一.seq2seq机制
传统的seq2seq机制在语言翻译当中使用了两个RNN,一个是encoder,将语言进行编码,另一个是decoder,将我们的得到的语言编码进行解码,解码的过程当中就可以对我们的语言进行翻译成另外一种语言。其机制如下所示:

当然这种机制了,就会出现一定的问题,比如说我们的一个hidden layer就需要捕捉到整句话的所有信息,但是实际上我们有些位于前面的一些信息可能就会有所遗漏,同样的,一些本来应该是比较重要的信息,可能模型觉得并没有那么重要。
例如输入的英文句子是:Tom chase Jerry,目标的翻译结果是:汤姆追逐杰瑞。在未考虑注意力机制的模型当中,模型认为 汤姆 这个词的翻译受到 Tom,chase 和 Jerry 这三个词的同权重的影响。但是实际上显然不应该是这样处理的,汤姆 这个词应该受到输入的 Tom 这个词的影响最大,而其它输入的词的影响则应该是非常小的。显然,在未考虑注意力机制的 Encoder-Decoder 模型中,这种不同输入的重要程度并没有体现处理,一般称这样的模型为 分心模型。
因此我们引入注意力机制,也就是attention来改变这个现状。
二.Attention注意力机制的原理
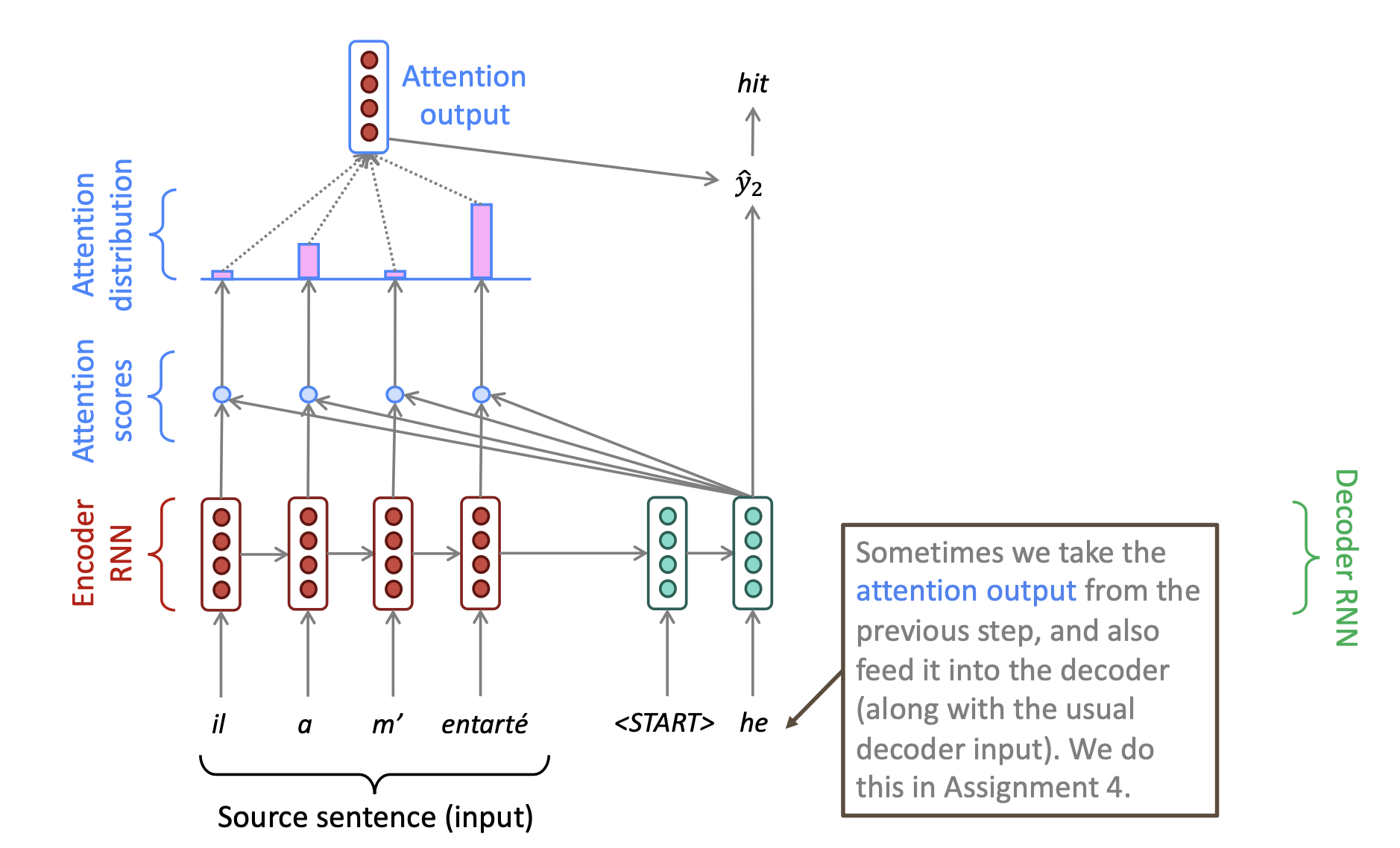
Attention is all you need 是 杨力坤的名言。我们来看看attention注意力机制具体是怎么实现的。首先,我们将decoder的第一个hidden layer的值分别和encoder当中的每一个值进行相乘,也就是进行dot product,得到一个attention score。如下图所示:
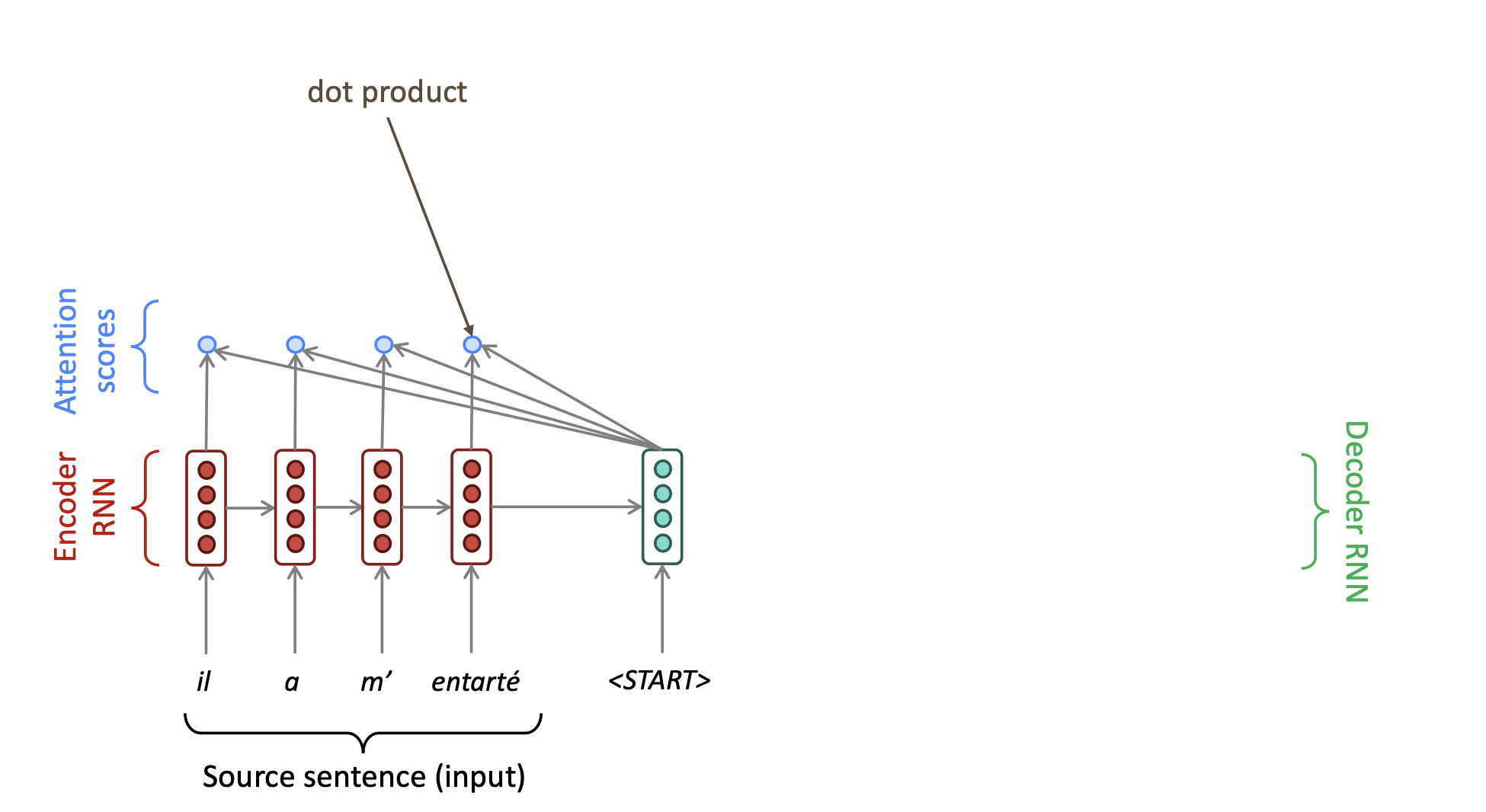
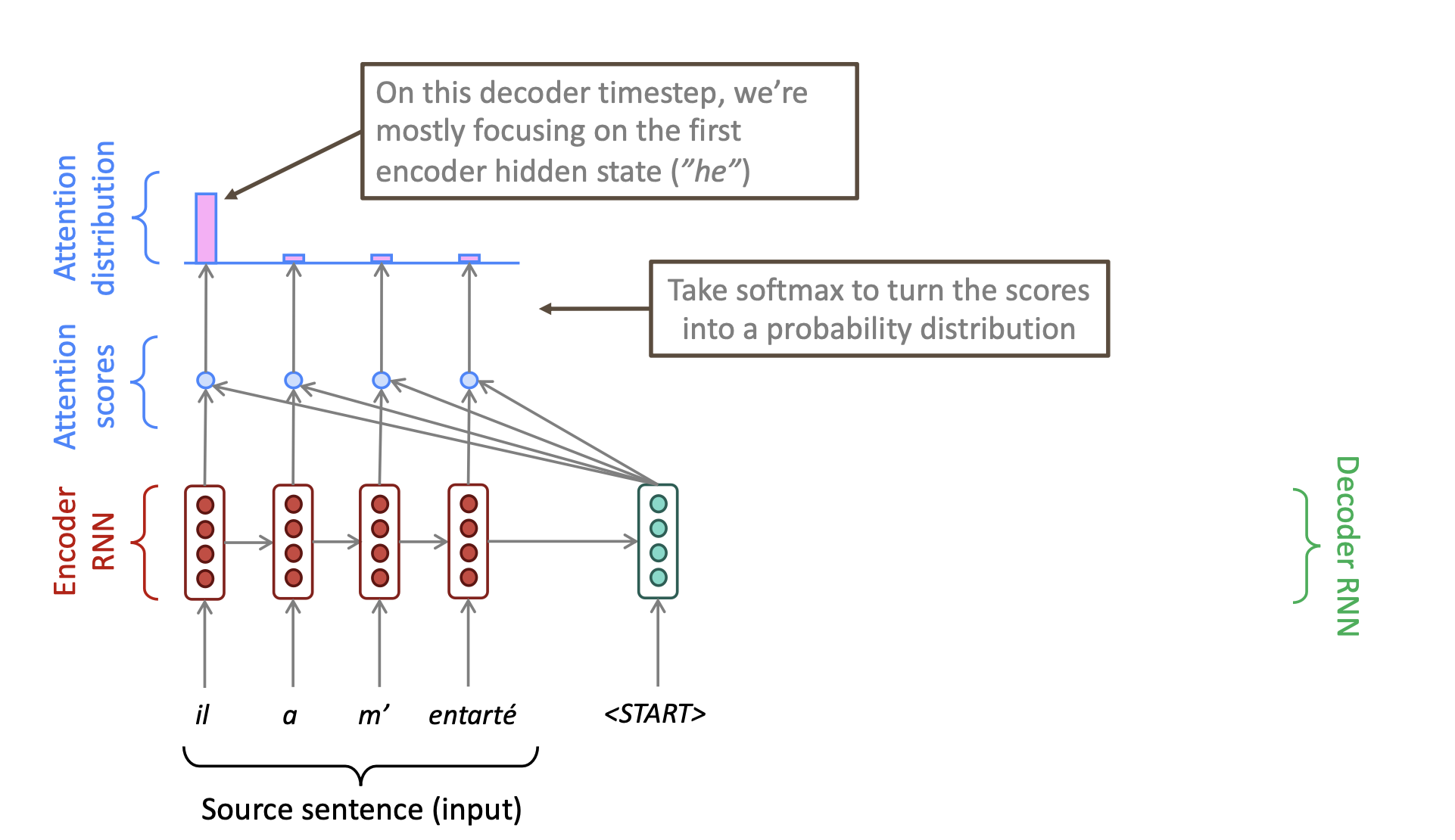
然后我们对这些dot product的结果使用softmax,得到一个概率分布,众所周知,softmax得到的概率只和为1. 而使用softmax之后的概率分布,我们这里称之为attention distribution。我们发现这些第一个encoder unit的attention score经过softmax之后,其概率。说明当前我们的attention,注意力主要集中在了第一个encoder unit上。机器的主要注意力在于翻译当前这个unit所对应的单词。
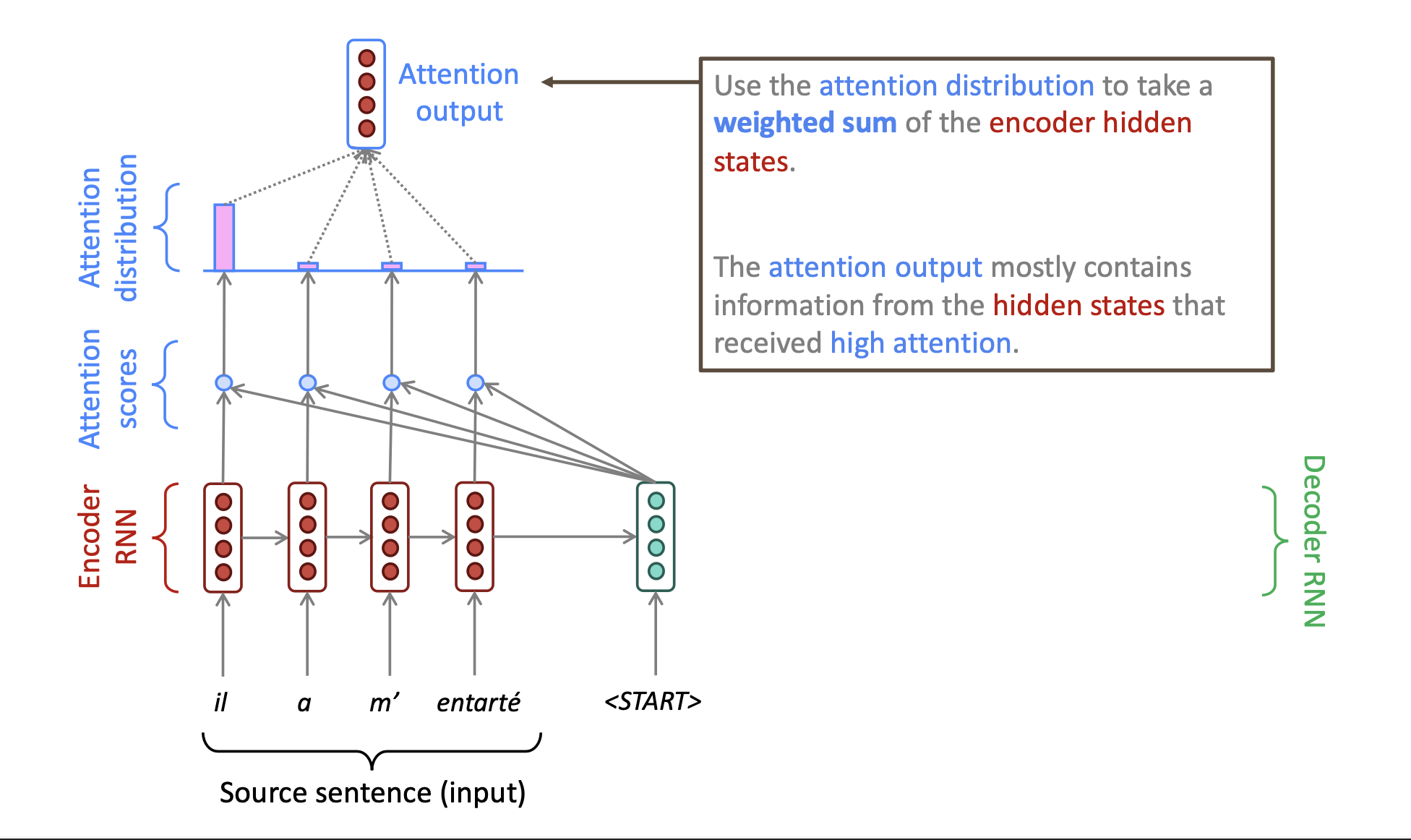
然后我们对这个attention distribution使用weighted sum来计算当前encoder的hidden states作为一个我们的attention output,形成一个vector。应该就是将attention distribution的结果转换成了一个vector。
然后我们将这个vector和attention作用于的那个decoder进行拼接,用这个拼接的结果来计算我们最后输出的翻译结果。
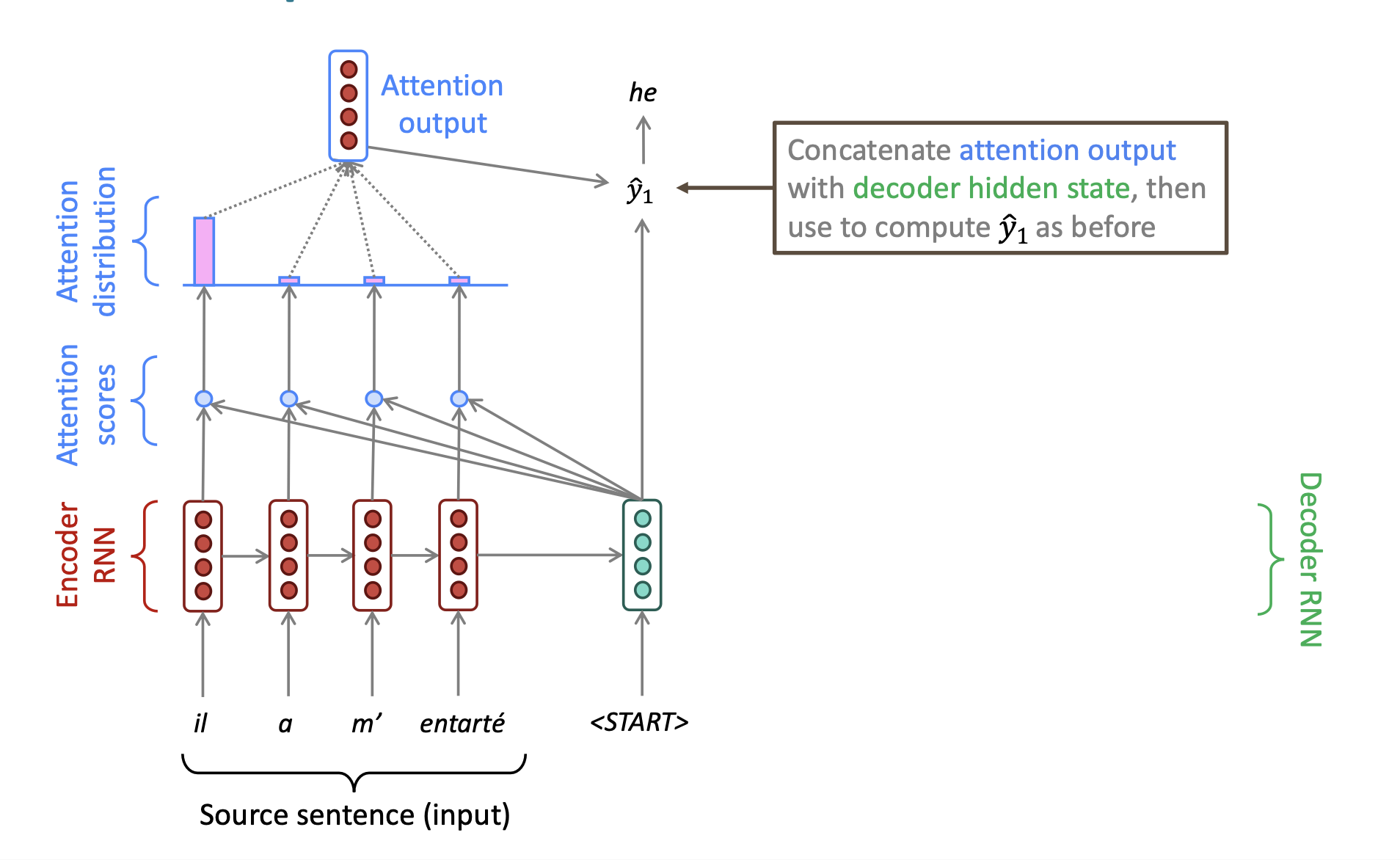
最后使用刚才的这个结果作为我们第二个hidden layer的一个输入(一般可以这样做)。然后再进行第二次attention,得到我们得二个hidden layer的预测结果为单词:hit。然后依次重复这样的过程,得到我们最后的翻译结果。
最后的最后,我们对attention机制进行一个总结。
其中,我们的hidden states或者hidden layer可以称之为h1,h2.....hN,然后我们通过dot product可以得到我们的一个attention score:et
将这个et放入softmax函数当中,得到attention distribution: at 我们再使用这个at 来计算weighted sum ,而这个weight是我们hidden state(layer)的一个权重(终于豁然开朗,知道这个weighted sum怎么来的了!)
最后进行组合和拼接(左右互相拼接,不是上下),就得到了我们的预测值啦!具体公式如下图所示:
,