爬虫代理概述
- 在爬虫中,所谓的代理指的就是代理服务器
- 代理服务器的作用就是用来转发请求和响应
- 如果我们的爬虫在短时间内对服务器发起高频的请求,那么服务器会检测到这样的一个异常行为请求,就会将该请求对应设备的ip进行封禁,设备就无法对服务器再次进行请求发送了
- 使用代理服务器进行信息爬取,可以很好的解决IP限制的问题
一般模式: 客户端 ----> 服务器端
代理模式: 客户端----> 代理 -----> 服务器端 - 我们浏览信息的时候,先向代理服务器发出请求,然后又代理服务向互联网获取信息,再返回给我们
- 代理服务器分为不同的匿名度
- 透明代理:如果使用了该形式的代理,服务器端知道你使用了代理机制也知道你真是ip
- 匿名代理:知道你使用代理,但是不知道你的真实ip
- 高匿代理:不知道你使用代理,也不知道你真实ip
- 代理的类型:
- https: 代理只能转发https协议的请求
- http:转发http的请求
- 购买代理服务器:
- 快代理
- 西祠代理
- goubanjia
- 代理精灵(推荐):
http://http.zhiliandaili.cn


# -*- coding: utf-8 -*-
import requests
from lxml import etree
import random
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
} #模仿浏览器UA头
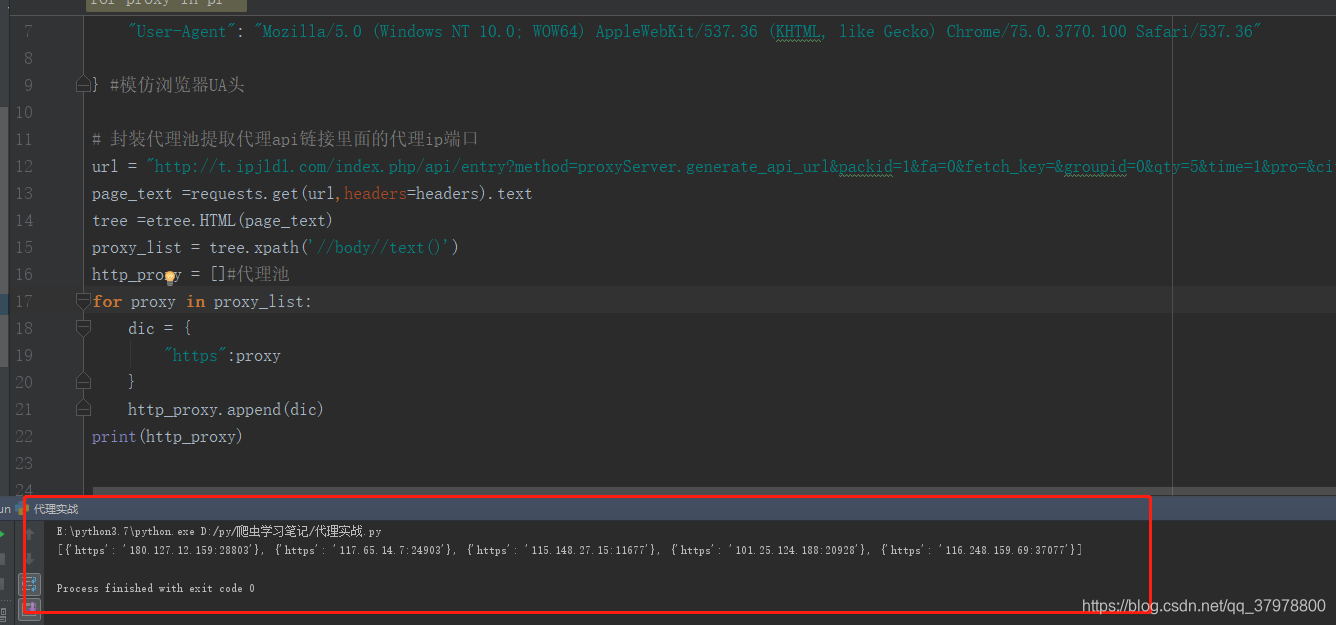
# 封装代理池提取代理api链接里面的代理ip端口
url = "http://t.ipjldl.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=5&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15"
page_text =requests.get(url,headers=headers).text
tree =etree.HTML(page_text)
proxy_list = tree.xpath('//body//text()')
http_proxy = []#代理池
for proxy in proxy_list:
dic = {
"https":proxy
} #封装成一个 http/https : 代理ip 的字典
http_proxy.append(dic) #把结果追加到16行定义的代理池列表中
print(http_proxy)
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import random
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
} #模仿浏览器UA头
# 封装代理池提取代理api链接里面的代理ip端口
url = "http://ip.ipjldl.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=10&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15"
page_text =requests.get(url,headers=headers).text
tree =etree.HTML(page_text)
proxy_list = tree.xpath('//body//text()')
http_proxy = []#代理池
for proxy in proxy_list:
dic = {
"https":proxy
} #封装成一个 http/https : 代理ip 的字典
http_proxy.append(dic) #把结果追加到16行定义的代理池列表中
print(http_proxy)
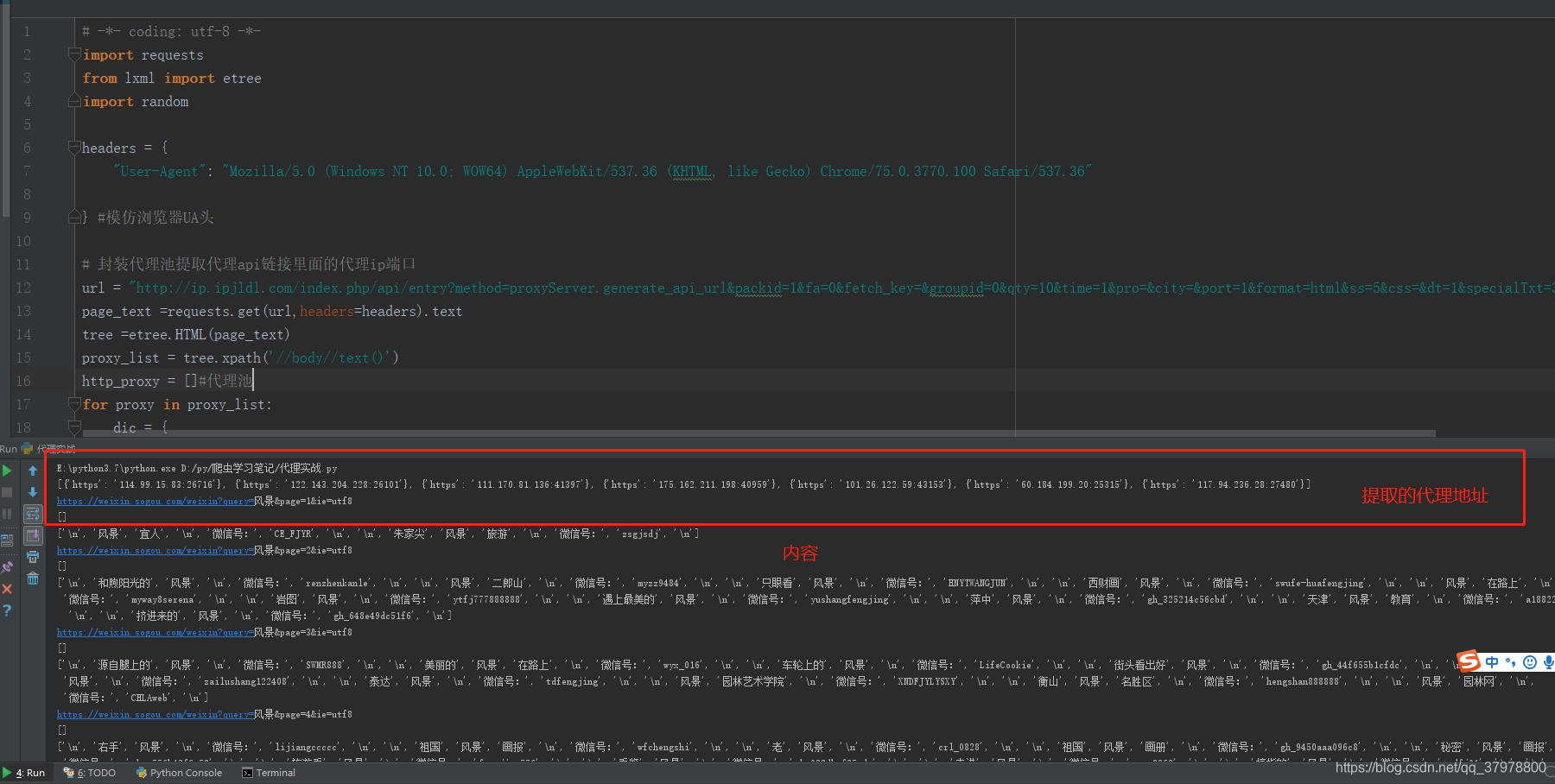
url2 = "https://weixin.sogou.com/weixin?query=风景&page=%d"+"&ie=utf8" ##定义通用翻页url
for pg in range(1,100):
new_url = format(url2%pg) ##定义通用翻页url
print(new_url)
html2 = requests.get(url=new_url,headers=headers,proxies=random.choice(http_proxy)).text
tree2 = etree.HTML(html2)
title = tree2.xpath("//div[@class='txt-box']/h3/a//text()")
print(title)
nr = tree2.xpath("//div[@class='txt-box']/p//text()")
print(nr)
使用代理爬取搜狗商品

# -*- coding: utf-8 -*-
import requests
from lxml import etree
import random
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
} #模仿浏览器UA头
#封装代理池提取代理api链接里面的代理ip端口
url = "http://t.ipjldl.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=200&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15"
page_text =requests.get(url,headers=headers).text
tree =etree.HTML(page_text)
proxy_list = tree.xpath('//body//text()')
http_proxy = []#代理池
for proxy in proxy_list:
dic = {
"https":proxy
} #封装成一个 http/https : 代理ip 的字典
http_proxy.append(dic) #把结果追加到定义的代理池列表中
print(http_proxy)
url2 = "https://gouwu.sogou.com/shop?ie=utf8&query=2020&p=40251501&sourceid=sr_bpage&page=%d" ##定义通用翻页url
for pg in range(1,100):
new_url = format(url2%pg) ##定义通用翻页url
print(new_url)
html2 = requests.get(url=new_url,headers=headers,proxies=random.choice(http_proxy)).text#携带代理池
tree2 = etree.HTML(html2)
title = tree2.xpath('//h4/a//text()')
for title1 in title:
print(title1)
