首先我们来看下面一组数据集: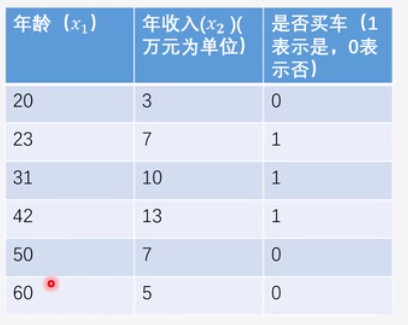
前面的x1与x2都表示的是年收入和年龄这两个因素决定的是否买车的结果。
开始代码部分,我们先输入x和y的变量,开始输入数据:
from sklearn import linear_model X=[[20,3], [23,7], [31,10], [42,13], [50,7], [60,5]]
Y=[0, 1, 1, 1, 0, 0]
拟合逻辑回归模型:
lr=linear_model.LogisticRegression(solver='liblinear')#在新版的sklearn当中只需要指定后面的参数值就不会进行报错啦! lr.fit(X,Y)
这个时候我们的模型已经拟合好了,现在可以开始进行输出了,随便用一个数据来测试在这个模型下这个人是否买车,以及是否买车的概率:
textX=[[28,8]] lable=lr.predict(textX)#看它是否有车,1表示有
输出:
array([1])
输出为一,说明这个人已经买车了,下面是输出概率:
#现在输出有车的概率 predict=lr.predict_proba(textX)
predict
输出为:
array([[0.14694811, 0.85305189]])
#前面有两个值,这是因为前面的一个概率预测为0的概率,后面的为概率预测为1的概率
得解也,逻辑回归模型的编程还是十分容易的啦