一、概念
支持向量机是学习策略的间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化算法。
二、问题类型
1)训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,叫线性可分支持向量机,又称硬间隔支持向量机。
2)当训练数据近似线性可分时,加入松弛变量,通过软间隔最大化,叫线性支持向量机,又称软间隔支持向量机。
3)当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
三、线性可分支持向量机
点(a0,a1)到直线或者平面w0x0+w1x1+b的距离如下:

换成向量形式为:

定义超平面(w,b)关于训练集T的几何间隔为超平面(w,b)关于T中所有样本点(xi,yi)的几何间隔之最小值,几何间隔一般是实例点到超平面的带符号的距离,当样本点被超平面正确分类时就是实例点到超平面的距离。
在线性可分时,r=|w·x+b|等价为yi(w·xi+b),yi=±1,因为当样本被正确分类时,yi(w·xi+b)的乘积亦为正值,r又称为函数间隔
从上述点到平面的距离可以看出,当w和b成倍进行缩放的时候,距离是不变的,因为分子分母正好抵消。所以为了方便计算与优化,我们对w和b进行缩放,让离超平面最近的点(包含正负样本)的函数距离r=1,这样yi(w·xi+b)≥1恒成立。在满足函数间隔都大于等于1的情况下,我们力求几何间隔最大化,因为几何间隔最大,在图形上直观显示就是所有点离超平面都尽可能远,分类的置信度就越高。所以我们的优化目标变为:

转化为求最小值如下:
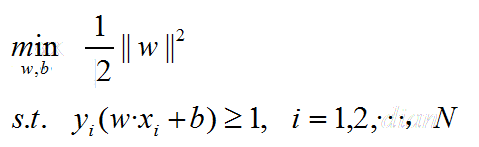
这是一个约束条件下求极值的凸二次规划问题,可以采用拉格朗日对偶性方法求极值,最后就得到超平面w*·x+b*=0及分类决策函数f(x)=sign(w*·x+b*),即线性可分支持向量机。
拉格朗日对偶性求解:
优化目标(拉格朗日不等式约束条件下求极值,条件不等式必须转化为≤0的形式):
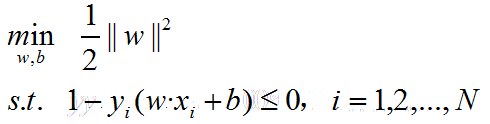
定义拉格朗日函数:

根据拉格朗日对偶性,原始问题的对偶问题是极大极小问题:
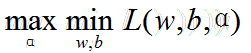
步骤如下:
1)求minL(w,b,α),将拉格朗日函数L分别对w,b求偏导数并令其等于0,可以求得w和b
2)将求得的w和b带入拉格朗日函数,变成了只有α的函数,再求对α的极大值
求解得:

知识点
1、最大超平面是有几个,哪些是支持向量?
最大分离超平面存在且唯一。支持向量就是函数间隔为1的那些点,在决定分离超平面时只有支持向量起作用,其它实例点不起作用,支持向量的个数很少,所以支持向量机由很少的"重要的"训练样本确定。
2.为什么起作用的只有支持向量?
1)首先,在对w,b进行缩放的时候,就是让离超平面最近的样本点也即支持向量的函数距离r=1,所以初始w,b的值就是有支持向量来确定的,然后再最大化几何间隔的时候,也是在r=1的前提下,最大化超平面和支持向量的几何间隔距离,其它样本点根本没有参与到优化当中。
2)其次,在拉格朗日对偶求解过程中,满足kkt条件才能求得原问题最优解,1-yi(w*·xi+b*≤0,αi*(1-yi(w*·xi+b*))=0,如果αi都等于0, 这求得的权重w=0,b=0,显然不是最优超平面,所有必有αi>0出现,而这个时候1-yi(w*·xi+b*)就等于0,所以这些点就是支持向量,最后求解的w就是根据支持向量求得的。
四、线性支持向量机
线性可分问题的支持向量机学习方法,对线性不可分训练数据是不适用的,因为这时上述方法中的不等式约束条件并不能成立,如下图所示:

从上图可知,线性不可分意味着样本点(x,y)不能满足函数间隔≥1的约束条件,正负样本点出现混杂在一起的情况,这个时候如果从中间画一个超平面,分错的样本点的函数间隔就会为负值。为了解决此问题,使其满足该条件,为每个样本都引入一个松弛变量ξi,ξi≥0。
当ξi=0时,代表样本点函数间隔正好为1;
当0<ξi<1时,代表样本点位于支持向量所在的线与超平面之间,分类依旧正确;
当ξi=1时,代表样本点位于分类超平面上。
当1<ξi时,代表样本点已经被分错。
也就是说松弛变量只为分错的点,以及函数间隔≤1的样本点设置,最终让他们的函数间隔等于1,所以ξi只可能≥0,不可能小于0。
加入松弛变量后,约束条件就变为:

同时,对每个松弛变量ξi,在目标函数中支持一个代价,最终优化目标如下:
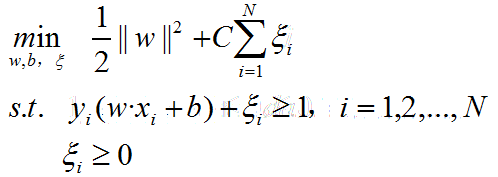
C>0称为惩罚参数,C值增大对误分类的惩罚增大,C值小时对误分类的惩罚减小。最优化目标的含义为:使1/2||w||2尽量小即间隔尽量大的情况下,同时使误分类点的个数尽量少。
求解依然采用拉格朗日对偶法,同上述线性可分支持向量机。
知识点
1.为什么要引入松弛变量?
可以参考上述线性不可分的图例,中间混杂了很多正负样本点,属于近似线性可分但又不能线性可分的情况,这个时候无法按照线性可分的约束条件进行求解,为了转变为线性可分条件,才引入了松弛变量。另外引入松弛变量可以防止过拟合,同样参考上述图例,如果将混杂的样本点完全分开,就会画出一条曲曲折折的曲线,而这样的曲线并不一定是真正两种类别的合理分割线或者说分割面,中间混杂的部分有可能是噪音数据,所以不能完全迎合这些样本点来画分割面,避免陷入过拟合状态。合理的方法,就是图例所画的超平面,引入松弛变量,在混杂数据中间画一条超平面,让大部分数据能够分开即可,不迎合一部分噪音数据。
合页损失函数(hinge loss)
Hinge loss专用于二分类问题,y为真实label,y^为预测值,函数如下:

当预测值被完全正确分为±1的时候,损失最小loss=0,当正样本预测值为0.9,loss=0.1;当正样本预测值为-0.8,这个时候样本已经被误分,loss=1.8损失变得比较大。

从上述图示看得出,当样本点的函数间隔≥1时候,loss就开始持续为0;当函数间隔<1的时候,loss就越来越大。
SVM可以通过直接最小化合页损失函数求得最优的分离超平面,目标函数如下:

其等价于上述引入松弛变量的优化函数,证明如下:
令1-yi(w·xi+b)=ξi,通过前面松弛变量部分可得知,ξi的值只可能≥0,这个跟max(0,1-yi(w·xi+b))取值一致,而且其实就是一模一样的取值,因为通过前面松弛变量部分可知,松弛变量只为那些函数间隔≤1的样本点设置,而最终设置值就是让他们函数间隔r=1,所以这些样本点1-yi(w·xi+b)=ξi,而起作用的样本点就是这些函数间隔r=1的样本点,其它r>1的样本点完全不起作用。所以上述合页损失函数可以变为如下:
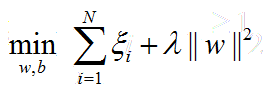
至于前面的惩罚参数C,则可以另λ=1/2*C,再整体乘以参数C就保持一致了。
为什么叫合页损失函数呢?
根据上述图示可知,损失函数的图形像一个合页,因而叫合页损失函数。
五、非线性支持向量机
用线性分类方法求解非线性分类问题分为两步:
1)利用核技巧将原空间的数据映射到新空间
2)在新空间里用线性分类学习方法从训练数据中学习分类模型。
核技巧的想法是,在学习与预测中只定义核函数K(x,z),而不显式地定义映射函数,也就是学习是隐式地在特征空间进行的,不需要显式地定义特征空间和映射函数。