最近学习oracle的一些知识,发现自己sql还是很薄弱,需要继续学习,现在总结一下哈。
(1)oracle递归查询 start with ... connect by prior ,至于是否向上查询(根节点)还是向下查询(叶节点),主要看prior后面跟的字段是否是父ID。
向上查询:select * from test_tree_demo start with id=1 connect by prior pid=id
查询结果:

向下查询:select * from test_tree_demo start with id=3 connect by prior id=pid

如果要进行过滤,where条件不能放在connect by 后面,如下:select * from test_tree_demo where id !=4 start with id=1 connect by prior pid=id

(2)分析函数- over( partition by )
数据库中的数据如下:select * from testemp1

select deptno,ename,sal,sum(sal)over() deptsum from testemp1 如果over中不加任何条件,就相当于sum(sal),显示结果如下:

一般over都是配合partition by order by 一起使用,partition by 就是分组的意思。下面看个例子:按部门分组,同个部门根据姓名进行工资累计求和。
select deptno,ename,sal,sum(sal)over(partition by deptno order by ename) deptsum from testemp1,显示如下:

其实统计各个部门的薪水总和,可以使用group by实现,select deptno,sum(sal) deptsum from testemp1 group by deptno,结果如下:

但是,使用group by 的时候查询出来的字段必须是分组的字段或者聚合函数。例如查询结果多加个ename字段。使用partition by 就简单了。
select deptno,ename,sum(sal) over (partition by deptno) from testemp1,显示如下:

(3)分析函数-rank(),dense_rank(),row_number()
select deptno,ename,sal,rank() over(partition by deptno order by sal) from testemp1,结果如下:

select deptno,ename,sal,dense_rank() over(partition by deptno order by sal) from testemp1,结果如下:

可以看出使用rank()和dense_rank()的区别了吧。接下来在看看row_number()
select deptno,ename,sal,row_number() over(partition by deptno order by sal desc) from testemp1,显示结果如下:
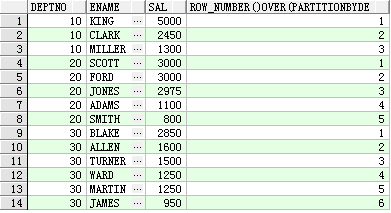
(4)分析函数-group by rollup
根据部门分组,统计各个部门各个职位的薪水总和。
select group_id,job,sum(salary) as salary from group_test group by rollup (group_id,job),显示结果如下:

group by rollup (a,b,c)相当于group by (a,b,c) union group by(a,b) union group by (a) union 全表。
上述结果可以用group by 与 union实现,如下:order by 1 ,2 就是根据第一二列进行排序
select group_id, job, sum(salary) from group_test group by group_id, job
union all
select group_id, null, sum(salary) from group_test group by group_id
union all
select null, null, sum(salary) from group_test
order by 1, 2;
可以结合grouping()函数一起使用,如下:
select group_id,case when grouping(group_id) = 0 and grouping(job) = 1 then '小计'
when grouping(group_id) = 1 and grouping(job) = 1 then '总计'
else job end as job,
sum(salary) as salary
from group_test
group by rollup(group_id, job);
显示如下:当grouping()为空的时候返回1,非空返回0.

(5)分析函数-group by cube
group by cube(a,b)=group by(a,b) union group by (a) union group by (b) union (全表)
select group_id,job,sum(salary) as salary from group_test group by cube (group_id,job),显示如下:

上述结果可以用group by 与 union实现,如下:
select group_id, job, sum(salary) from group_test group by group_id, job
union all
select group_id, null, sum(salary) from group_test group by group_id
union all
select null, job, sum(salary) from group_test group by job
union all
select null, null, sum(salary) from group_test
order by 1, 2;
(5)merge into
最近接触到oracle这个函数,感觉挺好的。假如我们现在有两个表A,B,其中有部分数据是A ,B表一样的,有一部分数据是B有的,而A表没有的,现在有一个需求,将两个表整合在一个表中。那么按照之前,我们一般都是根据A表某个唯一的字段查询B表,如果存在,则跳过,不存在则插入到A表。要实现这个需求,我们需要两步才能实现,如果使用merge into 则方便很多了。
merge into的结构如下:
MERGE INTO table_name alias1
USING (table|view|sub_query) alias2
ON (join condition)
WHEN MATCHED THEN
UPDATE table_name
SET col1 = col_val1,
col2 = col_val2
WHEN NOT MATCHED THEN
INSERT (column_list) VALUES (column_values);
下面我们看一个简单的例子: A表:group_test B表:testemp1
A表的数据如下: B表的数据如下:
B表的数据如下:
现在将B中deptno为50的数据插入到A表,如下:
merge into group_test t1
using (select * from testemp1 where deptno = 50) t2
on (t1.group_id = t2.deptno)
when matched then
update set t1.salary = 1000
when not matched then
insert (group_id, job,name,salary) values (t2.deptno,t2.ename,'gdpuzxs',5000)
显示如下: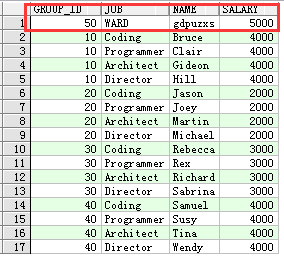 因为A表中没有group_id=50,所以执行插入。
因为A表中没有group_id=50,所以执行插入。
接着,我们在执行一下上面那个语句,
显示如下: 因为A表中存在group_id=50,所以执行更新操作。
因为A表中存在group_id=50,所以执行更新操作。