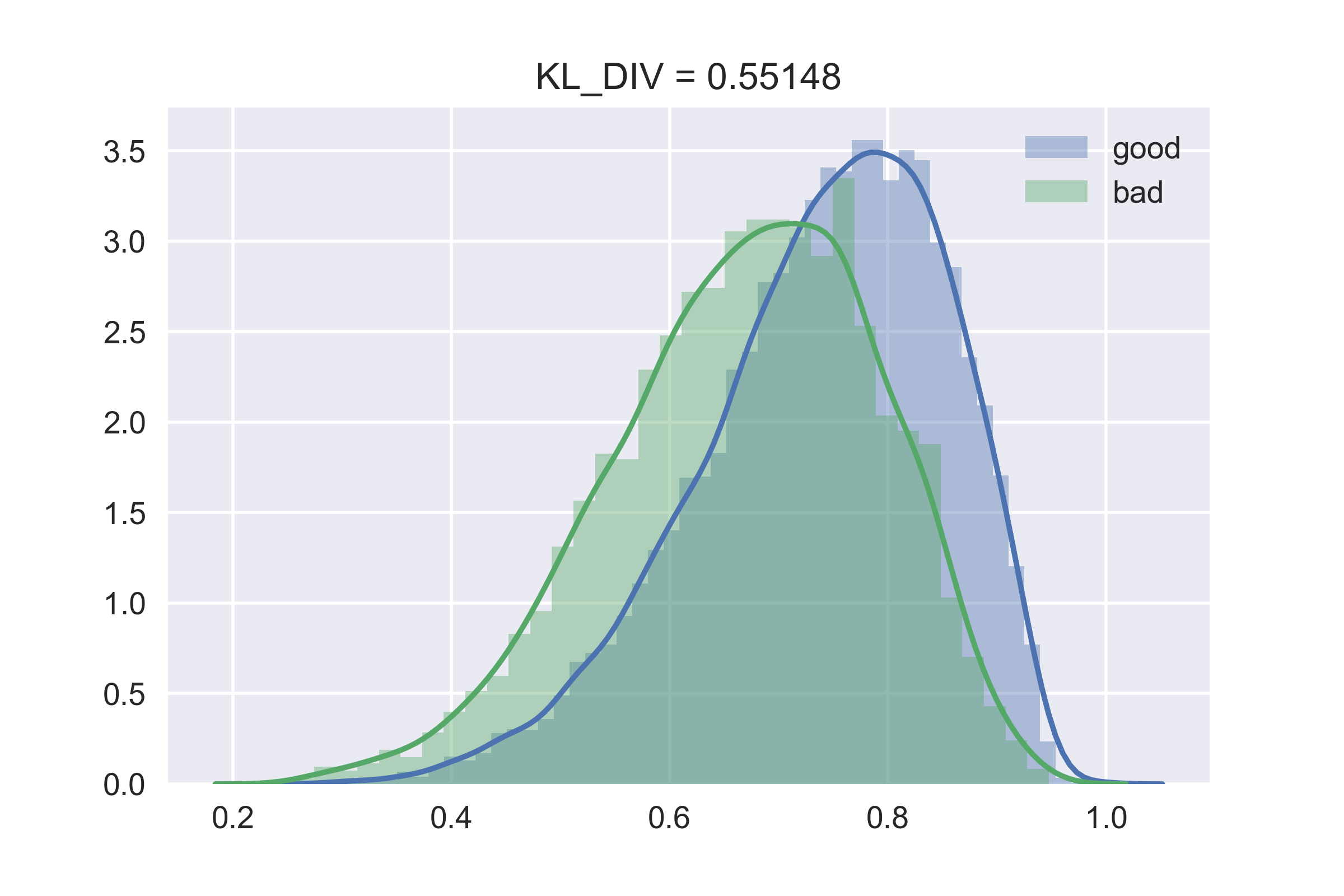
可以看到结果不太好,没事,后面我们会慢慢提高它的。本文的代码,如果不想一段一段复制,也可以后台回复:数据集 下载。
评分卡文章系列:
个人公共号,文章首发于此。转载请联系。
