下面介绍Elasticsearch的一些基本概念。从一开始就理解这些概念将极大地帮助简化学习过程。
1.1.近实时(NRT)
Elasticsearch是一个近实时搜索平台。这意味着从索引文档到可搜索文档的时间有一点延迟(通常是一秒)。
1.2.集群
集群是一个或多个节点(服务器)的集合,它们共同保存整个数据,并提供跨所有节点的联合索引和搜索功能。
集群由唯一名称标识(集群的名字),默认情况下为“elasticsearch”。
此名称很重要,因为如果节点设置为按名称加入群集,则同名的Elasticsearch节点会加入同一个集群。
确保不要在不同的环境中重用相同的集群名称,否则最终会导致节点加入错误的群集。例如,您可以使用logging-dev,logging-stage以及logging-prod 用于开发,生产集群。
请注意,拥有一个只包含单个节点的集群是完全正常的。
此外,您还可以拥有多个独立的集群,每个集群都有自己唯一的集群名称。
1.3.节点
节点是作为集群一部分的单个服务器(可以理解为单个Elasticsearch实例,一个进程),存储数据并参与集群的索引和搜索功能。
与集群一样,节点由名称标识,默认情况下,该名称是在启动时分配给节点的随机通用唯一标识符(UUID)。
如果不需要默认值,可以定义所需的任何节点名称。此名称对于管理目的非常重要,您可以在其中识别网络中的哪些服务器与Elasticsearch集群中的哪些节点相对应。
可以将节点配置为按群集名称加入特定群集。
默认情况下,每个节点都设置为加入一个名为cluster的集群elasticsearch,这意味着如果您在网络上启动了许多节点并且假设它们可以相互发现 - 它们将自动形成并加入一个名为的集群elasticsearch。(节点的集群名默认都是elasticsearch)
在单个群集中,您可以拥有任意数量的节点。
此外,如果您的网络上当前没有其他Elasticsearch节点正在运行,则默认情况下启动单个节点将形成一个名为elasticsearch的新单节点集群。
1.4.索引(index)
索引是具有某些类似特征的文档集合。
例如,您可以拥有客户数据的索引,产品目录的一个索引以及订单数据的一个索引。
索引由名称标识(索引名必须全部为小写),并且此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引。
在单个集群中,您可以根据需要定义任意数量的索引。
一个索引就相当于传统数据库中的一个数据库实例。
1.5.类型(type)
一种类型,曾经是索引的逻辑类别/分区,允许您在同一索引中存储不同类型的文档,例如一种类型用于用户,另一种类型用于博客帖子。
之后不再可能在索引中创建多个类型,并且将在更高版本中删除类型的整个概念。
type相当于传统数据库中的表,Elasticsearch已经将这个概念废弃,一个库(index)只有一张表(默认名为_doc)。所以我们的type统一使用_doc即可。避免以后升级兼容问题。
1.6.文档(document)
文档是可以索引的基本信息单元。
例如,您可以为单个客户提供文档,为单个产品提供另一个文档,为单个订单提供另一个文档。
该文档以JSON(JavaScript Object Notation)表示,JSON是一种普遍存在的互联网数据交换格式。
在索引/类型中,您可以根据需要存储任意数量的文档。
请注意,尽管文档实际上位于索引中,但实际上必须将文档分配给索引中的类型(如上所述,使用_doc)。
文档的概念相当于传统数据库中的数据行(record),只是recode是结构化的,字段确定,文档中的字段不确定,字段数量也不确定。适合非结构化数据存储。
1.6.1.文档元数据
文档是描述用户感知关心的数据的,文档元数据是描述文档本身的。 三个必需的元数据元素如下:
_index- 文件存在的地方(索引名)
_type- 文档所代表的对象类(此概念已废弃,一般使用默认值 _doc)
_id- 文档的唯一标识符
1.7.分片和副本
索引可能存储大量可能超过单个节点的硬件限制的数据。
例如,占用1TB磁盘空间的十亿个文档的单个索引可能不适合单个节点的磁盘,或者可能太慢而无法单独从单个节点提供搜索请求。
为了解决这个问题,Elasticsearch提供了将索引细分为多个称为分片的功能。
创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
分片很重要,主要有两个原因:
- 它允许您水平分割/缩放内容量
- 它允许您跨分片(可能在多个节点上)分布和并行化操作,从而提高性能/吞吐量
分片的分布方式以及如何将文档聚合回搜索请求的机制完全由Elasticsearch管理,对用户来说是透明的。
在任何可能出现故障的网络/云环境中,强烈建议使用故障转移机制,以防分片/节点以某种方式脱机或因任何原因消失。
为此,Elasticsearch允许您将索引的分片的一个或多个副本制作成所谓的副本分片或简称副本。
副本很重要,主要有两个原因:
- 它在分片/节点出现故障时提供高可用性。因此,请务必注意,副本分片永远不会在与从中复制的原始/主分片相同的节点上分配。
- 它允许您扩展搜索量/吞吐量,因为可以在所有副本上并行执行搜索。
总而言之,每个索引可以拆分为多个分片。
索引也可以复制为零(表示没有副本)或更多次。复制后,每个索引都将具有主分片(原始分片)和副本分片(主分片的副本)。
可以在创建索引时为每个索引定义分片和副本的数量。创建索引后,您还可以随时动态更改副本数。
您可以使用_shrink和_splitAPI 更改现有索引的分片数,但这不是一项简单的任务,预先计划正确数量的分片是最佳方法。
默认情况下,Elasticsearch中的每个索引都分配了5个主分片和1个副本,这意味着如果群集中有超过两个节点,则一个索引将包含5个主分片和另外5个副本分片(1个完整副本),总计为每个索引10个分片。
LUCENE-5843,限制是2,147,483,519(= Integer.MAX_VALUE - 128)文档。您可以使用_cat/shardsAPI 监控分片大小。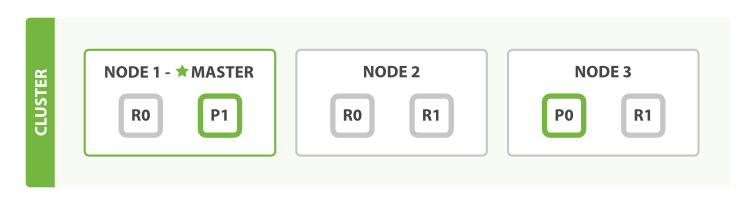
1.7.增加集群节点扩容过程
1.7.1 创建一个单节点的集群
这个节点内只创建了一个索引,设置的分片数为3,副本数为1
索引中的主分片数在创建索引时是固定的,但副本分片的数量可以随时更改。
curl -X PUT "localhost:9200/blogs" -H 'Content-Type: application/json' -d' { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } } '

1.7.2 增加一个节点(NODE2)
如下图表示当前是个两节点单索引的集群,每个节点(实际是指节点内的索引)有三个分片,每个分片有一个副本(注意,只要保持主分片和副本分片不在同一个节点上即可)。
任何新索引的文档将首先存储在主分片上,然后并行复制到关联的副本分片。这可确保可以从主分片或其任何副本中检索我们的文档。
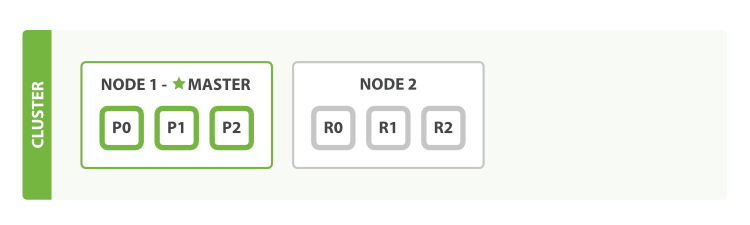
1.7.3 再增加一个节点NODE3
NODE1和NODE2上的部分节点迁移到NODE3上,这是Elasticsearch本身的负载均衡机制,平均分配分片位置,为了更好的利用资源。
分片本身就是一个完全成熟的搜索引擎(独立完整的lucene索引),能够使用单个节点的所有资源。
通过我们的总共六个分片(三个主分片和三个副本),我们的索引能够扩展到最多六个节点,每个节点上有一个分片,每个分片可以访问其节点资源的100%。

1.7.4 修改副本数量为2
curl -X PUT "localhost:9200/blogs/_settings" -H 'Content-Type: application/json' -d' { "number_of_replicas" : 2 } '
blogs索引现在有九个分片:三个主和六个副本。这意味着我们可以扩展到总共九个节点,每个节点再次使用一个分片。与原始的三节点集群相比,这将使我们的搜索性能提高 三倍。
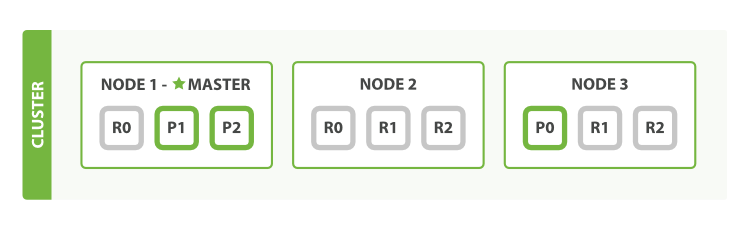
但是这些额外的副本确实意味着我们有更多的冗余:通过上面的节点配置,我们现在可以承受丢失两个节点而不会丢失任何数据。
1.8.故障恢复
下面杀死NODE1节点,集群状态如下:
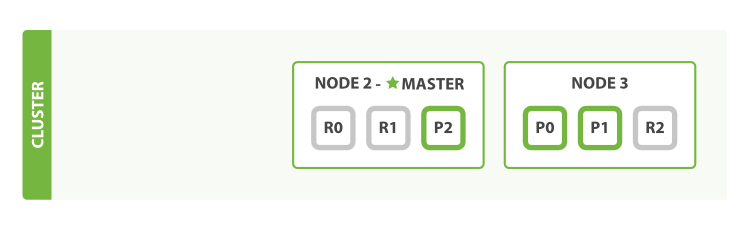
我们杀死的节点是主节点。集群必须具有主节点才能正常运行,因此首先发生的事情是节点选择了新的主节点:Node 2。
我们杀死Node 1时,主分片1和2丢失,如果缺少主分片,我们的索引将无法正常运行。 如果我们此时检查了群集运行状况,我们就会看到状态red:并非所有主分片都处于活动状态!
幸运的是,两个丢失的主分片的完整副本存在于其他节点,使新的主节点做的第一件事是提升Node 2,Node 3上的副本分片为主分片,把我们带回集群健康yellow。这个提升过程是即时的,就像打开开关一样。
那么为什么我们的集群健康yellow而不是green?我们有三个主分片,但我们指定我们想要每个主分片的两个副本,目前只分配了一个副本。
这会阻止我们到达 green,但我们在这里并不太担心:如果我们要杀死Node 2,我们的应用程序仍然可以继续运行而不会丢失数据,因为Node 3 包含每个分片的副本。
如果我们重新启动Node 1,集群将能够为其分配副本分片。如果Node 1仍然有旧分片的副本,它将尝试重用它们,从主分片中仅复制新更改的文件。