学习链接:https://zhuanlan.zhihu.com/p/28680797
主要呢是用了chrome driver去模拟滚动和点击
同样是用了beautiSoup去解析html文件
解析出图片的url之后转码之后下载图片
代码:
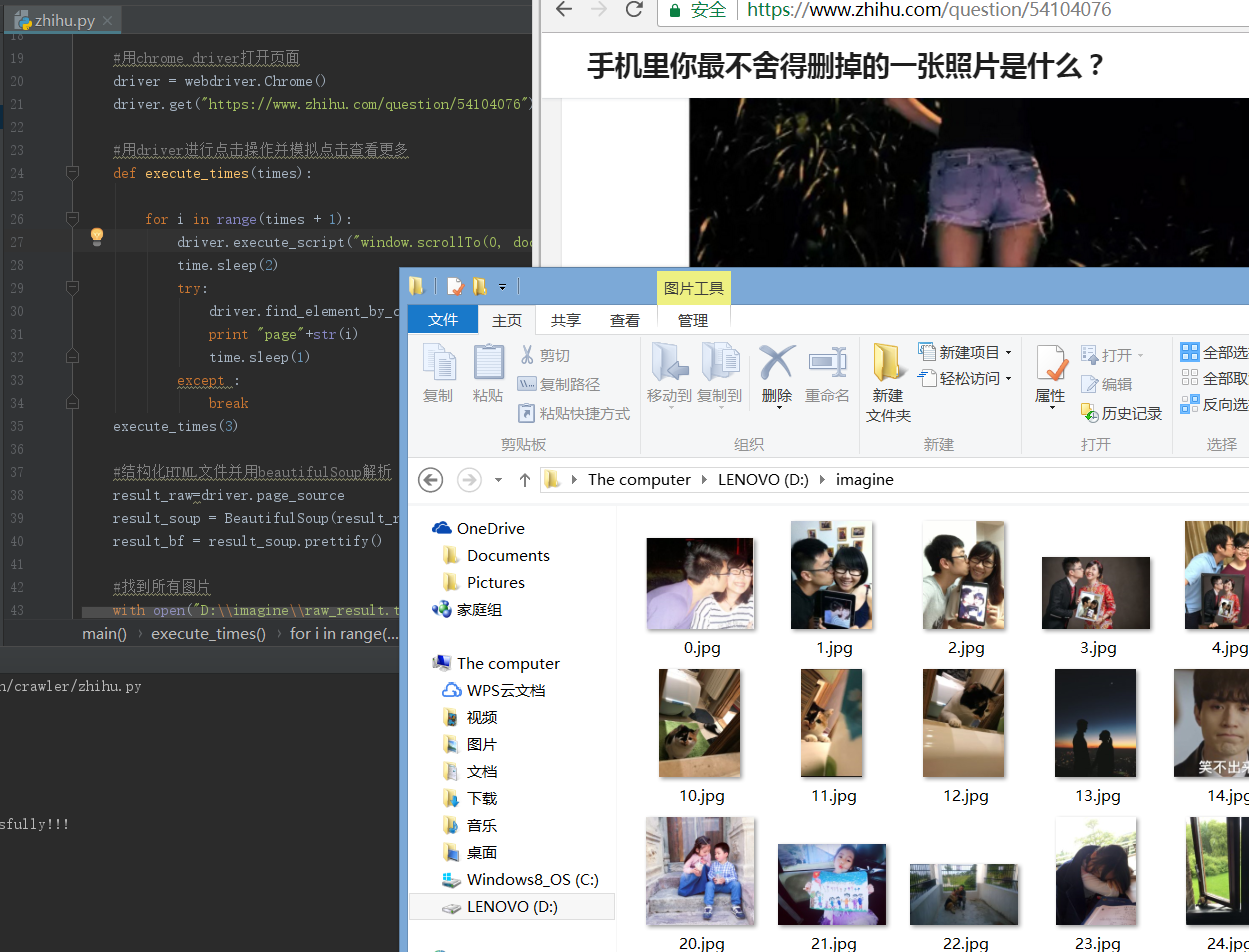
1 # -*- coding:utf-8 -*- 2 3 import sys 4 import time 5 import urllib 6 from bs4 import BeautifulSoup 7 from HTMLParser import HTMLParser 8 from selenium import webdriver 9 10 reload(sys) 11 sys.setdefaultencoding("utf-8") 12 13 def main(): 14 15 #用chrome driver打开页面 16 driver = webdriver.Chrome() 17 driver.get("https://www.zhihu.com/question/54104076") 18 19 #用driver进行点击操作并模拟点击查看更多 20 def execute_times(times): 21 22 for i in range(times + 1): 23 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") 24 time.sleep(2) 25 try: 26 driver.find_element_by_css_selector('button.QuestionMainAction').click() 27 print "page"+str(i) 28 time.sleep(1) 29 except : 30 break 31 execute_times(3) #打开三个页面 32 33 #结构化HTML文件并用beautifulSoup解析 34 result_raw=driver.page_source 35 result_soup = BeautifulSoup(result_raw, 'html.parser') 36 result_bf = result_soup.prettify() 37 38 #找到所有图片 39 with open("D:\imagine\raw_result.txt", 'w') as girls: 40 girls.write(result_bf) 41 girls.close() 42 print "Store raw data successfully!!!" 43 44 #找到所有<nonscript>标签并记录下来 45 with open("D:\imagine\noscript_meta.txt", 'w') as noscript_meta: 46 noscript_nodes = result_soup.find_all('noscript') 47 noscript_inner_all = "" 48 for noscript in noscript_nodes: 49 noscript_inner = noscript.get_text() 50 noscript_inner_all += noscript_inner + " " 51 52 h = HTMLParser() 53 noscript_all = h.unescape(noscript_inner_all) 54 noscript_meta.write(noscript_all) 55 noscript_meta.close() 56 print "Store noscript meta data successfully!!!" #成功找到图片 57 58 #开始下载图片 59 img_soup = BeautifulSoup(noscript_all, 'html.parser') 60 img_nodes = img_soup.find_all('img') 61 with open("D:\imagine\img_meta.txt", 'w') as img_meta: 62 count = 0 63 for img in img_nodes: 64 if img.get('src') is not None: 65 img_url = img.get('src') 66 67 line = str(count) + " " + img_url + " " 68 img_meta.write(line) 69 urllib.urlretrieve(img_url, "D:\imagine\" + str(count) + ".jpg") #下载图片 70 count += 1 71 72 img_meta.close() 73 print "Store meta data and images successfully!!!" #成功存储图片 74 75 if __name__ == '__main__': 76 main()
结果图: