
虚拟机环境准备
第一台伪分布式centos服务器:
配置步骤:
克隆虚拟机:
- 如果自己有以前的Linux虚拟机,可以直接克隆一台;如果没有,VMware+centos自行配置,百度即可
硬件地址文件修改:
- vim /etc/udev/rules.d/70-persistent-net.rules
- 内容修改:
# This file was automatically generated by the /lib/udev/write_net_rules # program, run by the persistent-net-generator.rules rules file. # # You can modify it, as long as you keep each rule on a single # line, and change only the value of the NAME= key. # PCI device 0x8086:0x100f (e1000) #SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:f0:4e:d2", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0" # PCI device 0x8086:0x100f (e1000) SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:7e:6c:8d", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
- 复制硬件地址(备用):00:0c:29:7e:6c:8d
设置静态IP地址:
- vim /etc/sysconfig/network-scripts/ifcfg-eth0
- 配置内容:
DEVICE="eth0" HWADDR="00:0c:29:7e:6c:8d" TYPE="Ethernet" UUID="3c53f20e-c5ca-4530-9c1c-0c9ebfa4a21b" ONBOOT="yes" NM_CONTROLLED="yes" BOOTPROTO="static" IPADDR="192.168.1.101" GATEWAY="192.168.1.2" DNS1="192.168.1.2"
硬件地址:与上一步的复制内容要一致
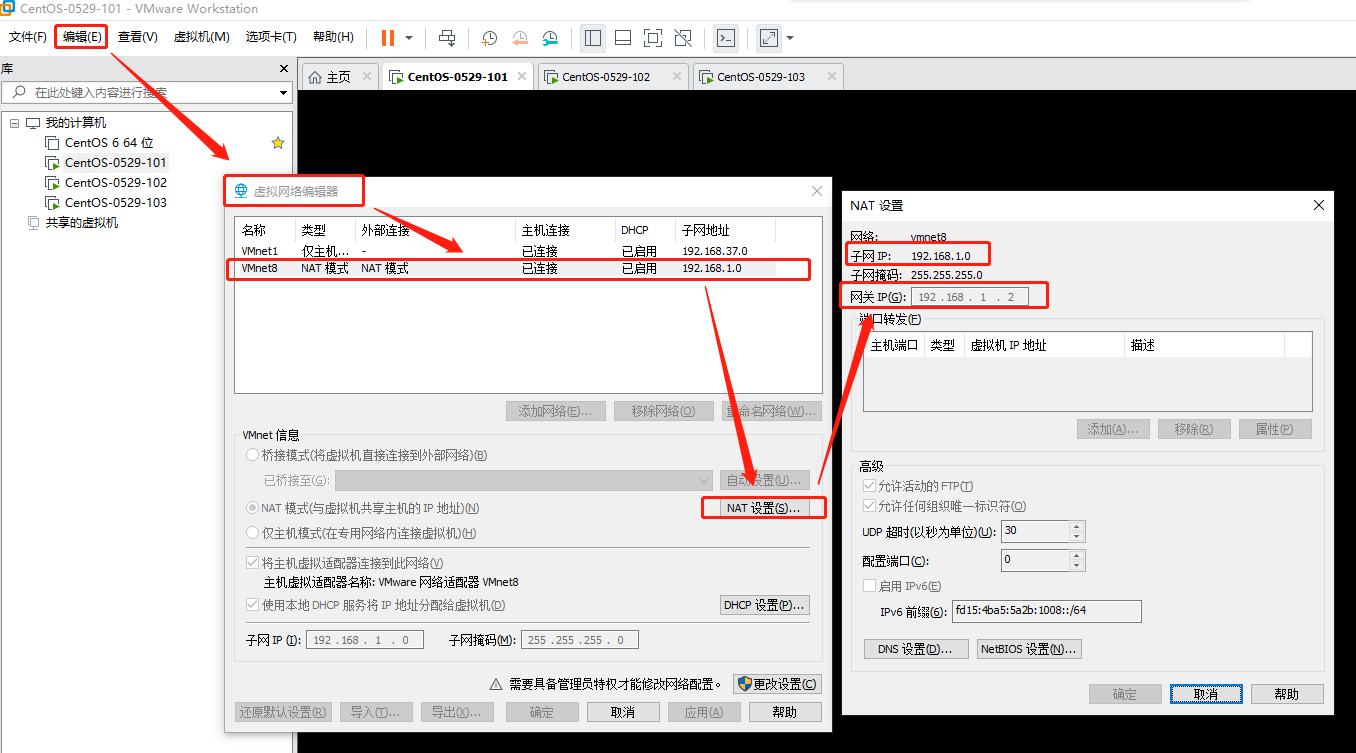
- 虚拟机VMware网络配置:
- 网段、网关 与 Linux配置 保持一致:
-
VMnet8配置:

- 网段、网关 与 Linux配置 保持一致:
设置HOSTNAME:
-
vim /etc/sysconfig/network
- 配置内容:
NETWORKING=yes #HOSTNAME=localhost.localdomain HOSTNAME=hadoop101
Linux配置hosts文件:
- vim /etc/hosts
- 添加内容:
192.168.1.100 hadoop100 192.168.1.101 hadoop101 192.168.1.102 hadoop102 192.168.1.103 hadoop103 192.168.1.104 hadoop104 192.168.1.105 hadoop105 192.168.1.106 hadoop106 192.168.1.107 hadoop107 192.168.1.108 hadoop108
Windows配置hosts文件:
- 路径: C:WindowsSystem32driversetchosts
- 添加内容:
192.168.1.100 hadoop100 192.168.1.101 hadoop101 192.168.1.102 hadoop102 192.168.1.103 hadoop103 192.168.1.104 hadoop104 192.168.1.105 hadoop105 192.168.1.106 hadoop106 192.168.1.107 hadoop107 192.168.1.108 hadoop108
- 注意:Windows下,不能直接修改hosts,解决:在桌面新建同名文件hosts,将etc下的hosts内容复制到新hosts,然后添加所需内容,最后直接覆盖etc下的hosts文件。
Linux永久关闭防火墙:
- 切换到root用户:su root
- chkconfig iptables off
创建用户:
- 新建自己的用户及用户组 useradd
给普通用户赋root权限:
- 切换到root账号: su root
- 查看所有用户信息: cat /etc/passwd
- 修改文件权限: chmod 777 /etc/sudoers
- vim /etc/sudoers
- 添加目标用户:
## Allow root to run any commands anywhere root ALL=(ALL) ALL hadoop ALL=(ALL) ALL
- 修改文件权限(还原为只读): chmod 0440 /etc/sudoers
reboot重启Linux服务器:
- 重启服务器: reboot
测试是否配置成功:
- Linux: ifconfig 检验静态ip是否正确
- Linux ping Windows:检验是否能够ping通
- Windows ping Linux:检验是否能够ping通
如果能够互相ping通,表示设置成功,进行下一步。
创建JDK && hadoop目录:
- 作用:存放JDK、hadoop软件安装包(tar包),存放软件安装目录
- 在/opt 目录下,创建module和software文件夹:
[hadoop@hadoop101 opt]$ sudo mkdir module [hadoop@hadoop101 opt]$ sudo mkdir software - 修改module和software的所有者:
[hadoop@hadoop101 opt]$ sudo chown hadoop:hadoop module/ software/
安装JDK:
- 卸载现有JDK:
- 查询是否安装JAVA软件:rpm -qa | grep java
- 卸载JDK:sudo rpm -e 软件包
- 查看JDK安装路径 && 彻底清理干净(rm -rf):which java
- 上传JDK至Linux服务器:
- 官网下载JDK:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html

- 通过xshell工具,上传JDK包至Linux的software目录下
- 官网下载JDK:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
- 解压JDK至module目录:tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
- 配置JDK环境变量:
- 获取JDK路径:
[hadoop@hadoop101 jdk1.8.0_281]$ pwd /opt/module/jdk1.8.0_281 - 打开/etc/profile文件:sudo vim /etc/profile
- 在文件末尾,添加JDK路径:
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin
- 保存退出::wq
- 使修改生效:source /etc/profile
- 获取JDK路径:
- 测试JDK是否安装成功:
[hadoop@hadoop101 jdk1.8.0_281]$ java -version java version "1.8.0_281" Java(TM) SE Runtime Environment (build 1.8.0_281-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.281-b09, mixed mode)
注意:如果java -version 不可用,尝试重启服务器reboot
安装hadoop:
-
hadoop下载地址:
- xshell上传hadoop tar包 至Linux的/opt/software目录下:参照【安装JDK】
- 解压hadoop安装包:参照【安装JDK】
- 添加环境变量:参照【安装JDK】
## /etc/profile 文件末尾添加如下内容:
##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin - 剩下步骤:参考【安装JDK】
hadoop目录结构:
- bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例
准备完全分布式集群环境(克隆3台Linux虚拟机):
克隆虚拟机:
- 直接克隆上述【伪分布式虚拟机Linux】
修改相关配置:
-
硬件地址文件修改
-
设置静态IP地址
-
设置HOSTNAME.
-
Linux配置hosts文件
-
Linux永久关闭防火墙
- 重启reboot
软件安装&环境变量配置
详见:上述伪分布式虚拟机配置步骤
集群分发脚本:
scp(secure copy)安全拷贝:
- scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
- 基本语法:
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
- 案例:
- 在机器hadoop101上,将hadoop101中的/opt/module目录下的软件拷贝到机器hadoop102上:
[hadoop@hadoop101 /]$ scp -r /opt/module root@hadoop102:/opt/module
- 在机器hadoop103上,将hadoop101中的/opt/module目录下的软件拷贝到机器hadoop103上:
[hadoop@hadoop103 opt]$sudo scp -r hadoop@hadoop101:/opt/module root@hadoop103:/opt/module - 在hadoop103上操作将hadoop101中/opt/module目录下的软件拷贝到hadoop104上:
[hadoop@hadoop103 opt]$ scp -r hadoop@hadoop101:/opt/module root@hadoop104:/opt/module
注意:要在hadoop102、hadoop103、hadoop104机器上,对拷贝过来的/opt/module目录,修改所属的用户组及用户(hadoop,可自定义)
- 在机器hadoop101上,将hadoop101中的/opt/module目录下的软件拷贝到机器hadoop102上:
- 由于,在【虚拟机环境准备】章节中,hadoop102、hadoop103、hadoop104机器是直接克隆的hadoop101,且hadoop101中已经安装了JDK与hadoop,故,不需要再用scp命令重新复制一遍,这里只是作为知识点记录下。
rsync远程同步工具:
- 定义:rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点
- rsync 与 scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去
- 基本语法:
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname 命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明:
- -r:递归
- -v:显示复制过程
- -l:拷贝符号链接
- 案例:
- 把hadoop101机器上的/opt/software目录同步到hadoop102服务器的root用户下的/opt/目录
[hadoop@hadoop101 opt]$ rsync -rvl /opt/software/ root@hadoop102:/opt/software
- 把hadoop101机器上的/opt/software目录同步到hadoop102服务器的root用户下的/opt/目录
xsync集群分发脚本:
- 需求:循环复制文件到所有节点的相同目录下
- 实现:
- 核心:利用 rsync 命令拷贝目标文件
- 编写脚本,需要的参数:【需要同步的文件名称】
- 步骤:
- 在自己的家目录下,创建bin目录,并在bin目录下创建文件xsync
[hadoop@hadoop102 module]$ cd [hadoop@hadoop102 ~]$ pwd /home/hadoop [hadoop@hadoop102 ~]$ mkdir bin [hadoop@hadoop102 ~]$ cd bin [hadoop@hadoop102 bin]$ pwd /home/hadoop/bin [hadoop@hadoop102 bin]$ touch xsync [hadoop@hadoop102 bin]$ ll total 0 -rw-rw-r-- 1 hadoop hadoop 0 Jan 29 14:57 xsync
- vim xsync:
#!/bin/bash
# 脚本需要的参数:目标文件的绝对路径 #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=103; host<105; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done - 修改脚本 xsync 具有执行权限:
chmod 777 xsync
- 调用脚本形式:xsync + 文件的绝对路径
- 注意:如果将xsync放到/home/hadoop/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下
- 在自己的家目录下,创建bin目录,并在bin目录下创建文件xsync
集群配置:
集群部署规划:
|
|
hadoop102 |
hadoop103 |
hadoop104 |
|
HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
配置集群:
以下配置,先在hadoop102机器上配置,然后利用xsync分发脚本,进行分发。
核心配置文件core-site.xml:
- 配置core-site.xml:
- [hadoop@hadoop102 hadoop-2.10.1]$ vim /opt/module/hadoop-2.10.1/etc/hadoop/core-site.xml
- 添加内容:
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
hdfs配置文件:
- 配置hadoop-env.sh:
- 获取JAVA_HOME的路径:
echo $JAVA_HOME - 编辑hadoop-env.sh:vim /opt/module/hadoop-2.10.1/etc/hadoop/hadoop-env.sh
- 添加内容:
# The java implementation to use. export JAVA_HOME=/opt/module/jdk1.8.0_281
- 获取JAVA_HOME的路径:
- 配置hdfs-site.xml:
- 编辑hdfs-site.xml:vim /opt/module/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
- 添加内容:
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property>
YARN配置文件:
- 配置 yarn-env.sh:参考【配置hadoop-env.sh】
- 配置yarn-site.xml:参考【配置hdfs-site.xml】
- 添加内容:
<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property>
- 添加内容:
配置MapReduce文件:
- 配置mapred-env.sh:参考【配置hadoop-env.sh】
- 配置 mapred-site.xml:参考【配置hdfs-site.xml】
- 添加内容:
<!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
- 添加内容:
在集群上分发配置好的hadoop配置文件:
[hadoop@hadoop102 hadoop-2.10.1]$ xsync /opt/module/hadoop-2.10.1/
查看文件分发情况:
[hadoop@hadoop103 ~]$ cat /opt/module/hadoop-2.10.1/etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.10.1/data/tmp</value> </property> </configuration>
SSH无密登录配置:
概述:配置ssh免密登录,是群起集群的前提。
配置 ssh:
免密登录原理:
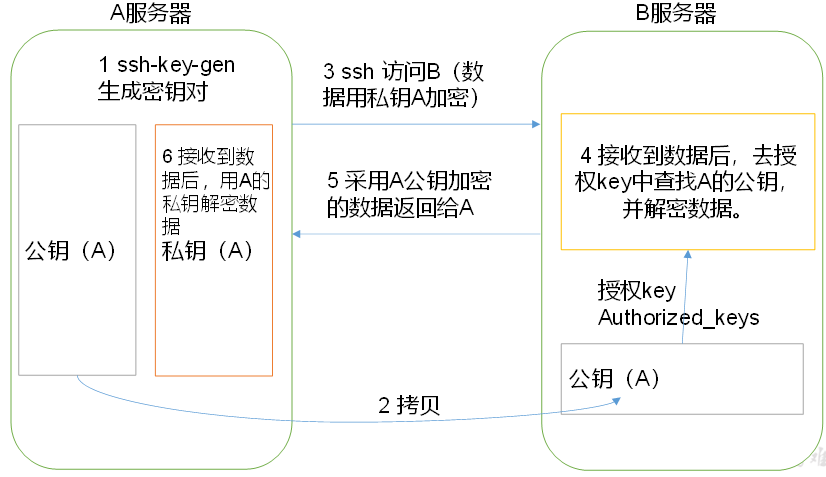
生成公钥和私钥:
- 家目录下,找到 .ssh 目录: [hadoop@hadoop102 ~]$ cd .ssh/
- 生成 公钥、私钥:
[hadoop@hadoop102 .ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: 73:5b:9e:4e:dd:b3:a6:38:81:4a:44:bf:54:95:6f:34 hadoop@hadoop102 The key's randomart image is: +--[ RSA 2048]----+ | ... | | . . . E | | . . . o .| | . o o | | . S + . . | | . = = o . | | . . . = ...| | . +. .o| | .o.o. | +-----------------+
敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到免密登录的目标机器上:
[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop102 [hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop103 [hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop104
Now try logging into the machine, with "ssh 'hadoop102'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
出现上述,表示成功,可以使用 ssh hadoop103 或者 ssh hadoop104,免密登录测试一下
注意:
- 还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104
- 还需要在hadoop103上采用hadoop账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上
.ssh文件夹(~/.ssh)的文件功能解释:
|
known_hosts |
记录ssh访问过计算机的公钥(public key) |
|
id_rsa |
生成的私钥 |
|
id_rsa.pub |
生成的公钥 |
|
authorized_keys |
存放授权过得无密登录服务器公钥 |
群起集群:
配置 slaves:
- 路径:[hadoop@hadoop102 hadoop-2.10.1]$ vim /opt/module/hadoop-2.10.1/etc/hadoop/slaves
- 添加内容:
hadoop102 hadoop103 hadoop104注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
- 同步所有节点的配置文件:[hadoop@hadoop102 hadoop-2.10.1]$ xsync /opt/module/hadoop-2.10.1/etc/hadoop/slaves
启动集群:
- 如果是首次启动,需要格式化 NameNode (注意:格式化前,一定要先停止上次启动的所有 namenode 和 DataNode 进程,然后删除 data 和 logs 数据)
[hadoop@hadoop102 hadoop-2.10.1]$ bin/hdfs namenode -format 21/01/30 02:04:58 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop102/192.168.1.102 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.10.1 STARTUP_MSG: java = 1.8.0_281 ************************************************************/ 21/01/30 02:04:58 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 。。。省略 21/01/30 02:05:00 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 21/01/30 02:05:00 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown. 21/01/30 02:05:00 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop102/192.168.1.102 ************************************************************/
- 启动HDFS:
[hadoop@hadoop102 hadoop-2.10.1]$ sbin/start-dfs.sh 21/01/30 03:20:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [hadoop102] hadoop102: starting namenode, logging to /opt/module/hadoop-2.10.1/logs/hadoop-hadoop-namenode-hadoop102.out hadoop104: starting datanode, logging to /opt/module/hadoop-2.10.1/logs/hadoop-hadoop-datanode-hadoop104.out hadoop102: starting datanode, logging to /opt/module/hadoop-2.10.1/logs/hadoop-hadoop-datanode-hadoop102.out hadoop103: starting datanode, logging to /opt/module/hadoop-2.10.1/logs/hadoop-hadoop-datanode-hadoop103.out Starting secondary namenodes [hadoop104] hadoop104: starting secondarynamenode, logging to /opt/module/hadoop-2.10.1/logs/hadoop-hadoop-secondarynamenode-hadoop104.out 21/01/30 03:21:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 启动 Yarn:
[hadoop@hadoop103 hadoop-2.10.1]$ sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to /opt/module/hadoop-2.10.1/logs/yarn-hadoop-resourcemanager-hadoop103.out The authenticity of host 'localhost (::1)' can't be established. RSA key fingerprint is f5:3e:86:5b:8a:b0:18:d7:d2:0b:54:8c:54:71:a8:3e. Are you sure you want to continue connecting (yes/no)? hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.10.1/logs/yarn-hadoop-nodemanager-hadoop103.out hadoop104: starting nodemanager, logging to /opt/module/hadoop-2.10.1/logs/yarn-hadoop-nodemanager-hadoop104.out hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.10.1/logs/yarn-hadoop-nodemanager-hadoop102.out
- 注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN
web端查看NameNode:
- 网址:http://192.168.1.102:50070/dfshealth.html#tab-overview
文件上传、下载测试:
- 上传:
[hadoop@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -put /opt/software/hadoop-2.7.2.tar.gz /user/atguigu/input - 下载:
[hadoop@hadoop102 hadoop-2.10.1]$ hadoop fs -get /user/gengyufei/output/jdk-8u281-linux-x64.tar.gz ~/
集群启停方式总结:
单节点启停:
- hdfs启停:
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
- YARN启停:
yarn-daemon.sh start / stop resourcemanager / nodemanager
集群启停(常用 && 前提: ssh配置):
- 整体启动/停止HDFS:
start-dfs.sh / stop-dfs.sh
- 整体启动/停止YARN:
start-yarn.sh / stop-yarn.sh
- 注意:前提需要 配置 /opt/module/hadoop-2.7.2/etc/hadoop/slaves
集群时间同步:
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。

配置步骤:
时间服务器配置(必须root用户)
(1)检查ntp是否安装
[root@hadoop102 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
[root@hadoop102 桌面]# vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@hadoop102 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@hadoop102 桌面]# service ntpd status
ntpd 已停
[root@hadoop102 桌面]# service ntpd start
正在启动 ntpd: [确定]
(5)设置ntpd服务开机启动
[root@hadoop102 桌面]# chkconfig ntpd on
2. 其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@hadoop103桌面]# crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意机器时间
[root@hadoop103桌面]# date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@hadoop103桌面]# date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。