1. Page header(24Byte)
1.1. 描述
记录页头的信息。
1.2. get_raw_page函数
将指定表文件中的页面内容返回,param1:表名,param2:main/fsm/vm, param3:第几页
1.3. page_header(函数)
作用:
返回本页面中的page header信息。param1:get_raw_page函数的返回值。
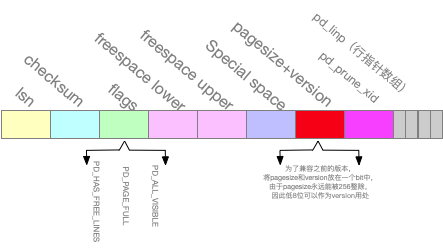
page的前24字节存储head data
字段:
lsn:记录最后一次对页修改的xlog记录
checksum:页面的校验和,用于判断当前页是否完整
flags:(指示当前页的状态)
lower:本页空闲位置的起始指针
uper:本业空闲位置的结束指针
special:页预留的位置
pagesize:页面大小
version:当前版本
prune_xid:最后一次删除或更新的xid
页后面存储的是元组(tuple)信息的数据(表的数据行,一个元组信息就是一行),也就是下一节的page item
1.4. 图解
2. Page item(页内存储的tuple数据)
一条数据(数据库行)由Item ID + Tuple Header + data(实际数据,由用户写入)组成。
Item Id和Page head存放在一起,存在页的一端,Tuple Header + data 存放在一起,存放在页的另一端。
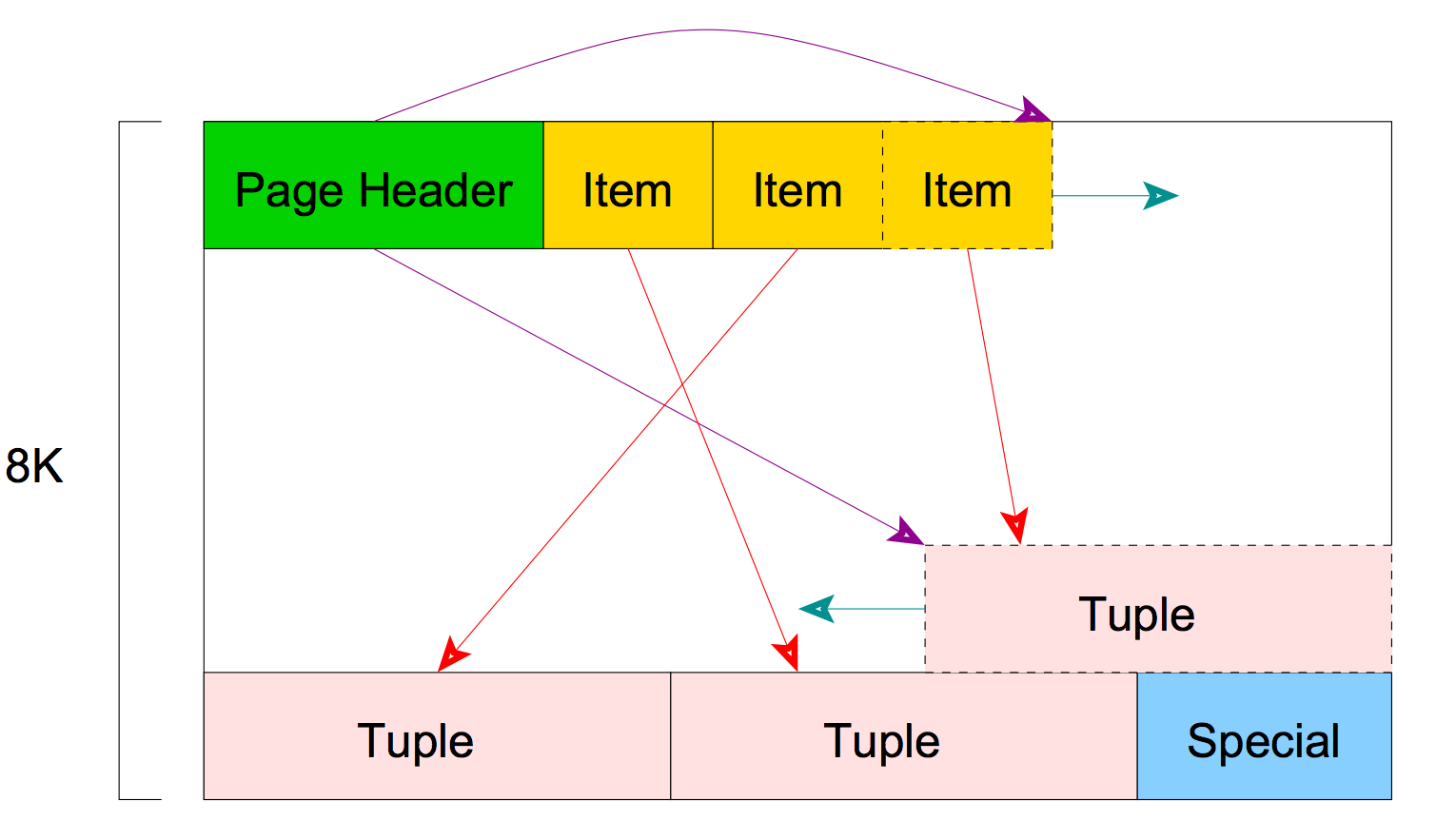
1.5. Item ID(行指针,4字节)

1.6. Tuple Header(元组头,23字节)
描述元组数据的数据,描述本条数据(数据库行)的状态,事物id等。
由于数据存储需要对齐(8的整数倍,整体对外长度为24字节),空行的长度为24字节。另外还有4字节的指针。即一条空行总共占用24+4=28字节。
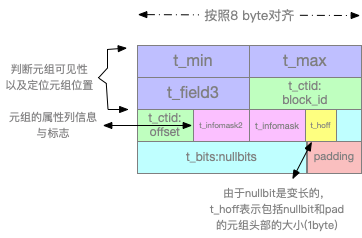
1.7. heap_page_items函数
显示堆页面上的所有行指针。param1:get_raw_page函数的返回值
lp:
lp_off: tuple在页面中的位置
lp_len:tuple的实际长度(tuple header + data,最终长度需要取整为8B的整数倍)
t_xmin,t_xmax: 插入,删除和更新时的事物id,插入时xmin写入当前事物id,删除时xmax写入事物id。更新也是先删除再插入
t_field3:
t_ctid:物理id,用于寻址数据在该页的位置(或者用于指向下一页索引)
1.8. 实战1-单条数据占用内存
l sql语句
drop table if EXISTS test1;
create table test1(id int);
--vacuum analyze test1;
insert into test1 values(1);
select * from page_header(get_raw_page('test1', 'main', 0));
insert into test1 values(2);
select * from page_header(get_raw_page('test1', 'main', 0));
insert into test1 values(300);
select * from page_header(get_raw_page('test1', 'main', 0));
select * from heap_page_items(get_raw_page('test1',0));
l 分析
通过下图可以看出,每插入一条int数据,lower增加4字节(item id是从页头开始写的,写在header的后面),upper减少32字节(tuple是从页尾开始写的,tuple header + data = 24 + 4 = 28,因为要取8的整数倍,所以为32字节)。
t_data存放的是数据的内容,注意下面标红的2c010000(实际是0X012c)对应值为300.
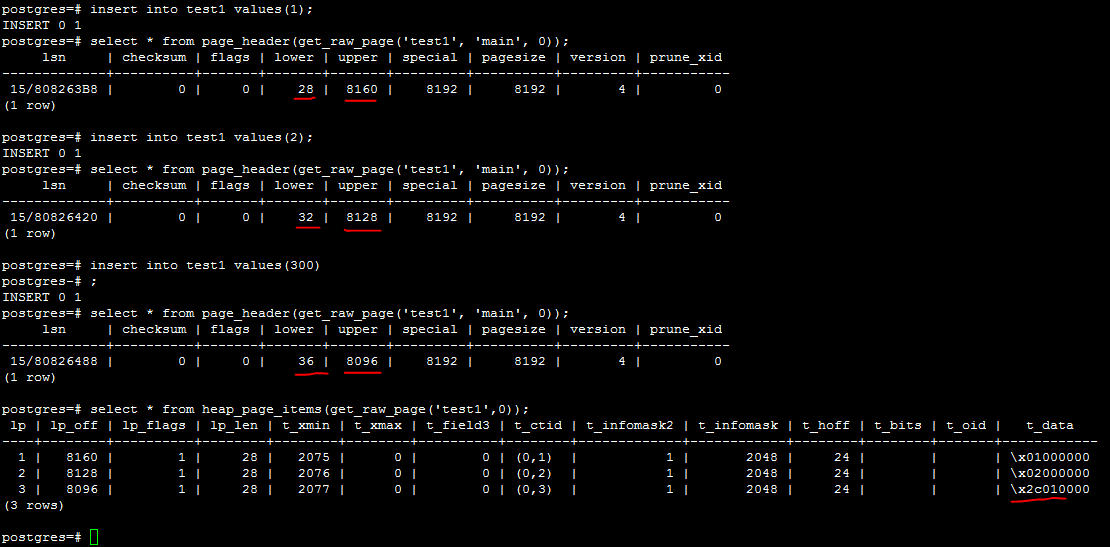
l 额外结论
根据上面的理论,目前来看,存储4字节的int和8字节的int消耗磁盘大小是一样的。(该定论局限于本表只有一个字段的情况下)
可以通过以下方式证明:
drop table if EXISTS test1;
create table test1(id char(7));
insert into test1 values('a');
select * from page_header(get_raw_page('test1', 'main', 0));
insert into test1 values('b');
select * from page_header(get_raw_page('test1', 'main', 0));
insert into test1 values('c');
select * from page_header(get_raw_page('test1', 'main', 0));
select * from heap_page_items(get_raw_page('test1',0));
说明:char的长度可以手动指定,char中的长度7实际占用8字节。
另外:
null字段不占用tuple中的空间
定长字段(int,char...)占用磁盘空间固定,和声明的一致
变长字段(varchar, text...)占用的磁盘空间由实际数据而定,而不是声明的长度。
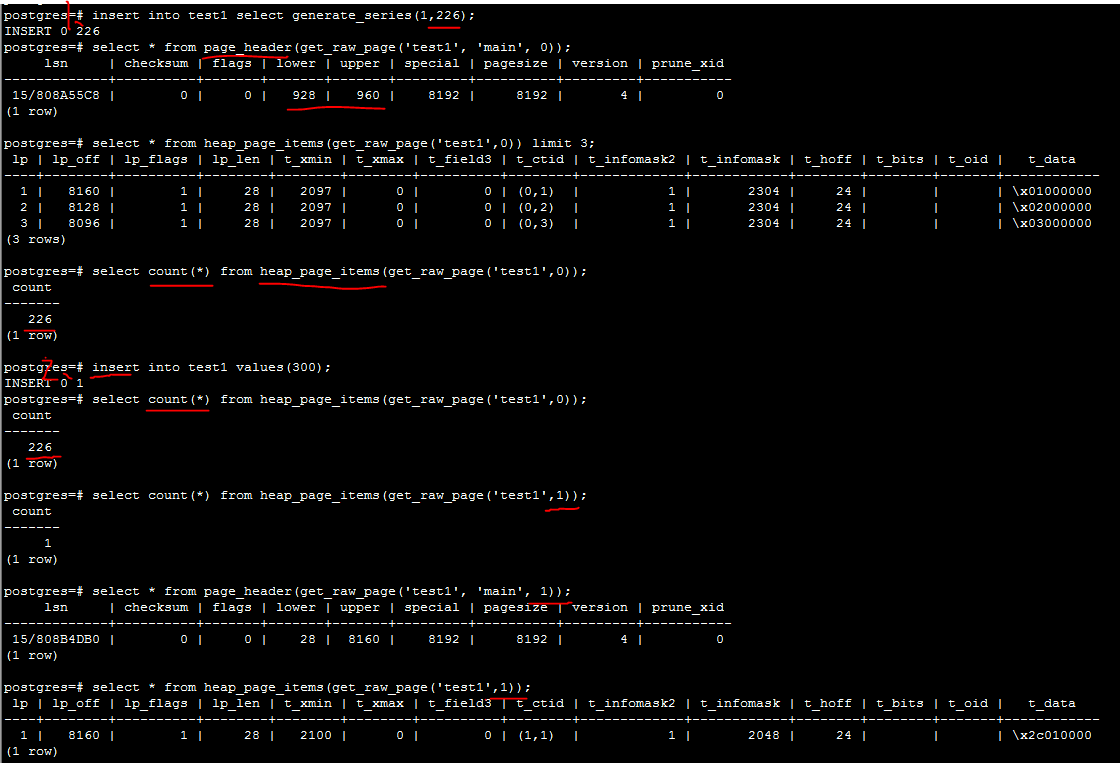
1.9. 实战2-计算单页的存储量(226行)
计算一页可以存储的单列int类型数据数量
l 已知
page页默认大小为8KB(8192字节)
page header 24字节
每插入一行,生成一个item id(4字节)和一个tuple(tuple header + data,共32字节)。
l 理论值
(8192-24)/ 36 = 226
(8192-24)% 36 = 32
所以理论上,一页可以存储226行只有一个int列的数据,属于空间大小为32B
l 测试sql
drop table if EXISTS test1;
create table test1(id int);
insert into test1 select generate_series(1,226);
select * from page_header(get_raw_page('test1', 'main', 0));
select * from heap_page_items(get_raw_page('test1',0));
select count(*) from heap_page_items(get_raw_page('test1',0));
insert into test1 values(300);
l 分析
插入226条数据后,通过page heaader查看upper-lower=32
通过page items查看第一页存在226条数据。
再插入一条,发现第一页还是226条数据,第二页有一条数据
说明第一页已经插满。
3. 存储结构
l 存储方式共有4种
•PLAIN :避免压缩和行外存储。
•EXTENDED :先压缩,后行外存储。
•EXTERNAL :允许行外存储,但不许压缩。
•MAIN :允许压缩,尽量不使用行外存储更贴切。
l 何时压缩Tuple数据
当Tuple大小超过大概2KB时,PostgreSQL会尝试基于LZ压缩算法进行压缩。
l 何时行外存储(TOAST)
行外存储toasted属性的本意是The Oversized-Attribute Storage Technique,对于某个超长的属性单独存储。当某行数据超过PostgreSQL页大小(8k)后,会将这个页放到系统命名空间pg_toast下的一个单独的表中,而在原表中存储一个TOAST pointer。
l 实战解读
create table tab3(id int primary key,info text);

备注:
https://www.postgresql.org/docs/current/storage-page-layout.html 官方文档