在Ubuntu上安装RabbitMQ
系统初始化
$ sudo apt update
$ sudo apt dist-upgrade
$ sudo apt autoremove
$ sudo apt clean
$ echo 127.0.0.1 mq > /etc/hosts
$ echo rabbitmq > /etc/hostname
$ export HOSTNAME=mq
搭建rabbitmq服务
$ echo 'deb http://www.rabbitmq.com/debian/ testing main'| sudo tee /etc/apt/sources.list.d/rabbitmq.list
$ wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add -
$ sudo apt-get update
$ sudo apt-get install rabbitmq-server
创建管理账户
$ sudo rabbitmqctl add_user test test
$ sudo rabbitmqctl add_vhost /test
$ sudo rabbitmqctl set_user_tags test administrator
$ sudo rabbitmqctl set_permissions -p /test test ".*" ".*" ".*"
$ sudo rabbitmq-plugins enable rabbitmq_management
AMQP规范
AMQP(高级消息队列协议)是一个网络协议。它支持符合要求的客户端应用(application)和消息中间件代理(messaging middleware broker)之间进行通信。
消息代理和他们所扮演的角色
消息代理(message brokers)从发布者(publishers)亦称生产者(producers)那儿接收消息,并根据既定的路由规则把接收到的消息发送给处理消息的消费者(consumers)。
由于AMQP是一个网络协议,所以这个过程中的发布者,消费者,消息代理 可以存在于不同的设备上。
AMQP 0-9-1 模型简介
AMQP 0-9-1的工作过程如下图:消息(message)被发布者(publisher)发送给交换机(exchange),交换机常常被比喻成邮局或者邮箱。然后交换机将收到的消息根据路由规则分发给绑定的队列(queue)。最后AMQP代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取。

队列,交换机和绑定统称为AMQP实体(AMQP entities)。
交换机和交换机类型
交换机是用来发送消息的AMQP实体。交换机拿到一个消息之后将它路由给一个或零个队列。它使用哪种路由算法是由交换机类型和被称作绑定(bindings)的规则所决定的。AMQP 0-9-1的代理提供了四种交换机
| Name(交换机类型) | Default pre-declared names(预声明的默认名称) |
|---|---|
| Direct exchange(直连交换机) | (Empty string) and amq.direct |
| Fanout exchange(扇型交换机) | amq.fanout |
| Topic exchange(主题交换机) | amq.topic |
| Headers exchange(头交换机) | amq.match (and amq.headers in RabbitMQ) |
除交换机类型外,在声明交换机时还可以附带许多其他的属性,其中最重要的几个分别是:
- Name
- Durability (消息代理重启后,交换机是否还存在)
- Auto-delete (当所有与之绑定的消息队列都完成了对此交换机的使用后,删掉它)
- Arguments(依赖代理本身)
交换机可以有两个状态:持久(durable)、暂存(transient)。持久化的交换机会在消息代理(broker)重启后依旧存在,而暂存的交换机则不会(它们需要在代理再次上线后重新被声明)。
队列
AMQP中的队列(queue)跟其他消息队列或任务队列中的队列是很相似的:它们存储着即将被应用消费掉的消息。
队列跟交换机共享某些属性,但是队列也有一些另外的属性。
- Name
- Durable(消息代理重启后,队列依旧存在)
- Exclusive(只被一个连接(connection)使用,而且当连接关闭后队列即被删除)
- Auto-delete(当最后一个消费者退订后即被删除)
- Arguments(一些消息代理用他来完成类似与TTL的某些额外功能)
队列在声明(declare)后才能被使用。如果一个队列尚不存在,声明一个队列会创建它。如果声明的队列已经存在,并且属性完全相同,那么此次声明不会对原有队列产生任何影响。如果声明中的属性与已存在队列的属性有差异,那么一个错误代码为406的通道级异常就会被抛出。
绑定
绑定(Binding)是交换机(exchange)将消息(message)路由给队列(queue)所需遵循的规则。
消费者
- 将消息投递给应用 ("push API")
- 应用根据需要主动获取消息 ("pull API")
消息确认
- 自动确认:当消息代理(broker)将消息发送给应用后立即删除。
- 显式确认:待应用(application)发送一个确认回执(acknowledgement)后再删除消息。
拒绝消息
当拒绝一条消息时,可以
- 销毁消息
- 重新放入消息队列
当此队列只有一个消费者时,请确认不要由于拒绝消息并且选择了重新放入队列的行为而引起消息在同一个消费者身上无限循环的情况发生。
Hello World
- 生产(Producing)的意思就是发送。发送消息的程序就是一个生产者(producer)。我们一般用"P"来表示:
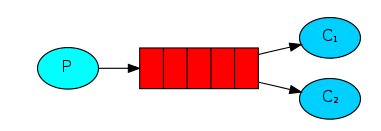
- 队列(queue)就是存在于RabbitMQ中邮箱的名称。虽然消息的传输经过了RabbitMQ和你的应用程序,但是它只能被存储于队列当中。实质上队列就是个巨大的消息缓冲区,它的大小只受主机内存和硬盘限制。多个生产者(producers)可以把消息发送给同一个队列,同样,多个消费者(consumers)也能够从同一个队列(queue)中获取数据。队列可以绘制成这样(图上是队列的名称):

- 在这里,消费(Consuming)和接收(receiving)是同一个意思。一个消费者(consumer)就是一个等待获取消息的程序。我们把它绘制为"C":
需要指出的是生产者、消费者、代理需不要待在同一个设备上;事实上大多数应用也确实不在会将他们放在一台机器上。
创建gradle项目,并配置build.gradle:
compile group: 'com.rabbitmq', name: 'amqp-client', version: '5.6.0'
创建生产者
public class Send {
private final static String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
// 1. 创建RabbitMQ连接工厂
ConnectionFactory factory = new ConnectionFactory();
// 2. 设置host,rabbitmq-server的监听地址
factory.setHost("localhost");
Connection connection = factory.newConnection();
// 4. 创建频道
Channel channel = connection.createChannel();
// 5. 连接到具体频道
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "Hello World!";
// 6. 发布消息
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
}
}
创建消费者
public class Recv {
private final static String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
// 4. 创建频道
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
};
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {
});
}
}
可以看出,生产者和消费者需要声明是同一个队列
测试
我们先执行Send.main,控制台将打印:
[x] Sent 'Hello World!'
然后执行Recv.main,控制台将打印:
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'Hello World!'
任务队列
工作队列(又称:任务队列——Task Queues)是为了避免等待一些占用大量资源、时间的操作。当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后处理。当你运行多个工作者(workers),任务就会在它们之间共享。
这个概念在网络应用中是非常有用的,它可以在短暂的HTTP请求中处理一些复杂的任务。
修改Send.java代码,来间隔10秒发送一个消息:
for (int i = 1; i <= 100; i++) {
String message = String.format("发送第%d条消息", i);
// 6. 发布消息
channel.basicPublish("", "hello", null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
Thread.sleep(10000);
}
修改Recv.java,来完成一个任务,这里,假装任务执行需要耗时1s:
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
try {
doWork(message);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(" [x] Done");
}
};
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {
});
private static void doWork(String task) throws InterruptedException {
for (char ch : task.toCharArray()) {
if (ch == '-') {
Thread.sleep(1000);
}
}
}
我们先开启Recv.java,然后开启Send.java,控制台将会打印
Send.java
[x] Sent '发送第1条消息'
[x] Sent '发送第2条消息'
[x] Sent '发送第3条消息'
Recv.java
[*] Waiting for messages. To exit press CTRL+C
[x] Received '发送第1条消息'
[x] Done
[x] Received '发送第2条消息'
[x] Done
[x] Received '发送第3条消息'
循环调度
使用工作队列的一个好处就是它能够并行的处理队列。如果堆积了很多任务,我们只需要添加更多的工作者(workers)就可以了,扩展很简单。
让我们尝试同时运行两个worker实例,他们都会从队列中获取消息:
Send.java
[x] Sent '发送第1条消息'
[x] Sent '发送第2条消息'
[x] Sent '发送第3条消息'
Recv.java-1
[*] Waiting for messages. To exit press CTRL+C
[x] Received '发送第1条消息'
[x] Done
[x] Received '发送第3条消息'
[x] Done
Recv.java-2
[*] Waiting for messages. To exit press CTRL+C
[x] Received '发送第2条消息'
[x] Done
默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。试着添加三个或更多得工作者(workers)。
消息确认
当处理一个比较耗时得任务的时候,你也许想知道消费者(consumers)是否运行到一半就挂掉。当前的代码中,当消息被RabbitMQ发送给消费者(consumers)之后,马上就会在内存中移除。这种情况,你只要把一个工作者(worker)停止,正在处理的消息就会丢失。同时,所有发送到这个工作者的还没有处理的消息都会丢失。
我们不想丢失任何任务消息。如果一个工作者(worker)挂掉了,我们希望任务会重新发送给其他的工作者(worker)。
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。
如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。
消息是没有超时这个概念的;当工作者与它断开连的时候,RabbitMQ会重新发送消息。这样在处理一个耗时非常长的消息任务的时候就不会出问题了。
消息响应默认是开启的。之前的例子中我们可以使用no_ack=True标识把它关闭。是时候移除这个标识了,当工作者(worker)完成了任务,就发送一个响应。
修改Worker.java
// 一次只接受一条消息
channel.basicQos(1);
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
try {
doWork(message);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
};
boolean autoAck = false;
channel.basicConsume(QUEUE_NAME, autoAck, deliverCallback, consumerTag -> {
});
运行上面的代码,我们发现即使使用CTRL+C杀掉了一个工作者(worker)进程,消息也不会丢失。当工作者(worker)挂掉这后,所有没有响应的消息都会重新发送。
消息持久化
如果你没有特意告诉RabbitMQ,那么在它退出或者崩溃的时候,将会丢失所有队列和消息。为了确保信息不会丢失,有两个事情是需要注意的:我们必须把“队列”和“消息”设为持久化。
首先,为了不让队列消失,需要把队列声明为持久化(durable):
boolean durable = true;
channel.queueDeclare(QUEUE_NAME, durable, false, false, null);
尽管这行代码本身是正确的,但是仍然不会正确运行。因为我们已经定义过一个叫hello的非持久化队列。RabbitMq不允许你使用不同的参数重新定义一个队列,它会返回一个错误。但我们现在使用一个快捷的解决方法——用不同的名字,例如task_queue。
boolean durable = true;
channel.queueDeclare("task_queue", durable, false, false, null);
这时候,我们就可以确保在RabbitMq重启之后queue_declare队列不会丢失。现在我们需要将消息标记为持久性 - 通过将MessageProperties(实现BasicProperties)设置为值PERSISTENT_TEXT_PLAIN。
import com.rabbitmq.client.MessageProperties;
channel.basicPublish("", "task_queue",
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes());
公平调度
你应该已经发现,它仍旧没有按照我们期望的那样进行分发。比如有两个工作者(workers),处理奇数消息的比较繁忙,处理偶数消息的比较轻松。然而RabbitMQ并不知道这些,它仍然一如既往的派发消息。
这时因为RabbitMQ只管分发进入队列的消息,不会关心有多少消费者(consumer)没有作出响应。它盲目的把第n-th条消息发给第n-th个消费者。
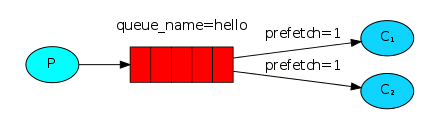
我们可以使用basicQos方法,并设置prefetchCount = 1。这样是告诉RabbitMQ,再同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。
int prefetchCount = 1;
channel.basicQos(prefetchCount);
发布/订阅
在上篇教程中,我们搭建了一个工作队列,每个任务只分发给一个工作者(worker)。在本篇教程中,我们要做的跟之前完全不一样 —— 分发一个消息给多个消费者(consumers)。这种模式被称为“发布/订阅”。
为了描述这种模式,我们将会构建一个简单的日志系统。
交换机(Exchanges)
RabbitMQ中完整的消息模型:
- 发布者(producer)是发布消息的应用程序。
- 队列(queue)用于消息存储的缓冲。
- 消费者(consumer)是接收消息的应用程序。
RabbitMQ消息模型的核心理念是:发布者(producer)不会直接发送任何消息给队列。事实上,发布者(producer)甚至不知道消息是否已经被投递到队列。
发布者(producer)只需要把消息发送给一个交换机(exchange)。交换机非常简单,它一边从发布者方接收消息,一边把消息推送到队列。交换机必须知道如何处理它接收到的消息,是应该推送到指定的队列还是是多个队列,或者是直接忽略消息。这些规则是通过交换机类型(exchange type)来定义的。
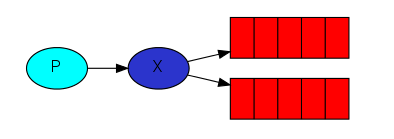
有几个可供选择的交换机类型:直连交换机(direct), 主题交换机(topic), (头交换机)headers和 扇型交换机(fanout)。我们在这里主要说明最后一个 —— 扇型交换机(fanout)。先创建一个fanout类型的交换机,命名为logs:
channel.exchangeDeclare("logs", "fanout");
扇型交换机(fanout)很简单,你可能从名字上就能猜测出来,它把消息发送给它所知道的所有队列。
现在,我们就可以发送消息到一个具名交换机了:
channel.basicPublish( "logs", "", null, message.getBytes());
临时队列
要创建一个临时队列,我们需要做两件事情:
-
当我们连接上RabbitMQ的时候,我们需要一个全新的、空的队列。我们可以手动创建一个随机的队列名,或者让服务器为我们选择一个随机的队列名(推荐)。
-
当与消费者(consumer)断开连接的时候,这个队列应当被立即删除。
在Java客户端中,当我们没有向queueDeclare()提供参数时,我们使用生成的名称创建一个非持久的,独占的自动删除队列:
// 服务器分配的随机队列名,可能像这样 amq.gen-U0srCoW8TsaXjNh73pnVAw==
String queueName = channel.queueDeclare().getQueue();
绑定(Bindings)

我们已经创建了一个扇型交换机(fanout)和一个队列。现在我们需要告诉交换机如何发送消息给我们的队列。交换器和队列之间的联系我们称之为绑定(binding)。
channel.queueBind(queueName, "logs", "");
路由(Routing)
前面的例子,我们已经创建过绑定(bindings),代码如下:
channel.queueBind(queueName, EXCHANGE_NAME, "");
绑定(binding)是指交换机(exchange)和队列(queue)的关系。可以简单理解为:这个队列(queue)对这个交换机(exchange)的消息感兴趣。
绑定的时候可以带上一个额外的routing_key参数。为了避免与basic_publish的参数混淆,我们把它叫做绑定键(binding key)。以下是如何创建一个带绑定键的绑定。
channel.queueBind(queueName, EXCHANGE_NAME, "black");
绑定键的意义取决于交换机(exchange)的类型。我们之前使用过的扇型交换机(fanout exchanges)会忽略这个值。
直连交换机(Direct exchange)
我们的日志系统广播所有的消息给所有的消费者(consumers)。我们打算扩展它,使其基于日志的严重程度进行消息过滤。
我们使用的扇型交换机(fanout exchange)没有足够的灵活性 —— 它能做的仅仅是广播。
我们将会使用直连交换机(direct exchange)来代替。路由的算法很简单 —— 交换机将会对绑定键(binding key)和路由键(routing key)进行精确匹配,从而确定消息该分发到哪个队列。
下图能够很好的描述这个场景:
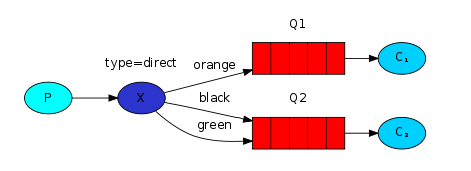
在这个场景中,我们可以看到直连交换机 X和两个队列进行了绑定。第一个队列使用orange作为绑定键,第二个队列有两个绑定,一个使用black作为绑定键,另外一个使用green。
这样以来,当路由键为orange的消息发布到交换机,就会被路由到队列Q1。路由键为black或者green的消息就会路由到Q2。其他的所有消息都将会被丢弃。
多个绑定(Multiple bindings)
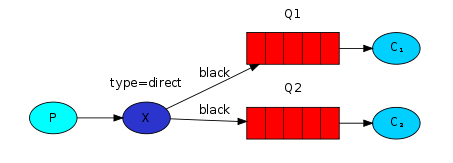
多个队列使用相同的绑定键是合法的。这个例子中,我们可以添加一个X和Q1之间的绑定,使用black绑定键。这样一来,直连交换机就和扇型交换机的行为一样,会将消息广播到所有匹配的队列。带有black路由键的消息会同时发送到Q1和Q2。
发送日志
我们将会发送消息到一个直连交换机,把日志级别作为路由键。这样接收日志的脚本就可以根据严重级别来选择它想要处理的日志。我们先看看发送日志。
我们需要创建一个交换机(exchange):
channel.exchangeDeclare(EXCHANGE_NAME, "direct");
然后我们发送一则消息:
channel.basicPublish(EXCHANGE_NAME, severity, null, message.getBytes());
订阅
处理接收消息的方式和之前差不多,只有一个例外,我们将会为我们感兴趣的每个严重级别分别创建一个新的绑定。
String queueName = channel.queueDeclare().getQueue();
for(String severity : argv){
channel.queueBind(queueName, EXCHANGE_NAME, severity);
}
示例代码
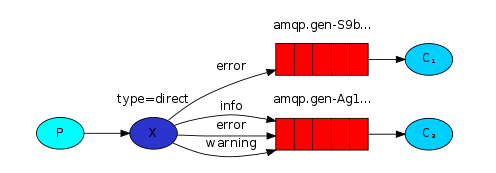
主题交换机
直连交换机的限制 —— 没办法基于多个标准执行路由操作。
发送到主题交换机(topic exchange)的消息不可以携带随意什么样子的路由键(routing_key),它的路由键必须是一个由.分隔开的词语列表。这些单词随便是什么都可以,但是最好是跟携带它们的消息有关系的词汇。以下是几个推荐的例子:"stock.usd.nyse", "nyse.vmw", "quick.orange.rabbit"。词语的个数可以随意,但是不要超过255字节。
绑定键也必须拥有同样的格式。主题交换机背后的逻辑跟直连交换机很相似 —— 一个携带着特定路由键的消息会被主题交换机投递给绑定键与之想匹配的队列。但是它的绑定键和路由键有两个特殊应用方式:
*(星号) 用来表示一个单词.#(井号) 用来表示任意数量(零个或多个)单词。
下边用图说明:
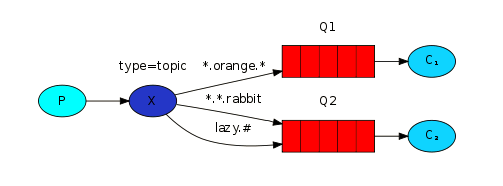
我们创建了三个绑定:Q1的绑定键为 *.orange.*,Q2的绑定键为 *.*.rabbit 和 lazy.# 。
这三个绑定键被可以总结为:
- Q1 对所有的桔黄色动物都感兴趣。
- Q2 则是对所有的兔子和所有懒惰的动物感兴趣。
主题交换机是很强大的,它可以表现出跟其他交换机类似的行为
当一个队列的绑定键为 "#"(井号) 的时候,这个队列将会无视消息的路由键,接收所有的消息。
当
*(星号) 和#(井号) 这两个特殊字符都未在绑定键中出现的时候,此时主题交换机就拥有的直连交换机的行为。
远程过程调用(RPC)
如果我们需要将一个函数运行在远程计算机上并且等待从那儿获取结果时,这种模式通常被称为远程过程调用(Remote Procedure Call)或者RPC。
我们会使用RabbitMQ来构建一个RPC系统:包含一个客户端和一个RPC服务器。
客户端接口
为了展示RPC服务如何使用,我们创建了一个简单的客户端类。它会暴露出一个名为“call”的方法用来发送一个RPC请求,并且在收到回应前保持阻塞。
FibonacciRpcClient fibonacciRpc = new FibonacciRpcClient();
String result = fibonacciRpc.call("4");
System.out.println( "fib(4) is " + result);
回调队列
一般来说通过RabbitMQ来实现RPC是很容易的。一个客户端发送请求信息,服务器端将其应用到一个回复信息中。为了接收到回复信息,客户端需要在发送请求的时候同时发送一个回调队列(callback queue)的地址。
callbackQueueName = channel.queueDeclare().getQueue();
BasicProperties props = new BasicProperties
.Builder()
.replyTo(callbackQueueName)
.build();
channel.basicPublish("", "rpc_queue", props, message.getBytes());
消息属性
AMQP协议给消息预定义了一系列的14个属性。大多数属性很少会用到,除了以下几个:
- delivery_mode(投递模式):将消息标记为持久的(值为2)或暂存的(除了2之外的其他任何值)。第二篇教程里接触过这个属性,记得吧?
- content_type(内容类型):用来描述编码的mime-type。例如在实际使用中常常使用application/json来描述JOSN编码类型。
- reply_to(回复目标):通常用来命名回调队列。
- correlation_id(关联标识):用来将RPC的响应和请求关联起来。
关联标识
上边介绍的方法中,我们建议给每一个RPC请求新建一个回调队列。这不是一个高效的做法,幸好这儿有一个更好的办法 —— 我们可以为每个客户端只建立一个独立的回调队列。
这就带来一个新问题,当此队列接收到一个响应的时候它无法辨别出这个响应是属于哪个请求的。correlation_id 就是为了解决这个问题而来的。我们给每个请求设置一个独一无二的值。稍后,当我们从回调队列中接收到一个消息的时候,我们就可以查看这条属性从而将响应和请求匹配起来。如果我们接手到的消息的correlation_id是未知的,那就直接销毁掉它,因为它不属于我们的任何一条请求。
为什么我们接收到未知消息的时候不抛出一个错误,而是要将它忽略掉?这是为了解决服务器端有可能发生的竞争情况。尽管可能性不大,但RPC服务器还是有可能在已将应答发送给我们但还未将确认消息发送给请求的情况下死掉。如果这种情况发生,RPC在重启后会重新处理请求。这就是为什么我们必须在客户端优雅的处理重复响应,同时RPC也需要尽可能保持幂等性。
总结
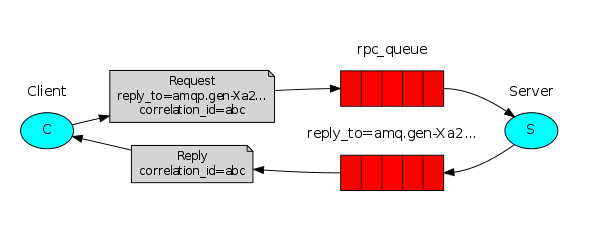
我们的RPC如此工作:
- 当客户端启动的时候,它创建一个匿名独享的回调队列。
- 在RPC请求中,客户端发送带有两个属性的消息:一个是设置回调队列的 reply_to 属性,另一个是设置唯一值的 correlation_id 属性。
- 将请求发送到一个 rpc_queue 队列中。
- RPC工作者(又名:服务器)等待请求发送到这个队列中来。当请求出现的时候,它执行他的工作并且将带有执行结果的消息发送给reply_to字段指定的队列。
- 客户端等待回调队列里的数据。当有消息出现的时候,它会检查correlation_id属性。如果此属性的值与请求匹配,将它返回给应用。