一、模型框架图

二、分层介绍
1)ALBERT层
albert是以单个汉字作为输入的(本次配置最大为128个,短句做padding),两边分别加上开始标识CLS和结束标识SEP,输出的是每个输入word的embedding。在该框架中其实主要就是利用了预训练模型albert的词嵌入功能,在此基础上fine-tuning其后面的连接参数,也就是albert内部的训练参数不参与训练。
2)BiLSTM层
该层的输入是albert的embedding输出,一般中间会加个project_layer,保证其输出是[batch_szie,num_steps, num_tags]。batch_size为模型当中batch的大小,num_steps为输入句子的长度,本次配置为最大128,num_tags为序列标注的个数,如图中的序列标注一共是5个,也就是会输出每个词在5个tag上的分数,由于没有做softmax归一化,所以不能称之为概率值。
3)CRF层
如果没有CRF层,直接按BiLSTM每个词在5个tag的最大分数作为输出的话,可能会出现【B-Person,O,I-Person,O,I-Location】这种序列,显然不符合实际情况。CRF层可以加入一些约束条件,从而保证最终预测结果是有效的。
例如:
句子的开头应该是“B-”或“O”,而不是“I-”。
“B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Location”则是错误的。
“O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
这些约束可以在训练数据时被CRF层自动学习得到,这种异常的序列出现概率就会大大降低。
三、如何训练?
在从BiLSTM层进入到CRF层时,会有多种路径选择,像上图中会有5x5x5x5x5种路径可能,假设s是我们要寻找的正确路径,其出现的概率如下:
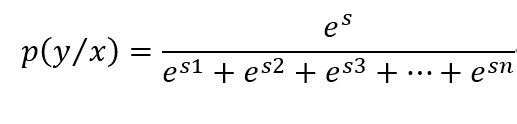
es是当前序列的分数,分母是所有序列分数的和,这也是我们的求解loss function。
传统CRF主要由特征函数组成,一个是状态特征函数,一个是转移特征函数,函数的值要么为1,要么为0,通过训练其权重λ来改变特征函数的贡献。而这里对路径s的训练没有权重,但也是由两部分组成:
1)EmissionScore(发射分数):由BiLSTM层训练输出的每个位置对各个tag的分数,就是上图中输出的红色字体分数。
2)TransitionScore (转移分数): 这部分主要由CRF层训练得到,如下图
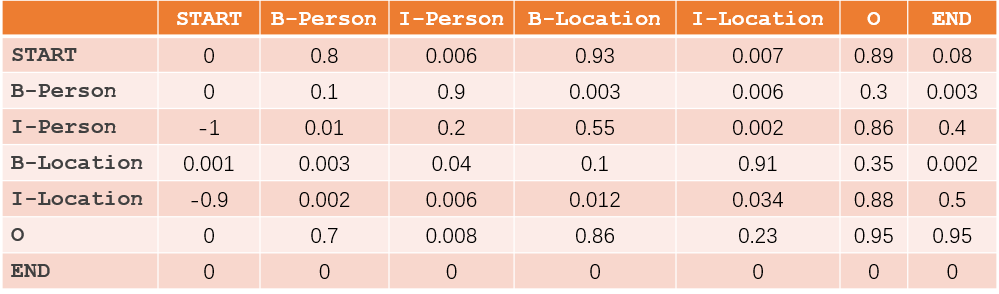
所以,S=EmissionScore+TransitionScore
举例:
对于序列来说,比如有一个序列是“START B-Person I-Person O B-Location O END”,则
EmissionScore=x0,START+x1,B-Person+x2,I-Person+x3,O+x4,B-Location+x5,O+x6,END
TransitionScore=tSTART−>B-Person+tB−Person−>I-Person+tI-Person−>O+t0−>B-Location+tB-Location