概述
本lab将实现一个锁管理器,事务通过锁管理器获取锁,事务管理器根据情况决定是否授予锁,或是阻塞等待其它事务释放该锁。
背景
事务属性
众所周知,事务具有如下属性:
- 原子性:事务要么执行完成,要么就没有执行。
- 一致性:事务执行完毕后,不会出现不一致的情况。
- 隔离性:多个事务并发执行不会相互影响。
- 持久性:事务执行成功后,所以状态将被持久化。
一些定义
将对数据对象Q的操作进行抽象,read(Q):取数据对象Q,write(Q)写数据对象Q。
schedule
考虑事务T1,T1从账户A向账户B转移50。
T1:
read(A);
A := A - 50;
write(A);
read(B);
B := B + 50;
write(B).
事务T2将账户A的10%转移到账户B。
T2:
read(A);
temp := A * 0.1;
A := A - temp;
write(A);
read(B);
B := B + temp;
write(B).
假设账户A、B初始值分别为1000和2000。
我们将事务执行的序列称为schedule。如下面这个schedule,T1先执行完,然后执行T2,最终的结果是具有一致性的。我们称这种schedule为serializable schedule。
T1 T2
read(A);
A := A - 50;
write(A);
read(B);
B := B + 50;
write(B).
read(A);
temp := A * 0.1;
A := A - temp;
write(A);
read(B);
B := B + temp;
write(B).
但是看下面这个shedule:
T1 T2
read(A);
A := A - 50;
read(A);
temp := A * 0.1;
A := A - temp;
write(A);
read(B);
write(A);
read(B);
B := B + 50;
write(B).
read(B);
B := B + temp;
write(B).
执行完账户A和B分别为950和2100。显然这个shecule不是serializable schedule。
考虑连续的两条指令I和J,如果I和J操作不同的数据项那么,这两个指令可以交换顺序,不会影响schedule的执行结果。如果I和J操作相同的数据项,那么只有当I和J都是read(Q)时才不会影响schedule的结果。如果两条连续的指令,操作相同的数据项,其中至少一个指令是write,那么I和J是conflict的。
如果schedule S连续的条指令I和J不conflict,我们可以交换它们执行的顺序,从而产生一个新的schedlue S',我们称S和S'conflict equivalent。如果S经过一系列conflict equivalent变换,和某个serializable schedule等价,那么我们称S是conflict serializable。
比如下面这个schedule S:
T1 T2
read(A);
write(A);
read(A);
write(A);
read(B);
write(B);
read(B);
write(B);
经过多次conflict equivalent变换,生成新的schedule S',S'是serializable schedule。
T1 T2
read(A);
write(A);
read(B);
write(B);
read(A);
write(A);
read(B);
write(B);
所以S是conflict serializable的。
two-phase locking
不对加解锁进行限制
前面提到多个事务并发执行的时候,可能出现数据不一致得情况。一个很显然的想法是加锁来进行并发控制。
可以使用共享锁(lock-S),排他锁(lock-X)。
问题来了。
在什么时候加锁?什么时候释放锁?
考虑下面这种加解锁顺序:
事务一从账户B向账户A转移50。
T1:
lock-X(B);
read(B);
B := B - 50;
write(B);
unlock(B);
lock-X(A);
read(A);
A := A + 50;
write(A);
unlock(A).
事务二展示账户A和B的总和。
T2:
lock-S(A);
read(A);
unlock(A);
lock-S(B);
read(B);
unlock(B);
display(A+B).
可能出现这样一种schedule:
T1 T2
lock-X(B);
read(B);
B := B - 50;
write(B);
unlock(B);
lock-S(A);
read(A);
unlock(A);
lock-S(B);
read(B);
unlock(B);
display(A+B).
lock-X(A);
read(A);
A := A + 50;
write(A);
unlock(A).
假设初始时A和B分别是100和200,执行后事务二显示A+B为250,显然出现了数据不一致。
我们已经加了锁,为什么还会出现数据不一致?
问题出在T1过早unlock(B)。
two-phase locking
这时引入了two-phase locking协议,该协议限制了加解锁的顺序。
该协议将事务分成两个阶段,
Growing phase:事务可以获取锁,但是不能释放任何锁。
Shringking phase:事务可以释放锁,但是不能获取锁。
最开始事务处于Growing phase,可以随意获取锁,一旦事务释放了锁,该事务进入Shringking phase,之后就不能再获取锁。
按照two-phase locking协议重写之前的转账事务:
事务一从账户B向账户A转移50。
T1:
lock-X(B);
read(B);
B := B - 50;
write(B);
lock-X(A);
read(A);
A := A + 50;
write(A);
unlock(B);
unlock(A).
事务二展示账户A和B的总和。
T2:
lock-S(A);
read(A);
lock-S(B);
read(B);
display(A+B).
unlock(A);
unlock(B);
现在无论如何都不会出现数据不一致的情况了。
two-phase locking正确性证明
课本的课后题15.1也要求我们证明two-phase locking(以下称2PL rule)的正确性。我看了下解答,用的是反正法。我还看到一个用归纳法证的,比较有趣。
前提:
- 假设T1, T2, ... Tn,n个事务遵循two-phase locking协议。
- Sn是T1, T2, ... Tn并发执行的一个schdule。
目标:
证明Sn是conflict serializable的schedule。
证明开始:
起始步骤,n = 1的情况:
T1遵守2PL rule。
S1这个schedule只包含T1。
显然S1是conflict serializable的schedule。
迭代步骤:
迭代假设:假设Sn-1是T1, T2, ... Tn−1形成的一个schedule,并且Sn-1是conflict serializable的schedule。我们需要证明Sn-1是conflict serializable的schedule,Sn也是conflict serializable的schedule。
假设Ui(•)是事务i的解锁操作,并且是schedule Sn中第一个解锁的操作:
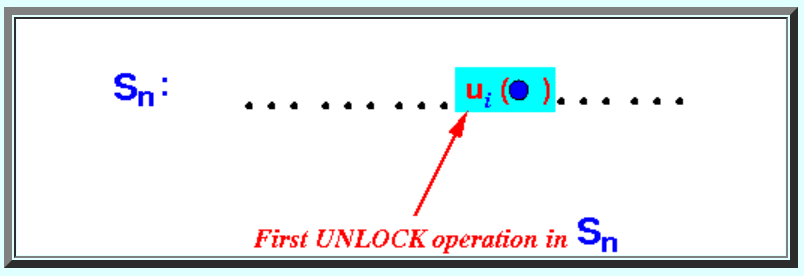
可以证明,我们可以将事务i所有ri(•) and wi(•)操作移到Sn的最前面,而不会引起conflict。
证明如下:
令Wi(Y)是事务i的任意操作,Wj(Y)是事务j的一个操作,并且和Wi(Y)conflict。等价于证明不会出现如下这种情况:
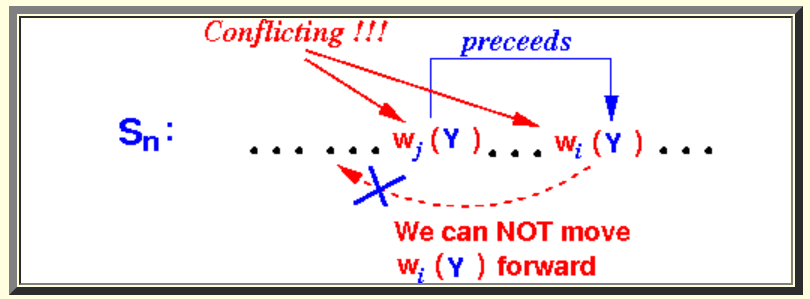
假设出现了这种情况,那么必然有如下加解锁顺序:
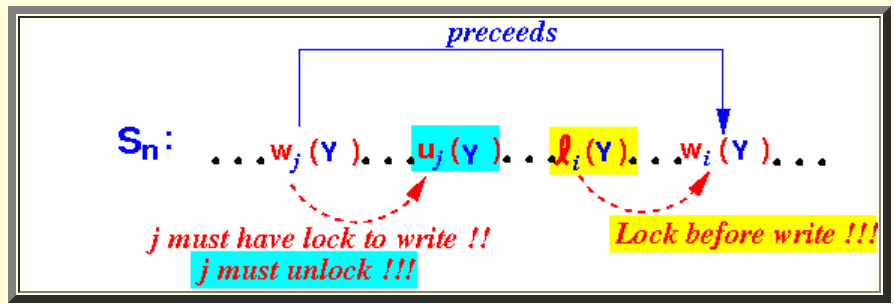
又因为所有事务都遵守2PL rule,所以必然有如下加解锁顺序:
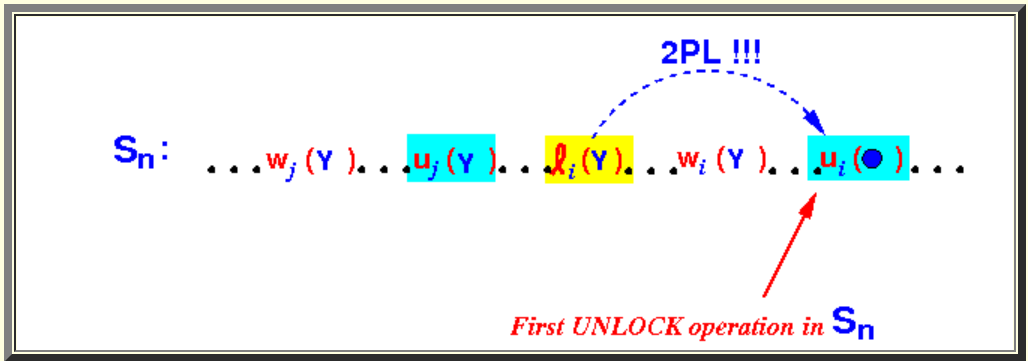
冲突出现了,Ui(•)应该是Sn中第一个解锁操作,但是现在却是Uj(Y)。所以假设不成立,所以结论:"我们可以将事务i所有ri(•) and wi(•)操作移到Sn的最前面,而不会引起conflict"成立。
我们将事务i的所有操作移到schedule最前面,
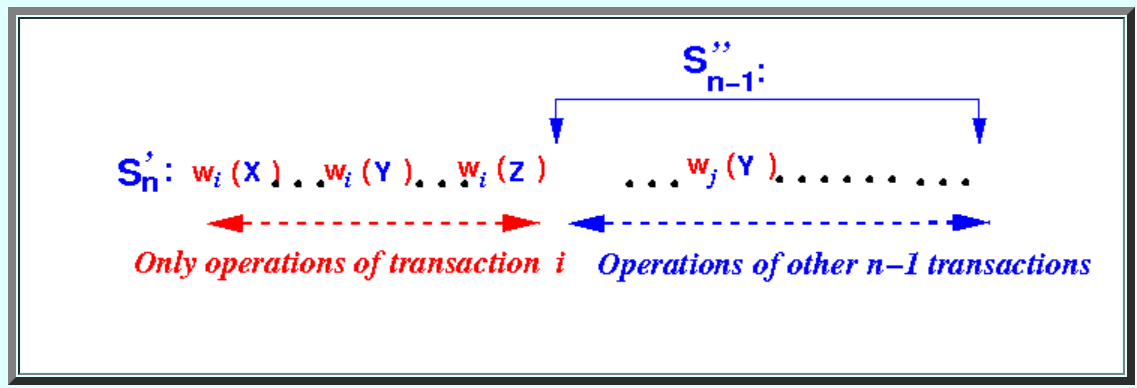
又因为Sn-1是conflict serializable的所以Sn是conflict serializable的。
证明完毕
two-phase locking不能保证不会死锁
two-phase locking可以保证conflict serializable,但可能会出现死锁的情况。
考虑这个schedule片段:
T1 T2
lock-X(B);
read(B);
B := B - 50;
write(B);
lock-S(A);
read(A);
lock-S(B);
lock-X(A);
T1和T2都遵循2PL rule,但是T2等待T1释放B上的锁,T1等待T2释放A上的锁,造成死锁。
死锁处理
有两类基本思路:
- 死锁预防,这类方法在死锁出现前就能发现可能导致死锁的操作。
- 死锁检测,这类方法定期执行死锁检测算法,看是否发生死锁,如果发生了,执行死锁恢复算法。
这里介绍wait-die这种死锁预防机制,该机制描述如下:
事务Ti请求某个数据项,该数据项已经被事务Tj获取了锁,Ti允许等待当且仅当Ti的时间戳小于Tj,否则Ti将被roll back。
wait-die正确性证明
为什么该机制能保证,不会出现死锁的情况呢?
如果Ti等待Tj释放锁,我们记Ti->Tj。那么系统中所有的事务将组成一个称作wait-for graph的有向图。容易证明:wait-for graph出现环和系统将出现死锁等价。
wait-die这种机制就能防止出现wait-for graph出现环。为什么?因为wait-die机制只允许时间戳小的等待时间戳大的事务,也就是说在wait-for graph中任意一条边Ti->Tj,Ti的时间戳都小于Tj,显然不可能出现环。所以不会出现环,也就不可能出现死锁。
事务管理器实现
事务管理器LockManager对外提供四个接口函数:
- LockShared(Transaction *txn, const RID &rid):事务txn希望获取数据对象rid的读锁,对应上述lock-S()。
- LockExclusive(Transaction *txn, const RID &rid):事务txn希望获取数据对象rid的写锁,对应上述的lock-X()。
- LockUpgrade(Transaction *txn, const RID &rid):将写锁升级为读锁。
- Unlock(Transaction *txn, const RID &rid):对应上述unloxk()。
可以用如下数据结构来实现:
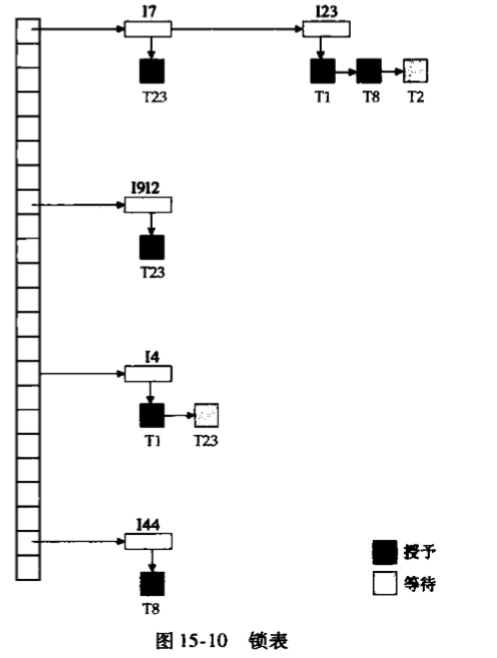
每个数据项对应一个链表,该链表记录请求队列。
当一个请求到来时,如果请求的数据项当前没有任何事务访问,那么创建一个空队列,将当前请求直接放入其中,授权通过。如果不是第一个请求,那么将当前事务加入队列,只有当前请求之前的请求和当前请求兼容,才授权,否则等待。
在哪里调用LockManager呢?
page/table_page.cpp中的TablePage类用于插入,删除,更新,查找表记录。在执行插入,删除,查找前都会获取相应的锁,确保多个事务同时操作相同数据项是安全的。
LockManager的具体代码可以参考我的手实现:https://github.com/gatsbyd/cmu_15445_2018
参考资料:
- http://www.mathcs.emory.edu/~cheung/Courses/554/Syllabus/7-serializability/2PL.html
- 《Database System concepts》 chapter 14, 15