SQLAlchemy
首先需要知道ORM是什么
ORM: Object-Relational Mapping, 对象关系映射, 能够把关系型数据库的表结构映射到模型类对象上, 即实例化一个类对象, 通过操作该对象来操作后台数据库表
使用ORM而不使用手动拼写原生SQL语句有两点好处:
- 使用起来更加方便, 使用面向对象的一套操作即可操作数据库
- 能够有效防止SQL注入, 手动拼写SQL语句的一大缺点就是可能没有考虑到SQL注入
python中比较常用的ORM框架为Django自带的ORM和SQLAlchemy, 两者操作步骤上相差不到, 只是具体语法上有所差异. 且SQLAlchemy的功能比Django自带的ORM更加强大.
SQLAlchemy是一个单独的ORM框架, 可以直接安装并使用, 也可以与其他的python web框架一起使用, 当然一般情况下是和web框架一起使用的, 这里介绍的是在Flask框架中使用SQLAlchemy.
Flask-SQLAlchemy
安装数据库驱动
首先我们需要安装相应的数据库驱动,
这里我们需要知道的是, 当我们写好了SQL点击执行时, 是通过相应的数据库驱动把SQL语句传递给数据库服务器, 然后数据库服务器再解析并执行SQL, 把结果再通过数据库驱动返回.
而ORM的作用是将实例化模型类对象的操作转换为SQL语句, 或者将数据库返回的结果转化为实例化模型类对象. 并不能直接与数据库服务器进行交互
因此不管使用什么ORM, 首先就需要安装相应的数据库驱动, 这里我们以最常见的mysql数据库为例
python中mysql数据库驱动
-
在python2中, 数据库驱动为
MySQL-python(又叫MySQLdb), 通过命令pip install MySQL-python安装 -
在python3中, 数据库驱动有两个:
-
mysqlclient: 完全兼容MySQLdb,同时支持 Python3.x通过命令
pip install mysqlclient安装 -
PyMySQL: PyMySQL 是纯 Python 实现的驱动,速度上比不上 MySQLdb, 但是在使用时需要加上pymysql.install_as_MySQLdb()才能兼容MySQLdb通过命令
pip install PyMySQL安装
-
我们这里的环境是python3, 选择安装mysqlclient
创建模型类脚本
这里以简单的两个表(角色表test_roles和用户表test_users)为例, 他们的关系是一对多的, 即一个角色里面可以有多个用户, 如用户xiaoming和用户xiaohua都是系统管理员admin
首先创建最基本的脚本, 定义两个模型类
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 创建Flask应用
app = Flask(__name__)
# 配置数据库连接
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:root@127.0.0.1:3306/sqlalchemy_test'
# 创建数据库实例
db = SQLAlchemy(app)
# 定义角色类, 继承db.Model类
class Role(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_roles'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_key=True) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
# 定义用户类, 继承db.Model类
class User(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_users'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_keyTrue) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
email = db.Column(db.String(30), unique=True)
现在只是定义好了单独的两张表, 接下来我们需要给这两张表添上一对多的关联关系
首先我们这里先提出两个概念帮助我们理解ORM: 逻辑上和物理上,
-
类名和属性名, 属于逻辑上的概念, 即我们操作的模型对象
-
数据库表名和表字段属于物理上的概念, 即真实表的结构
执行数据库迁移(Flask-Migrate)
这一步也可以放在定义表关联的后面, 即先把关联关系都定义好了再进行统一的迁移
我这里把这一步放在前面是要测试物理表结构改变后需要执行迁移, 而逻辑上表结构改变后不需要执行迁移
安装迁移插件Flask-Migrate
flask与Django框架定义上刚好相反, Django讲究的是大而全, 集成了很多可以直接使用的功能, 如ORM和管理脚本 python manager.py 等, 而flask讲究的是小而精, flask本身只是一个很小的框架, 有很多功能它本身并不具备, 而需要安装很多第三方插件来组装成一个完整的项目.
两个框架各有优缺点, django很全但是很笨重, 可能有些功能并不需要, flask很小但是很灵活, 可以自己添加想要的功能组件, 但是如果组件很多, 组装和维护都更加麻烦.
回到Flask-Migrate, 这个插件的功能是能够像django的python manager.py migrate一样, 用来迁移模型类, 在数据库中与创建定义的模型类对应的数据表
通过命令安装
pip install flask-migrate
app脚本中添加数据库迁移对象
在运行文件中导入flask_migrate模块并创建Migrate对象
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
# 创建app对象
app = Flask(__name__)
# 创建数据库连接
db = SQLAlchemy(app)
# 创建数据库迁移对象
migrate = Migrate(app, db)
初始化数据库
在项目目录下, 先定义临时环境变量FLASK_APP, 这是运行flask应用必须定义的
export FLASK_APP=demo.py
执行下面命令进行初始化
flask db init
初始化完成后, 会自动在当前目录创建一个migrations的文件夹, 用来保存每次迁移的历史记录, 同时在数据库中也会创建一个alembic_version表, 用来记录版本信息
执行迁移
运行下面命令执行迁移
flask db migrate
迁移成功后, 会在migrations文件夹下的versions下创建一个迁移文件30b846daf2bd_.py, 该文件记录的是这一步迁移需要完成哪些数据库操作, 不过此时还没有将表同步至数据库中, 可以理解为只是生成了对应的sql语句而已
同步至数据库
运行下面命令执行同步数据库
flask db upgrade
同步完成后, 可以查看数据库中多出了test_roles和test_users两张表, 同时alembic_version表中也多了一条记录, 存的值就是上面的迁移文件30b846daf2bd_.py中的前缀30b846daf2bd
定义表关联
添加一对多的关联关系可以分为两步:
- 定义两个数据表的关系字段, 这里需要在用户表下定义外键字段role_id, 该字段需要写入数据库, 属于物理上表结构新增字段
- 定义两个模型类的关系字段, 这个字段只是为了在ORM操作时能够直接通过.属性的方式来获取到对应的模型类, 属于逻辑上的关联, 不需要写入数据库中, 且该关联字段并不是必须定义的, 不过为了方便建立联系, 我们一般都会定义它
首先定义两个数据表的关系字段(物理上)
在User类下在新增一个字段, 名为role_id, 该字段是外键, 存的是test_role表的id字段
注意定义ForeignKey的时候, 参数为数据库表名_字段名, 而不是类名_字段名, 因为这是物理表结构上的关联
class User(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_users'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_keyTrue) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
email = db.Column(db.String(30), unique=True)
# 注意定义ForeignKey的时候, 参数为'数据库表名_字段名', 而不是'类名_字段名'
role_id = db.Column(db.Integer, db.ForeignKey('test_roles.id'))
执行迁移命令
flask db migrate
flask db upgrade
可以看到数据库中的test_users表已经多了一个role_id字段
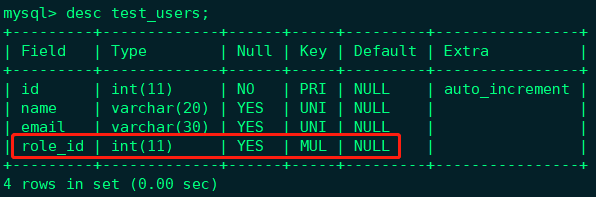
再定义两个模型类的关系字段(逻辑上)
理论上到这里已经可以算是完成了整个关系的定义, 可以直接创建数据了, 但是此时只是两个数据表之前建立了外键连接, 但是两个模型类之间还没有定义逻辑连接
此时我们如果想要查看某个User对象属于哪一个Role, 那么只能通过User对象拿到role_id, 再通过Role模型查询该role_id对应的Role对象
像这种情况如果想要能通过User.role的方式直接拿到对应的Role对象, 那么就需要建立两个模型类的逻辑连接
在User类下定义一个role字段, 该字段不是物理表结构字段, 而是逻辑关系字段, 因此使用的是db.relationship而不是db.Column
class User(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_users'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_key=True) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
email = db.Column(db.String(30), unique=True)
# 注意定义ForeignKey的时候, 参数为'数据库表名_字段名', 而不是'类名_字段名'
role_id = db.Column(db.Integer, db.ForeignKey('test_roles.id'))
# 建立两个模型类的逻辑连接关系
role = db.relationship('Role', backref='user')
第一个参数为目标对象的类名(不是表名), 第二个参数backref=为目标对象访问User对象使用的属性名, 即相当于在Role对象也定义了一个名为user的属性, 可以直接通过.user访问到对应的User对象, 当然这里返回的是一个User对象的列表, 因为一个Role下可能有多个User对象
同理, 这个逻辑关系不仅可以定义在User类中, 也可以定义在Role类中(只需要在其中一个类中定义即可), 但是需要把相应的属性名修改一下, ,如下:
# 定义角色类, 继承db.Model类
class Role(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_roles'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_key=True) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
# 建立两个模型类的逻辑连接关系
user = db.relationship('User', backref='role')
创建数据测试逻辑关联
在前面定义了临时变量FLASK_APP目录中, 运行flask shell, 进入像Django的python manager.py shell一样的python shell中
# 导入app中的db和模型类
>>> from demo import db, User, Role
# 创建一个Role对象, 名为admin
>>> admin = Role(name='admin')
# 保存该条数据提交至数据库
>>> db.session.add(admin)
>>> db.session.commit()
# 创建一个User对象, 名为xiaoming, role_id为刚才创建的admin的id
>>> xiaoming = User(name='xiaoming', email='xiaoming.com', role_id=admin.id)
# 保存该条数据提交至数据库
>>> db.session.add(xiaoming)
>>> db.session.commit()
# 直接通过User.role访问xiaoming的role
>>> xiaoming.role
<Role 1>
# 直接通过Role.user访问admin下的user
>>> admin.user
[<User 1>]
可以发现创建的逻辑关系字段, 并不需要执行迁移命令, 因为并没有改变数据库的表结构
优化模型类
前面定义的模型类已经可以完成主要功能了, 接下来设置一些属性和方法, 完善模型类, 使用起来能够更加方便
重写__init__方法
在实例化模型类的时候, 每个字段都要使用关键字参数的方式赋值, 我们可以重写__init__方法, 让我们赋值的时候更加方便
重写__repr__方法
前面我们打印出来的对象结果都是<类名 ID>的形式, 阅读起来不太友好, 我们可以重写__repr__方法, 让打印结果的可读性更高
最终模型类如下:
from flask import Flask from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
# 创建Flask应用
app = Flask(__name__)
# 配置数据库连接
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:root@47.102.114.90:3306/sqlalchemy_test'
# 创建数据库实例
db = SQLAlchemy(app)
# 创建数据库迁移对象
migrate = Migrate(app, db)
# 定义角色类, 继承db.Model类
class Role(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_roles'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_key=True) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
def __init__(self, name):
self.name = name
def __repr__(self):
return f'<Role {self.name}>'
# 定义用户类, 继承db.Model类
class User(db.Model):
# 手动定义表名, 否则默认为小写的类名
__tablename__ = 'test_users'
# 定义字段, 格式为: 字段名 = db.Column(db.类型, 附加属性[主键/唯一性等])
id = db.Column(db.Integer, primary_key=True) # 主键必须显示定义出来
name = db.Column(db.String(20), unique=True)
email = db.Column(db.String(30), unique=True)
# 注意定义ForeignKey的时候, 参数为'数据库表名_字段名', 而不是'类名_字段名'
role_id = db.Column(db.Integer, db.ForeignKey('test_roles.id'))
# 建立两个模型类的逻辑连接关系
role = db.relationship('Role', backref='user')
def __init__(self, name, email, role):
self.name = name
self.email = email
self.role = role # 注意这里的role参数类型是Role对象, 而不是role_id, 当然你也可以加上role_id参数
def __repr__(self):
return f'<User {self.name}>'
增删改查方法(CRUD)
以下操作在ipython中执行, 先进入ipython, 导入demo应用中的模型类和db数据库对象
$ ipython
In [1]: from demo import db, Role, User
增
新增一条记录 add(obj)
# 创建模型对象
In [2]: staff = Role('staff')
# 添加对象至会话中
In [3]: db.session.add(staff)
# 将会话中的操作提交至数据库
In [4]: db.session.commit()
这里的会话不是 Flask 的会话,而是 Flask-SQLAlchemy 的会话。它本质上是一个 数据库事务的加强版本
一次性新增多条记录 add_all(list)
# 创建多个User对象
In [37]: zhao = User('zhao', 'zhao.qq.com', admin)
In [38]: qian = User('qian', 'qian.163.com', admin)
In [39]: sun = User('sun', 'sun.qq.com', staff)
In [40]: li = User('li', 'li.163.com', staff)
# add_all([对象列表])
In [41]: db.session.add_all([zhao, qian, sun, li])
# 提交数据库
In [42]: db.session.commit()
删
# 查询模型对象
staff = Role.query.filter_by(name='staff').first()
# 删除对象添加至会话中
In [10]: db.session.delete(staff)
# 将会话中的操作提交至数据库
db.session.commit()
改
方法一: 获取到模型对象再修改对象属性
# 查询模型对象
In [12]: admin = Role.query.filter_by(name='admin').first()
# 修改对象属性
In [13]: admin.name = 'super'
# 添加会话并提交数据库
In [14]: db.session.add(admin)
In [15]: db.session.commit()
方法二: 查询时直接update修改字段
# 调用查询结果集的update方法, 参数为一个字典, 将需要修改的字段以键值对的方式写入
# 注意这里没有使用first(), 因为first()返回的类型是一个模型对象, 只有查询结果集才有update方法
In [17]: Role.query.filter_by(name='super').update({'name': 'admin'})
Out[17]: 1
# 将修改提交, 这里不需要调用db.session.add(), 因为也没有模型对象可以传入
In [18]: db.session.commit()
查
all()
返回一个列表, 列表中是所有查询到的模型类对象, 若查不到则返回空列表[]
In [43]: User.query.all()
Out[43]: [<User zhao>, <User qian>, <User sun>, <User li>]
first()
返回查找集的第一个模型类对象, 若查不到则返回None
In [44]: User.query.first()
Out[44]: <User zhao>
get(ident)
get参数只能是主键ID, 返回的是模型类对象(不是查找集), 因此不需要.first(), 若查不到则返回None
In [19]: role = Role.query.get(1)
In [20]: role
Out[20]: <Role admin>
filter_by(属性1=xxx, 属性2=xxx)
filter_by参数的字段条件只能用于等号, 且只能满足并且(and)关系的查询, 返回的是查找集, 若最终想返回模型类字段, 则需要使用.first()或者.all(), 若查不到则返回None
# 实现查询: User名字为li且邮箱为li.163.com的数据
In [3]: User.query.filter_by(name='li', email='li.163.com').first()
Out[3]: <User li>
filter(类名.属性1xxx, 类名.属性2xxx)
filter_by是filter的一个阉割版, filter的功能更加强大, 能实现或(or)关系, 也能实现模糊查询, 大于小于查询等, 需要注意的是条件中必须是类名.属性的格式, 而不能像filter_by那样只使用属性名
# 实现查询: User名字为li且邮箱为li.163.com的数据, 注意与上面的filter_by对比
# 1. 属性前面需要加上模型类名
# 2. 一个等号需要改成两个连等号
In [8]: User.query.filter(User.name=='li', User.email=='li.163.com').first()
Out[8]: <User li>
# 实现查询: User的ID大于3或者邮箱以qq.com结尾的数据
# or操作需要导入该模块
In [9]: from sqlalchemy import or_
# 1. or_(条件1, 条件2)参数为多个或者关系的条件
# 2. 等于(==), 大于(>), 大于等于(>=), 小于同理
# 3. 属性.endswith(), 以...结尾, 同理.startswith(), 以...开头
In [14]: User.query.filter(or_(User.id>3, User.email.endswith('qq.com'))).all()
Out[14]: [<User zhao>, <User sun>, <User li>]
limit(number)
查找number条数据
offset(number)
偏移number条数据
order_by(模型类.字段1 [.desc()], 模型类.字段2 [.desc()])
根据字段排序, 默认为升序asc, 降序为.desc()
# 实现查询: User表中从第二条数据开始, 查询3条数据, 并按ID降序排序
# 需要注意的是order_by需要早offset和limit前面, 否则会报错
In [22]: User.query.order_by(User.id.desc()).offset(1).limit(3).all()
Out[22]: [<User sun>, <User qian>, <User zhao>]
group_by(模型类.字段1, 模型类.字段2)
# 实现查询: User表根据Role分组, 汇总每个role下有多少条数据
# 导入func, 里面包含了分组汇总函数count等很多函数
In [26]: from sqlalchemy import func
# 1. 使用group时前面就不能使用User.query形式, 而是要使用db.session.query的形式, 括号中是要查询结果需要展示的字段
# 2. func类中有很多方法, count()参数为需要计算的字段
# 3. group_by()参数为根据什么字段来分组
In [29]: db.session.query(User.role_id, func.count(User.role_id)).group_by(User.role_id).all()
Out[29]: [(1, 2), (3, 2)]