维基百科,自由的百科全书
在统计学中,最大后验估计是根据经验数据获得对难以观察的量的点估计。它与最大似然估计中的经典方法有密切关系,但是它使用了一个增大的优化目标,这种方法将被估计量的先验分布融合到其中。所以最大后验估计可以看作是规则化(regularization)的最大似然估计。
假设我们需要根据观察数据  估计没有观察到的总体参数
估计没有观察到的总体参数  ,让
,让  作为 的采样分布,这样
作为 的采样分布,这样 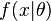 就是总体参数为 时 的概率。函数
就是总体参数为 时 的概率。函数
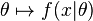
即为似然函数,其估计

就是 的最大似然估计。
假设 存在一个先验分布  ,这就允许我们将 作为 贝叶斯统计(en:Bayesian statistics)中的随机变量,这样 的后验分布就是:
,这就允许我们将 作为 贝叶斯统计(en:Bayesian statistics)中的随机变量,这样 的后验分布就是:
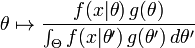
其中  是 的domain,这是贝叶斯定理的直接应用。
是 的domain,这是贝叶斯定理的直接应用。
最大后验估计方法于是估计 为这个随机变量的后验分布的众数:

后验分布的分母与 无关,所以在优化过程中不起作用。注意当前验 是常数函数时最大后验估计与最大似然估计重合。
最大后验估计可以用以下几种方法计算:
- 解析方法,当后验分布的模能够用 closed form 方式表示的时候用这种方法。当使用en:conjugate prior 的时候就是这种情况。
- 通过如共扼积分法或者牛顿法这样的数值优化方法进行,这通常需要一阶或者导数,导数需要通过解析或者数值方法得到。
- 通过 期望最大化算法 的修改实现,这种方法不需要后验密度的导数。
尽管最大后验估计与 Bayesian 统计共享前验分布的使用,通常并不认为它是一种 Bayesian 方法,这是因为最大后验估计是点估计,然而 Bayesian 方法的特点是使用这些分布来总结数据、得到推论。Bayesian 方法试图算出后验均值或者中值以及posterior interval,而不是后验模。尤其是当后验分布没有一个简单的解析形式的时候更是这样:在这种情况下,后验分布可以使用 Markov chain Monte Carlo 技术来模拟,但是找到它的模的优化是很困难或者是不可能的。
最大后验估计是根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中。故最大后验估计可以看做规则化的最大似然估计。
以下转载:http://www.cnblogs.com/liliu/archive/2010/11/24/1886110.html
首先,我们回顾上篇文章中的最大似然估计,假设 $x$为独立同分布的采样,$\theta$为模型参数,$f$为我们所使用的模型。那么最大似然估计可以表示为:

现在,假设θ的先验分布为g。通过贝叶斯理论,对于θ的后验分布如下式所示:

最后验分布的目标为:

注:最大后验估计可以看做贝叶斯估计的一种特定形式。
举例来说:
假设有五个袋子,各袋中都有无限量的饼干(樱桃口味或柠檬口味),已知五个袋子中两种口味的比例分别是
樱桃 100%
樱桃 75% + 柠檬 25%
樱桃 50% + 柠檬 50%
樱桃 25% + 柠檬 75%
柠檬 100%
如果只有如上所述条件,那问从同一个袋子中连续拿到2个柠檬饼干,那么这个袋子最有可能是上述五个的哪一个?
我们首先采用最大似然估计来解这个问题,写出似然函数。假设从袋子中能拿出柠檬饼干的概率为p(我们通过这个概率p来确定是从哪个袋子中拿出来的),则似然函数可以写作

由于p的取值是一个离散值,即上面描述中的0,25%,50%,75%,1。我们只需要评估一下这五个值哪个值使得似然函数最大即可,得到为袋子5。这里便是最大似然估计的结果。
上述最大似然估计有一个问题,就是没有考虑到模型本身的概率分布,下面我们扩展这个饼干的问题。
假设拿到袋子1或5的机率都是0.1,拿到2或4的机率都是0.2,拿到3的机率是0.4,那同样上述问题的答案呢?这个时候就变MAP了。我们根据公式

写出我们的MAP函数。

根据题意的描述可知,p的取值分别为0,25%,50%,75%,1,g的取值分别为0.1,0.2,0.4,0.2,0.1.分别计算出MAP函数的结果为:0,0.0125,0.125,0.28125,0.1.由上可知,通过MAP估计可得结果是从第四个袋子中取得的最高。
上述都是离散的变量,那么连续的变量呢?假设 为独立同分布的
为独立同分布的 ,μ有一个先验的概率分布为
,μ有一个先验的概率分布为 。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:
。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:

此时我们在两边取对数可知。所求上式的最大值可以等同于求

的最小值。求导可得所求的μ为

以上便是对于连续变量的MAP求解的过程。
在MAP中我们应注意的是:
MAP与MLE最大区别是MAP中加入了模型参数本身的概率分布,或者说。MLE中认为模型参数本身的概率的是均匀的,即该概率为一个固定值。