这个系列主要是总结一些《改善python程序的91个建议》的学习笔记,希望可以对自己和读者有所帮助。本文是该系列第二部分,第一部分请见 Part1
21 多使用else 让程序变的更加pythonic
eg: try-except-else-finally
22 异常处理注意点
· 注意异常粒度,不推荐在try中放入过多的代码 最好保持异常粒度的一致性和合理性
· 异常捕获尽量具体指定,少用Except 使用单独的except 最好能够使用raise将异常抛出
· 注意异常捕获的顺序 (…)
· 使用更为友好的异常信息,遵守异常参数的规范
23 避免finally中可能发生的陷阱
finally中产生新的异常或者执行了return or break 那么临时报错的异常就会丢失,导致异常屏蔽
24 深入理解None,正确判断对象是否为空
python 以下数据会当做空来处理:
· 常量None 常量False
· 任何形式的数值类型0 eg:0,0L ,0.0,0j
· 空的序列字典,如”(),[],{}
· 当用户定义的类中定义了nonzero()和len()方法,并且该方法返回bool值false或者整数0
常量None的特殊性体现在它 既不是0orFalse,它就是一个空值对象,数据类型为NoneType,遵循单例模式
None与任何其他非None的对象比较结果为False None !={}
一般判断空列表 直接 if list or if len(list)
25 连接字符串应优先使用join而不是+ —-> 字符串规模比较大的时候
26 python 格式化字符串尽量使用 str.format 而不是%
eg:
‘xxxx{0}xxxx{1}’.format(n1,n2)
最直接的理由:% 最终会被.format 方式代替
27 区别对待可变对象和不可变对象
· 不可变对象: 数字,字符串,元组
· 可变对象 : 字典,列表,字节数
· 注意:列表的切片操作相当于浅拷贝 —>list1=[1,2,3] list2=list1[:] id(list1)!=id(list2)
28 使用列表解析 like [x for x in range(10)]
· 代码更简洁
· 效率更高 但是大数据不是最佳的选择,过多的内存消耗可能会导致memoryError
29 警惕默认参数潜在的问题
def xxx(xx,a=[]) 不要使用列表等可变类型 def实际是可执行语句 默认参数也会被计算
===>应修改为 def xxx(xx,a=None)
30 慎用变长参数
· 使用过于灵活,可能破坏程序的健壮性
· 如果一个函数的参数列表很长,虽然可以通过使用*args 和 **kwargs 来简化函数的定义
但通常这意味着这个函数可以有更好的实现方式,应该被重构,用一个序列来保存需要传递的参数
适合场景是: 装饰器 读取配置文件
31 深入理解str()和repr()的区别
· str()主要面向用户,目的是可读性,返回可读性强的字符串类型
repr()面向的是Python解释器or 开发人员,返回值表示python解释器内部的含义
· 在解释器中直接输入a时默认调用repr()函数,而print a 则 调用的是str()
· 一般来说类中毒定义了__repr__()方法,而__str__()则为可选,没有__str__(),则默认会使用__repr__()
32 分清staticmethod和classmethod的适用场景
· 静态方法:实现功能不和实例相关也不和类相关的独立方法,如一些字符验证等,定义在类中能有效将代码组织起来,从而使相关代码的垂直距离更近,提高代码的可维护性;当然,如果有一组独立的方法,将其定义在一个模块中,通过模块来访问这些方法也是不错的选择
· 类方法: 减少子类的代码重写, 降低代码的冗余
33 字符串的基本用法
· 多行字符串使用下面的方式
s = ( 'aaaaa' 'bbbb' 'ccccc' )
· 3对双引号会把换行符和前导空格当做字符串的一部分
· str.startswith和endswith中匹配参数可以使用元组,有一个匹配上就返回T
· 判断字符串包含子串的判断推荐使用 in 和 not in
· ''.split() ==> [] ''.split(' ') ==> ['']
34 按需选择sort()或者sorted()
· sorted()会保留原有列表生成新的列表
· sorted功能非常强大,而sort只能排一般的列表
35 使用Counter 进行计数统计
from collections import Counter some_data = ['a','2',2,4,5,'2','b',4,7,'a',5,'d','a','z'] print Counter(some_data) >>>Counter({'a': 3, '2': 2, 4: 2, 5: 2, 2: 1, 'b': 1, 7: 1, 'd': 1, 'z': 1})
· Counter类属于字典类的子类,是一个容器对象,主要用来统计散列对象。
# 取值 xx = Counter(some_data) print xx.['a']
36 单例模式
保证系统中一个类只有一个实例而且该实例易于被外界访问,从而方便对实例个数的控制并节约系统资源
class Test(object): is_instance = None is_first = True def __new__(cls, *args, **kwargs): if cls.is_instance == None: cls.is_instance = object.__new__(cls) return cls.is_instance def __init__(self, name): if Test.is_first: self.name = name Test.is_first = False test1 = Test('lf1') print(id(test1)) # 2136967041656 print(test1.name) # lf1 test2 = Test('lf2') print(id(test2)) # 2136967041656 print(test2.name) # lf1
37 利用cProfile 定位性能瓶颈
程序运行慢的原因有很多,但真正的原因往往是一两段设计并不那么良好的不起眼的程序。程序性能影响往往符合8/2法则,即20%的代码运行时间占用了80%的总运行时间(实际上,比例要夸张得多,通常是几十行代码占用了95%以上的运行时间)。
profile是python的标准库,可以统计程序里每一函数的运行时间,并提供了多样的报表,cprofile则是它的C实现版本,剖析过程本身需要消耗的资源更少。
## test_cprofile.py import time def foo(): sum = 0 for i in range(100): sum += i time.sleep(.5) return sum if __name__ == "__main__": foo()
现在使用profile分析这个程序
if __name__ =="__main__": import cProfile cProfile.run("foo()")
输出如下:
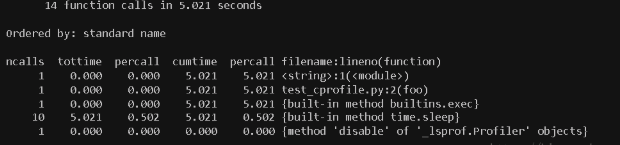
第二种方式:python -m cProfile test_cprofile.py
· cProfile 的统计结果以及各项意义
| 统计项 | 意义 |
|---|---|
| ncalls | 函数的调用次数 |
| tottime | 函数总计运行时间,不含调用的函数运行时间 |
| percall | 函数运行一次的平均时间,等于tottime/ncalls |
| cumtime | 函数总计运行时间,含调用的函数运行时间 |
| percall | 函数运行一次的平均时间,等于cumtime/ncalls |
| filename:lineno(function) | 函数所在的文件名,函数的行号,函数名 |
将cProfile的输出保存到文件,并以各种形式来查看结果.
1)使用cProfile.run()函数再提供一个实参,就是保存输出的文件名;同样,在命令行参数里,多一个参数,用来保存cProfile的输出
2)通过pstats模块的另一个类Stats来解决.
# ....略 if __name__ == "__main__": import cProfile cProfile.run("foo()", "prof.txt") import pstats p = pstats.Stats("prof.txt") # sort_stats(key,[...]) 以key排序 print_stats()输出结果 p.sort_stats("time").print_stats()
sort_stats的key
| 参数 | 参数的意义 |
|---|---|
| ncalls | 被调用次数 |
| cumulative | 函数运行的总时间 |
| file | 文件名 |
| module | 模块名 |
| pcalls | 简单调用统计(兼容旧版,未统计递归调用) |
| line | 行号 |
| name | 函数名 |
| nfl | Name,file,line |
| stdname | 标准函数名 |
| time | 函数内部运行时间(不计调用子函数的时间) |
38 掌握循环优化的基本技巧
· 减少循环内部的计算
# 1 for i in range(iter): d = math.sqrt(y) j += i*d # 2 比第一种快 40%~60% d = math.sqrt(y) for i in range(iter): j += i*d
· 将显式循环改为隐式循环
"""求等差数列1,2,3,...n的和""" # 1 sum = 0 n = 10 for i in range(n+1): sum = sum + i print(sum) # 2 直接用数学知识 n*(n+1)/2 负面影响就是牺牲了代码的可读性 需添加清晰和恰当的注释是非常必要的 n = 10 print(n*(n+1)/2)
· 在循环中尽量引用局部变量.在python命名空间中局部变量优先搜索,因此局部变量的查询会比全局变量要快
# 1 x = [10,34,56,78] def f(x): for i in range(len(x)): x[i] = math.sin(x[i]) return x # 2 性能提高10%~15% def g(x): loc_sin = math.sin for i in range(len(x)): x[i] = loc_sin(x[i]) return x
· 关注内层嵌套循环,尽量将内层循环的计算往上层移,减少内层的计算
# 1 for i in range(len(v1)): for j in range(len(v2)): x = v1p[i]+ v2[j] # 2 for i in range(len(v1)): vli = v1[i] for j in range(len(v2)): x = vli + v2[j]
参考:
《改善python程序的91个建议》
https://blog.csdn.net/qq_31603575/article/details/80177153
https://www.cnblogs.com/cotyb/p/5452602.html
https://www.cnblogs.com/cotyb/tag/pythonic/
https://medium.freecodecamp.org/an-a-z-of-useful-python-tricks-b467524ee747