首先我们先去有道词典网站
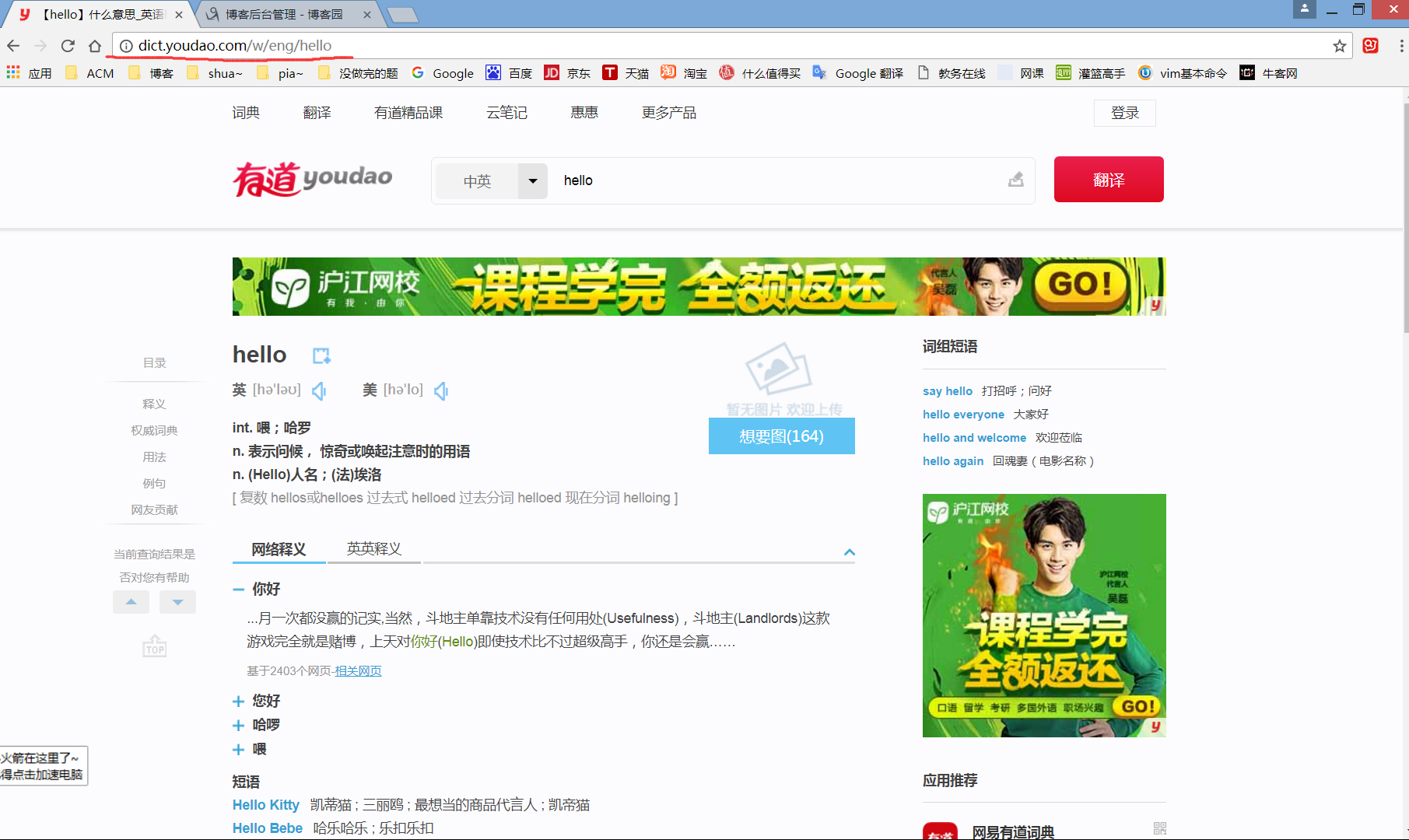
找到这个网址的格式
然后
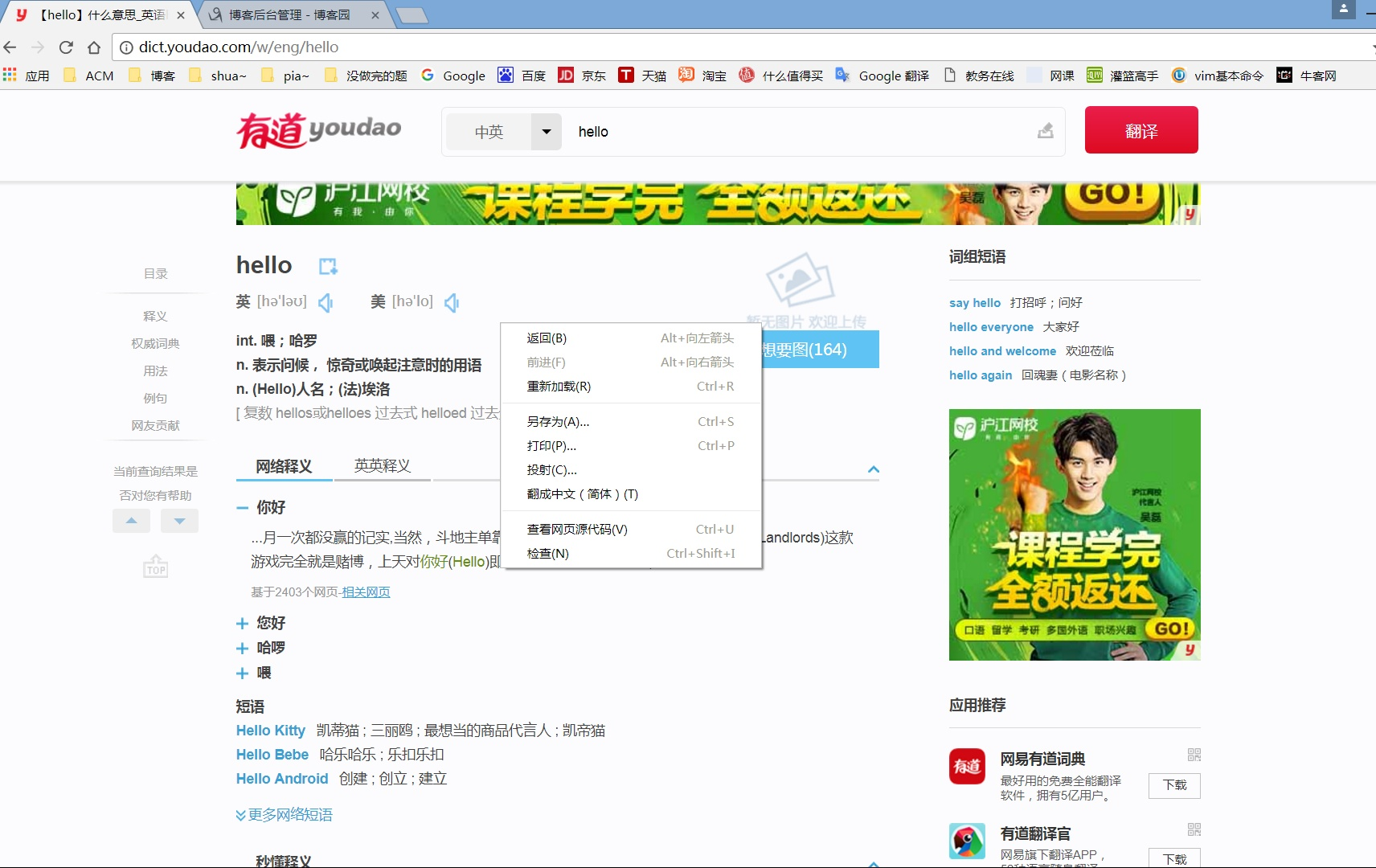
右键网页源代码
找到翻译所在的部分 并记录下来

现在浏览器部分的任务就完成了
我们现在开始敲代码
首先是url 就是有道的网址和我们要查找的单词
url = 'http://dict.youdao.com/w/eng/%s' % word
然后我们用urllib2去抓取网页的包
page = urllib2.urlopen(url).read()
之后我们用BeautifulSoup去解析page
data = BeautifulSoup(page, 'lxml')
最后用我们记下的标签去找相应的内容就行了
data.findAll('div', attrs={'class': 'trans-container'})[0].findNext('ul').text
整体代码:
1 import urllib2 2 from bs4 import BeautifulSoup 3 4 def query(word): 5 url = 'http://dict.youdao.com/w/eng/%s' % word 6 page = urllib2.urlopen(url).read() 7 data = BeautifulSoup(page, 'lxml') 8 return data.findAll('div', attrs={'class': 'trans-container'})[0].findNext('ul').text 9 10 if __name__ == '__main__': 11 while True: 12 print(query(raw_input()))
运行结果:
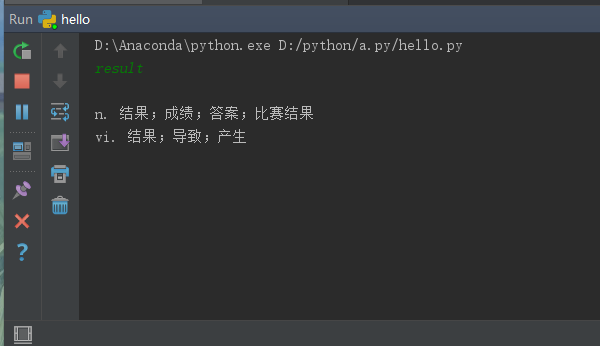
哇你看是不是学个爬虫很简单