作者:无影随想
时间:2016年1月。
出处:http://www.zhaokv.com/2016/01/normalization-and-standardization.html
在机器学习和数据挖掘中,经常会听到两个名词:归一化(Normalization)与标准化(Standardization)。它们具体是什么?带来什么益处?具体怎么用?本文来具体讨论这些问题。


三、各自的作用
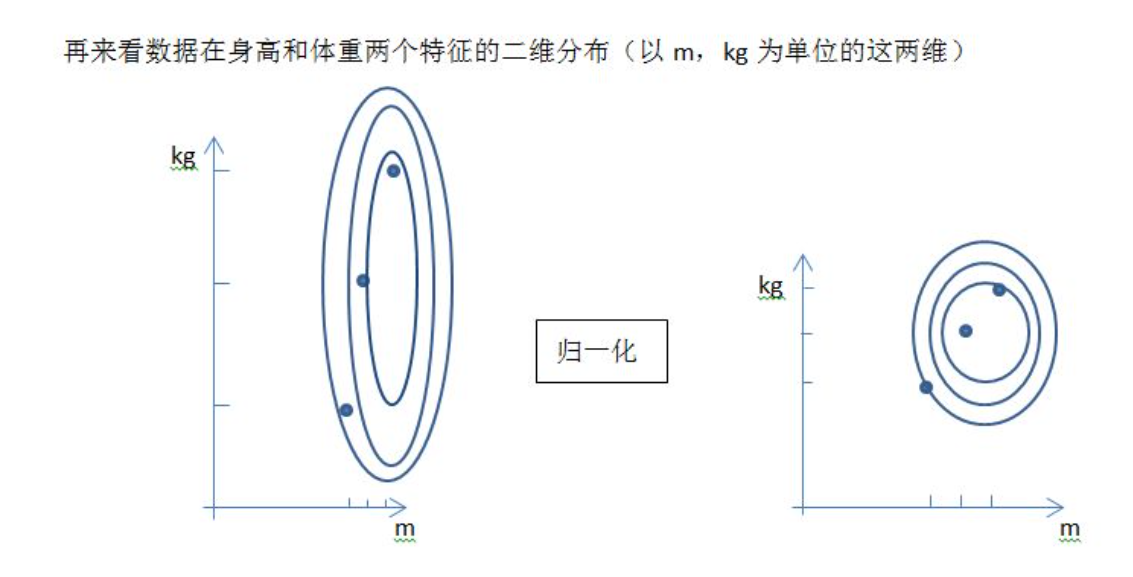
1归一化
特点
对不同特征维度的伸缩变换的目的是使各个特征维度对目标函数的影响权重是一致的,即使得那些扁平分布的数据伸缩变换成类圆形。这也就改变了原始数据的一个分布。
好处:
1 提高迭代求解的收敛速度
2 提高迭代求解的精度
2标准化
特点
对不同特征维度的伸缩变换的目的是使得不同度量之间的特征具有可比性。同时不改变原始数据的分布。
好处
1 使得不同度量之间的特征具有可比性,对目标函数的影响体现在几何分布上,而不是数值上
2 不改变原始数据的分布

四、怎么用
在涉及到计算点与点之间的距离时,使用归一化或标准化都会对最后的结果有所提升,甚至会有质的区别。那在归一化与标准化之间应该如何选择呢?根据上一节我们看到,如果把所有维度的变量一视同仁,在最后计算距离中发挥相同的作用应该选择标准化,如果想保留原始数据中由标准差所反映的潜在权重关系应该选择归一化。另外,标准化更适合现代嘈杂大数据场景。