简介
FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,使用 Python 3.6+ 并基于标准的 Python 类型提示。
关键特性:
- 快速:可与 NodeJS 和 Go 比肩的极高性能(归功于 Starlette 和 Pydantic)。最快的 Python web 框架之一。
- 高效编码:提高功能开发速度约 200% 至 300%。*
- 更少 bug:减少约 40% 的人为(开发者)导致错误。*
- 智能:极佳的编辑器支持。处处皆可自动补全,减少调试时间。
- 简单:设计的易于使用和学习,阅读文档的时间更短。
- 简短:使代码重复最小化。通过不同的参数声明实现丰富功能。bug 更少。
- 健壮:生产可用级别的代码。还有自动生成的交互式文档。
- 标准化:基于(并完全兼容)API 的相关开放标准:OpenAPI (以前被称为 Swagger) 和 JSON Schema。
安装
uvicorn为ASGI服务器
pip install fastapi
pip install uvicorn
HelloWord
编写脚本
创建一个名为hello_world.py的文件
from fastapi import FastAPI
# 创建fastapi的应用, 自定义名为app
app = FastAPI()
# url+http方法+执行函数
@app.get('/')
async def hello_world():
return {'hello': 'world'}
启动服务
通过uvicorn启动服务, 其中--reload是可选参数, 代码修改后会自动重启服务
uvicorn hello_world:app --reload
启动结果如下则说明启动成功, 默认是在8000端口启动的, 地址为http://127.0.0.1:8000
$ uvicorn hello_world:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [189] using statreload
INFO: Started server process [191]
INFO: Waiting for application startup.
INFO: Application startup complete.
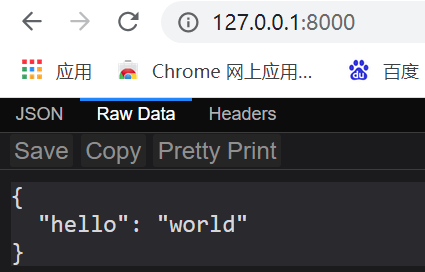
浏览器访问接口
通过浏览器访问http://127.0.0.1:8000, 可以看到返回结果
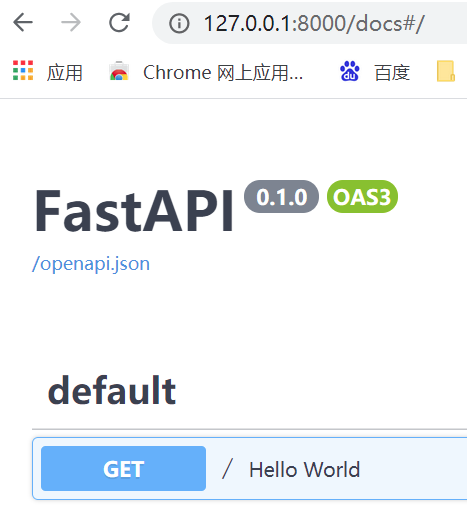
查看交互式API文档
FastAPI会自动生成交互式API文档, 通过网址http://127.0.0.1:8000/docs访问, 这个可以方便开发人员更好地调试api, 也可以在文档上写入相关的注释, 方便前后端开发的对接
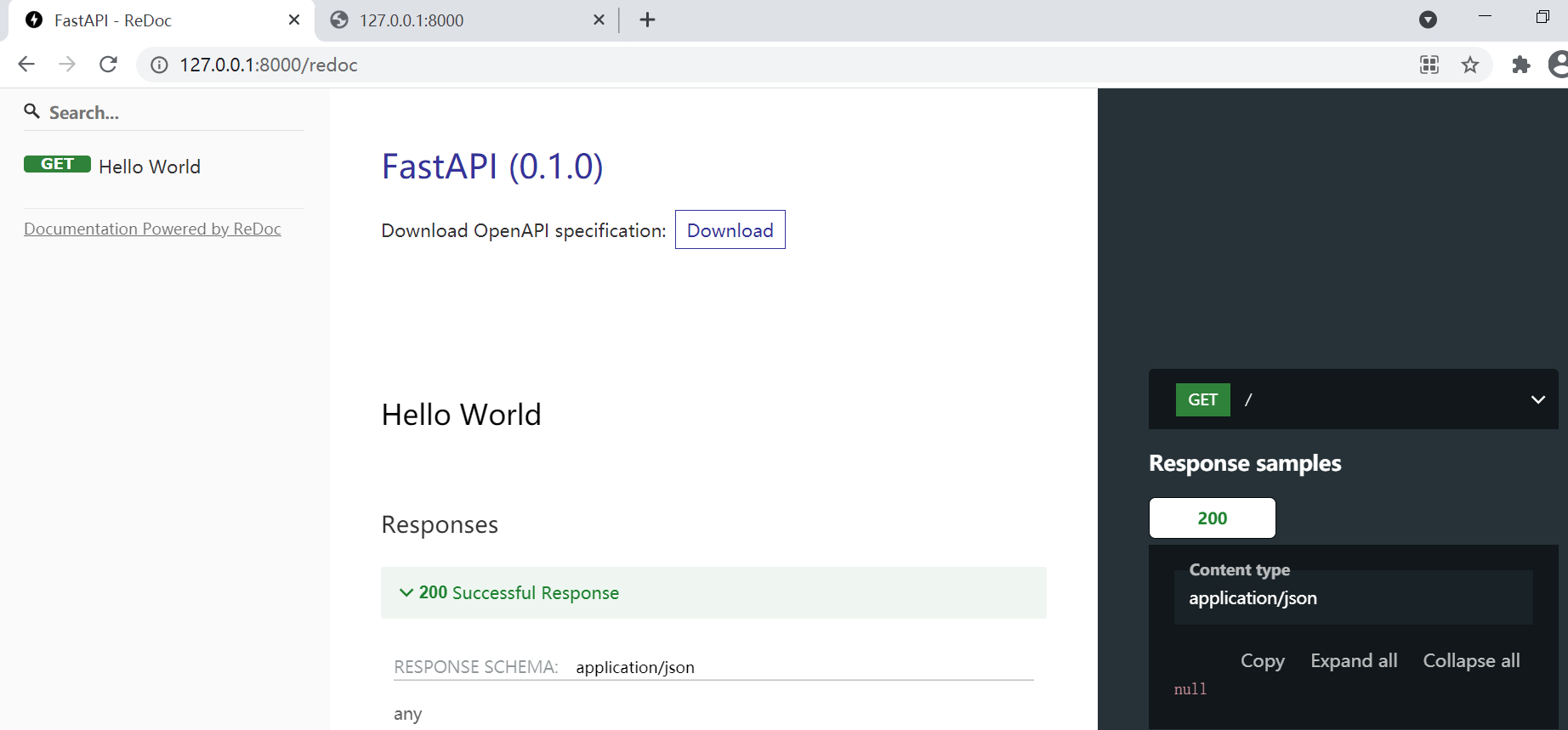
查看可选的api文档
除了上面的交互式api文档外, fastapi还提供了另一个文档, 通过http://127.0.0.1:8000/redoc访问, 这个文档只能查看, 不能交互
url路径参数
基本用法
这里的路径参数指的是url访问资源的路径中的参数, 比如根据restful规范, 定义访问id为1的商品, 对应的url应该是/goods/1, 那么如果想访问id为n的商品, url应该是/goods/n, 这个n就是路径参数.
在fastapi中定义路径参数的方法是:
@app.get('/items/{item_id}')
async def get_item_by_id(item_id: int):
return {'item_id': item_id}
-
item_id即为路径参数名, 路径参数需要用大括号括起来, 且在执行函数get_item_by_id中需要定义与路径参数同名的参数item_id -
在定义函数参数
item_id时, 用到了python3.6+引入的"类型提示", 这样能够让代码和读维护起来更加方便, 编辑器也能够根据类型提供更多的支持, 推荐使用 -
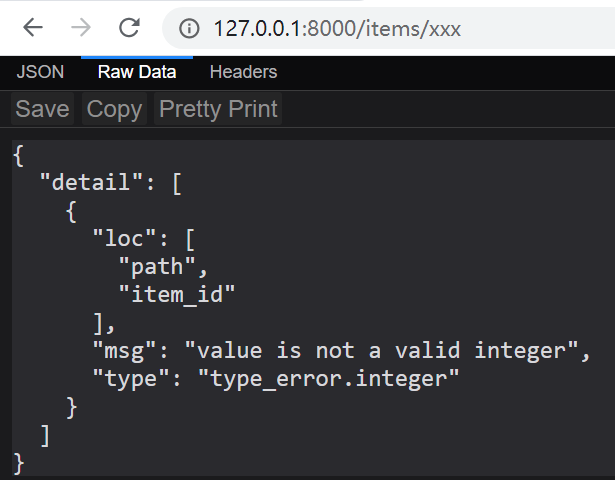
有了类型提示后, 如果url传入的参数不能转换为int类型, 则fastapi会自动检测并返回错误信息, 如:
枚举类型参数
# 导入枚举模块
from enum import Enum
# 定义枚举类
class BookType(str, Enum):
java = "Java"
python = "Python"
c_plus = "C++"
# 定义函数
@app.get('/books/{book_type}')
async def get_book_type(book_type: BookType):
result = {'book_type': book_type, 'message': ''}
if book_type == BookType.java:
result['message'] = "This is java"
elif book_type == BookType.python:
result['message'] = 'This is python'
elif book_type == BookType.c_plus:
result['message'] = 'This is c++'
return result
- 定义枚举类
BookType时需要继承str和Enum类, 表明枚举值都是字符串类型, 下面的类变量即为枚举变量和枚举值 - 参数
book_type的类型注解为定义的枚举类BookType
包含路径的路径参数
@app.get('/files/{file_path:path}')
async def get_file_path(file_path):
return {'file_path': file_path}
- 在url中定义参数路径参数时, 如果该参数值本身也是一个路径, 为了不会混淆, 可以在url参数后面添加
:path, 用来表示这个参数是一个路径格式
查询参数
查询参数指的是在url后面添加的以?开头并以&分隔的一系列键值对参数
在fastapi的函数中, 如果声明的参数不属于路径参数, 那么它就会被自动解释为查询参数
from typing import Optional
@app.get('/items/')
async def get_query_param(page: int, count: Optional[int] = 10):
return {'page': page, 'count': count}
- 在函数
get_query_param后定义了两个参数page和count, 这两个参数并没有对应的url路径参数, 因此fastapi会认为这两个参数是查询参数 - 其中
page参数没有指定Optional和默认值, 因此该参数被认为是必输的 count参数指定了为Optional, 可选的, 并给了默认值, 那么说明这个参数不是必填的, 如果没填, 就默认这个参数值为10
请求体
使用pydantic声明请求体
# 导入pydantic基本模型
from pydantic import BaseModel
# 创建请求体的pydantic模型类
class Item(BaseModel):
name: str
description: Optional[str] = None
price: float
tax: Optional[float] = None
@app.post('/items/')
async def create_item(item: Item):
# return item 可以直接返回pydantic类型的数据
# 也可以将pydantic转为字典, 然后做后续的逻辑处理
item_dict = item.dict()
if item.tax:
price_with_tax = item.price + item.tax
item_dict['price_with_tax'] = price_with_tax
return item_dict
- 在定义pydantic模型类时, 和声明查询参数一样, 可以设置Optional属性指定其是否为 必输字段
- 声明执行函数的参数
item类型为上面定义的pydantic模型类 - fastapi会把传入的请求体作为json读取, 然后转为定义的pydantic模型类, 并校验数据的类型和是否必输
在fastapi的交互式文档的schemas中, 可以看到定义的pydantic模型类, 上面指明了类型和是否必输
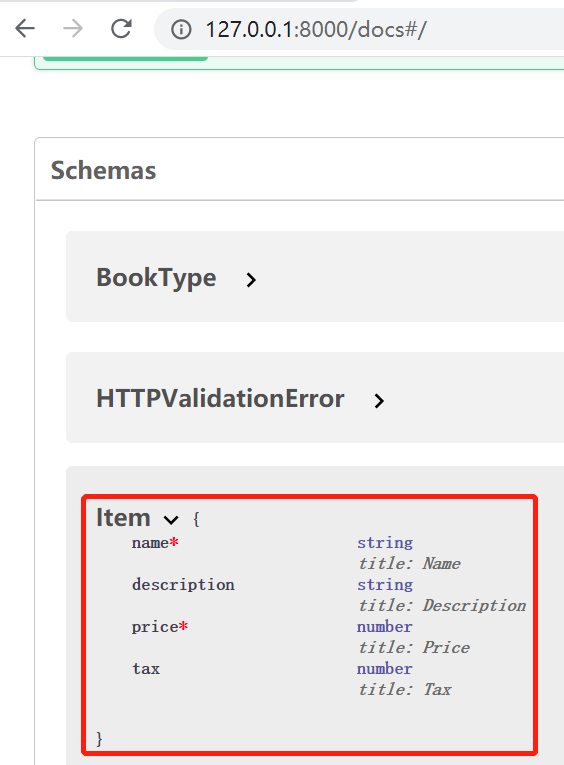
pydantic请求体 + 路径参数 + 查询参数
# 导入pydantic基本模型
from pydantic import BaseModel
# 创建请求体的pydantic模型类
class Item(BaseModel):
name: str
description: Optional[str] = None
price: float
tax: Optional[float] = None
@app.put('/items/{item_id}')
async def update_book(item_id: int, item_type: str, item: Item):
return {'path_param': {'item_id': item_id}, 'query_param': {'item_type': item_type}, 'req_body': item}
可以同时声明 路径参数+查询参数+请求体, fastapi会自动识别他们中的每一个并从正确的位置获取数据, 函数参数将依次按如下规则进行识别:
- 如果在路径中也声明了该参数,它将被用作路径参数。
- 如果参数属于单一类型(比如
int、float、str、bool等)它将被解释为查询参数。 - 如果参数的类型被声明为一个 Pydantic 模型,它将被解释为请求体。
不使用pydantic声明请求体-Body
使用fastapi的Body来定义单一的请求体参数, 在参数后面加上= Body(...)来表示这个参数是请求体参数, 如下面的item_name参数和item_price参数, 但是这样只能一个一个定义请求体参数, 如果参数很多还是建议使用pydantic的模型类定义
from fastapi import Body
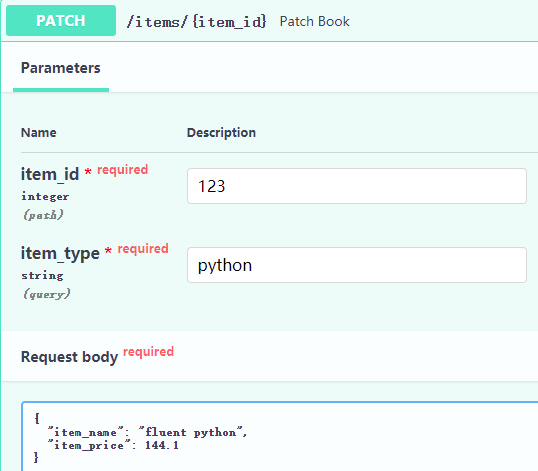
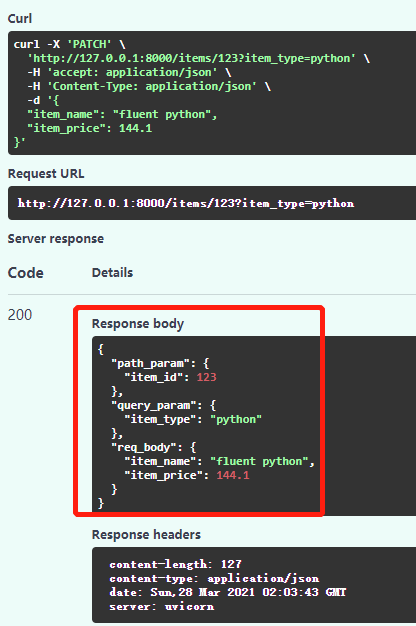
@app.patch('/items/{item_id}')
async def patch_book(item_id: int, item_type: str, item_name: str = Body(...), item_price: float = Body(...)):
return {'path_param': {'item_id': item_id}, 'query_param': {'item_type': item_type},
'req_body': {'item_name': item_name, 'item_price': item_price}}
请求为:
响应为:
查询参数的额外校验-Query
使用fastapi的Query类型, 在参数后面加上= Query(), 如限制最长不能超过5位, Query(max_length=5)
from fastapi import Query
@app.get('/query_items/')
async def query_items(item_type: Optional[str] = Query(None, max_length=5)):
result = {'items': [{'item_id': 1}, {'item_id': 2}]}
if item_type:
result['item_type'] = item_type
return item_type
点击Query进入源码可以查看Query所接受的参数
def Query( # noqa: N802
default: Any, # 参数默认值
*,
alias: Optional[str] = None, # 参数别名, 对应url中的查询参数名
title: Optional[str] = None,
description: Optional[str] = None,
gt: Optional[float] = None, # 参数值需大于...
ge: Optional[float] = None, # 参数值需大于等于...
lt: Optional[float] = None, # 参数值需小于...
le: Optional[float] = None, # 参数值需小于...
min_length: Optional[int] = None, # 参数最小长度...
max_length: Optional[int] = None, # 参数最大长度...
regex: Optional[str] = None, # 正则表达式限制...
deprecated: Optional[bool] = None, # 是否已经失效
**extra: Any,
) -> Any:
- default: Query的第一个参数, 表示该查询参数的默认值, 如果设置了这个默认值的话, 那么就认为这个参数是可选参数(非必输), 相当于
Optional[type] = default, 如果想要设置参数必输, 那么就把default值设为Query(...)
查询参数列表
from typing import List
@app.get('/list_items/')
async def get_list_items(q: Optional[List[str]] = Query(None)):
return {'q': q}
访问urlhttp://127.0.0.1:8000/list_items/?q=1&q=2, 返回结果:
{
"q": [
"1",
"2"
]
}
- 在参数中使用了List类型后, fastapi会将该参数解析为请求体, 因此如果想要该参数为查询参数, 那么需要显式地使用
Query
路径参数的额外校验-Path
与使用Query声明查询参数类似, 路径参数可以使用Path来声明
from fastapi import Path
@app.get('/path_items/{item_name}')
async def get_path_items(item_name: str = Path('Python', max_length=6)):
return {'item_name': item_name}
Path的参数用法与Query一样:
def Path( # noqa: N802
default: Any,
*,
alias: Optional[str] = None,
title: Optional[str] = None,
description: Optional[str] = None,
gt: Optional[float] = None,
ge: Optional[float] = None,
lt: Optional[float] = None,
le: Optional[float] = None,
min_length: Optional[int] = None,
max_length: Optional[int] = None,
regex: Optional[str] = None,
deprecated: Optional[bool] = None,
**extra: Any,
) -> Any
Pydantic的额外校验-Field
与使用 Query、Path 和 Body 在路径操作函数中声明额外的校验和元数据的方式相同,可以使用 Pydantic 的 Field 在 Pydantic 模型内部声明校验和元数据。需要导入pydantic的Field
from pydantic import Field
class MyItem(BaseModel):
item_id: int
item_name: str = Field(None, max_length=5)
@app.post('/field_items/')
async def get_field_items(my_item: MyItem):
return my_item
其他数据类型
-
UUID- 一种标准的 "通用唯一标识符" ,在许多数据库和系统中用作ID。
- 在请求和响应中将以
str表示。
-
datetime.datetime- 一个 Python
datetime.datetime. - 在请求和响应中将表示为 ISO 8601 格式的
str,比如:2008-09-15T15:53:00+05:00.
- 一个 Python
-
datetime.date- Python
datetime.date. - 在请求和响应中将表示为 ISO 8601 格式的
str,比如:2008-09-15.
- Python
-
datetime.time- 一个 Python
datetime.time. - 在请求和响应中将表示为 ISO 8601 格式的
str,比如:14:23:55.003.
- 一个 Python
-
datetime.timedelta- 一个 Python
datetime.timedelta. - 在请求和响应中将表示为
float代表总秒数。 - Pydantic 也允许将其表示为 "ISO 8601 时间差异编码"
- 一个 Python
-
frozenset- 在请求和响应中,作为
set对待:- 在请求中,列表将被读取,消除重复,并将其转换为一个
set。 - 在响应中
set将被转换为list。 - 产生的模式将指定那些
set的值是唯一的 (使用 JSON 模式的uniqueItems)。
- 在请求中,列表将被读取,消除重复,并将其转换为一个
- 在请求和响应中,作为
-
bytes- 标准的 Python
bytes。 - 在请求和相应中被当作
str处理。 - 生成的模式将指定这个
str是binary"格式"。
- 标准的 Python
-
Decimal- 标准的 Python
Decimal。 - 在请求和相应中被当做
float一样处理
- 标准的 Python
from datetime import datetime, time, timedelta
from uuid import UUID
@app.put('/others/{item_id}')
async def get_others(
item_id: UUID,
start_datetime: Optional[datetime] = Body(None),
end_datetime: Optional[datetime] = Body(None),
repeat_at: Optional[time] = Body(None),
process_after: Optional[timedelta] = Body(None),
):
start_process = start_datetime + process_after
duration = end_datetime - start_datetime
return {
'item_id': item_id,
'start_datetime': start_datetime,
'end_datetime': end_datetime,
'repeat_at': repeat_at,
'process_after': process_after,
'start_process': start_process,
'duration': duration,
}
Cookie
声明 Cookie 参数的结构与声明 Query 参数和 Path 参数时相同。
第一个值是参数的默认值,同时也可以传递所有验证参数或注释参数,来校验参数:
from fastapi import Cookie
@app.get('/cookies/')
async def get_cookies(user_id: Optional[str] = Cookie(None)):
return {'user_id': user_id}
Header
可以使用定义 Query, Path 和 Cookie 参数一样的方法定义 Header 参数。
from fastapi import Header
from typing import List
@app.get('/headers/')
async def get_headers(user_agent: Optional[str] = Header(None, convert_underscores=False), user_id: Optional[List[str]] = Header(None)):
return {'user_agent': user_agent, 'user_id': user_id}
-
Header比Query,Path和Cookie多了一个自动转换的功能, 因为大多数标准的headers是用中划线-连接的, 但是中划线-不符合python中定义变量的规范, 因此默认情况下, fastapi会把函数中定义的Header参数中的下划线_自动替换成中划线-, 然后去请求的headers中寻找对应的header -
同时, HTTP headers是大小写不敏感的, 所以在python中定义参数时无需考虑大写, 可以全部使用小写来命名, 例如http headers中的
User-Agent, 对应fastapi函数的参数就可以写为user_agent(大小写和中划线都可以转换) -
如果不想在某个参数上使用fastapi的自动转换功能, 可以设置
convert_underscores=False来取消自动转换 -
Header支持接收重复的headers, 可以通过List类型来重复接收, 比如headers中有两个同名headeruser_id: foo user_id: bar那么函数中的
user_id就为:{ "user_id": [ "bar", "foo" ] }
响应
基本使用
在@app.method()装饰器中使用response_model参数来声明用于响应的模型
from pydantic import EmailStr
# 请求体json模型
class UserIn(BaseModel):
user_name: str
pass_word: str
email: Optional[EmailStr] = None
full_name: Optional[str] = None
# 响应体json模型
class UserOut(BaseModel):
user_id: int
user_name: str
email: Optional[EmailStr] = None
full_name: Optional[str] = None
@app.post('/create_user/', response_model=UserOut)
async def create_user(user: UserIn):
user_dict = user.dict()
user_dict['user_id'] = 1
return user_dict
-
pydantic有自带的邮箱格式校验类型EmailStr, 不过需要额外进行安装,pydantic只会安装核心的功能pip install pydantic[email] -
这里定义的响应json模型
UserOut比UserIn多了user_id和少了pass_word字段 -
视图函数中返回的
user_dict中是包括了pass_word字段的, 但是由于设置了response_model=UserOut, fastapi会过滤掉其他的字段
其他响应参数选择
def post(...
response_model_include: Optional[Union[SetIntStr, DictIntStrAny]] = None,
response_model_exclude: Optional[Union[SetIntStr, DictIntStrAny]] = None,
response_model_by_alias: bool = True,
response_model_exclude_unset: bool = False,
response_model_exclude_defaults: bool = False,
response_model_exclude_none: bool = False,
...):
- response_model_include: 返回模型中需要包括哪些字段
- response_model_exclude: 返回模型中不能包括哪些字段
- response_model_exclude_unset: 设置为True的话那么响应模型中未显式设置具体值的字段则不会返回
响应模型类-Union
可以将一个响应声明为两种类型的 Union,这意味着该响应将是两种类型中的任何一种。
from typing import Union
class Student(BaseModel):
student_name: str
student_score: float
class Teacher(BaseModel):
teacher_name: str
teacher_num: str
items = {
'student': {'student_name': 'xiaoming', 'student_score': 90.3},
'teacher': {'teacher_name': 'li', 'teacher_num': 'NO.123'}
}
@app.get('/person/', response_model=Union[Student, Teacher])
async def get_person(item_type: str):
return items[item_type]
- 返回
Student模型类或者Teacher模型类
响应模型类-List
from typing import List
class Student(BaseModel):
student_name: str
student_score: float
students = [
{'student_name': 'xiaoming', 'student_score': 90.3},
{'student_name': 'xiaohong', 'student_score': 80.7}
]
@app.get('/students/', response_model=List[Student])
async def get_students():
return students
- 返回的是
Student模型类列表,List中只能有一种模型类型