一、字符串
是一组由字符组成的序列,每一个字符都是字符串中的一个元素。
注意:不存在字符str,最小单位为字符串
字符串是不可修改类型(基本数据类型)
1. 字符串的创建-----单引号、双引号、三引号
- 单引号和双引号交替使用可以到输出双引号的和单引号的作用
- 三引号----自带换行
- 续行符"\"可以换行
- 空字符串 strnull = '
2. 字符转义----(可以转义的字符由' " \)
在需要转义的字符前面添加"\",对特殊字符进行转义
# 换行\n, \t, \r----换行,制表符,回车
b = 'nnnnn\n'
3. 字符串的操作(运算符、索引、切片)
(1) 运算符 ---- + * in is < >
|
+ |
合并的字符串(新创建字符串) |
print('a'+'b')
|
* |
重复 |
|
in/not in |
值判断 |
print('a' in 'asdasda')
|
is/is not |
对象判断 |
eg:
a = 'asd'
b = 'asd'
print(a is b)
|
< > <= >= |
比较运算 |
print('a' < 'b') # 比较ASCII码
*****
print('absdc' < 'abd') # 按照元素顺序,依次比较
(2) 索引----获取单个元素
格式: 变量名[index]
- index的第一个元素是0,最后一个元素是-1
- index 为正数从左往右,负数从右往左
- index范围(-len(), len()-1)
- 字符串长度可以通过len()获得
(3) 切片----获得字符串中的多个元素
格式: 变量名[start:end:step],三个参数都可以省略
注意start方向问题
注意start对应字符输出、end对应字符不输出
|
[:] |
提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串 |
|
[start:] |
从start 提取到结尾 |
|
[:end] |
从开头提取到end - 1 |
|
[start:end] |
从start 提取到end - 1 |
|
[start:end:step] |
从start 提取到end - 1,每step 个字符提取一个左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1 |
Example:
a[:] # 整切片
a[0:]
a[-4:] # 切片索引可以越界
a[:4]
a[-5:-1]
a[-1:-5:-1]
a[::-1] # 颠倒
局部切片新创建对象,整体切片不新建对象
print(a is a[:]) ------ True
print(id(a), id(a[:]), id(a[1:4]) )
Practice:
使用切片工具,截取data中的年月日,data = '2018-06-28'
4. 字符串的相关方法
定义的字符串,相当于创建的一个str对象
s = 'fssdfgsdfg'
print(tpye(s))
-
count()统计一个字符在字符串中的数量
x 待统计自字符串
start 起始位置
end 结束为止默认从头到尾
# 几乎在所有包含start和end的地方都是包含start,不包含end
-
index() 返回查找字串的位置,默认输出第一次子串出现为止
当查不到查找字串时报错
index(sub, start, end)
sub 为查找字串
- find() 如果找不到,返回 -1
-
join() 将序列中的每一个元素,使用字符串拼接起来
# 填充元素在前,被填充序列在括号中
s = '123'
b = '-'
print(b.join(s))
-
replace(old, new, count)
old 待替换字符串
new 要替换的字符串
count 不写全部替换,指定后从左往右替换,可以超出实际次数
# replace不修改原数据,而是新创建字符串存储
-
strip(chr) 剪切,按照传入的参数,去掉两端的对应字符串
chr 默认空格
剪切时按照剪切字符的所有单子符,从两端一直剪切到不存在符合字符为止
s = ' adasdferasda '
print(s.strip('ad'))
# 左剪切 lstrip()
# 右剪切 rstrip()
-
split(sep, max) 切割:被切割的字符会去掉
sep 切割字符
max 最大切割次数
# 默认按照空格切割,返回值为列表类型
s = ' adasdferasda '
print(s.split('er'))
对字符串的所有操作都不会原地去做(修改字符串),而是新建。
- upper() / lower() 变成大写或小写
- capitalize() 首字母大写
-
isnumeric() 判断字符串是否完全是数字[汉字数字返回True]
- 数字包括罗马数字、中文数字、Unicode数字、byte数字(单字节)、全角数字(双字节)
isdigit() 判断字符串是否完全是数字[汉字数字返回Flase]
isdecimal()
- isalpha() 判断是否完全都是字符[中文/英文]
- isidentifier() 判断字符串是否是合法标识符[变量名[字符、数字、下划线]、]
-
isupper() 判断是字符串内字母否完全是大写
islower() 判断是字符串内字母否完全是小写
isspace() 判断是否完全是空格
-
center(width, fillchar) 向两端填充字符,先左后右
width 填充完毕后的宽度
fillchar 填充字符
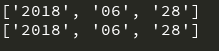
二、字节
字节是一系列单字节的组合,每一个字节都是[0, 255](无符号)范围内组成。
单字节:一个字节8个数据位
字节也不支持修改(类似字符串、简单变量)
1. 字节的创建
b = b'abc'
c = b'打' --------- 汉字报错,因为汉字不能以字节形式报错
8个数据位,最多存储256不同内容
2. 字节的操作 运算符、索引、切片
(1) 运算符 + - * / is in >
eg:
print(b'abc' in b'abcsd')
print(b'abc' >= b'abcsd')
(2) 索引 索引显示ASCII码
eg:
print(b'b')
(3) 切片 切片显示字节
三、格式化 format:
方便打印输出的时候显示
# 将数字格式化成字符串
方法1: %
s% == str()
print('jj %s' % 1)
print('jj %s %s' % (1, 3))
方法2:format
print("'jj', 'java', {}, {}".format(1,2,4))
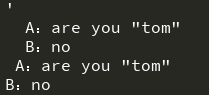
# 1.输出如下内容:分别使用双引号,和三引号
# A:are you "tom"
# B:no
a = ''''
A:are you "tom"
B:no
'''
b = "A:are you \"tom\"\n" \
"B:no"
print(a , b)
print('第二题=========================\n')
# 2.定义两个字符串,a="hello" b="hello",令c=a,
# 思考:是否能对a中的h进行修改
# 输出abc三个变量的值
# 使用is和==判断abc之间的关系,并画出内存图
m = 'hello'
n = 'hello'
t = m
idx = m.index('h')
chang = input('To change \'h\' as what:\n')
m_new = chang + m[idx:]
print('m修改后的结果是:',m_new)
############################
# def namestr(obj, namespace = globals()):
# return [name for name in namespace if namespace[name] is obj]
# import inspect
# import re
#
# def get_variable_name(variable):
# loc = locals()#把locals()方法移到函数内
# for key in loc:
# if loc[key] == variable:
# return loc
###############################
def judge(a, b):
if a is b:
return '{}和{}同一对象'.format(a, b)
elif a == b:
return '{}和{}是同一值'.format(a, b)
else:
return '{}和{}没半毛钱关系'.format(a, b)
print(judge(m, n))
print(judge(m, t))
print(judge(n, t))
print(judge(m_new, t))

print('第三题=========================\n')
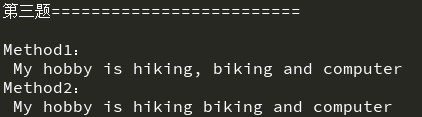
# 3.分别输入3个爱好,打印出来"我的爱好是**、**、**" ,
# 使用格式化输出
hobby1 = 'hiking'
hobby2 = 'biking'
hobby3 = 'computer'
print('Method1:\n My hobby is {}, {} and {}'\
.format(hobby1, hobby2, hobby3))
print('Method2:\n My hobby is %s %s and %s' % (hobby1, hobby2, hobby3))
print('第四题=========================\n')
# 4.这是一个地址,http://news.gzcc.cn/html/2017/xiaoyuanxinwen_1027/8443.html
# 其中1027/8443是新闻编号,想办法获得新闻编号。至少两种方法。
website = 'http://news.gzcc.cn/html/2017/xiaoyuanxinwen_1027/8443.html'
# 第一种方案:split
cut1 = website.split('_')
cut1 = cut1[1].split('.')
print('采用split方法:', cut1[0])
# 第二种方案,切片(已知数字位数)
cut_back = website[-13: -5]
print('倒数位置固定的话,采用位数:', cut1[0])
# 第三种方案,切片(倒数第一个反斜杠)
lens = len(website)
website_back = website[::-1]
slash = website_back.index('/')
result = website_back[slash-4 : slash+4]
result = result[::-1]
print('采用寻找倒数第一个'/'方法:', cut1[0])
print('第五题=========================\n')
# 5.做如下练习:
# # 1.输入一种水果,如葡萄
# # 2.打印类似"吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮"的效果
# # 3.使用切片,切出自己输入的水果
# # 4.使用strip,剪切到自己输入的水果
# # 5.统计打印的的文本中,水果出现的次数
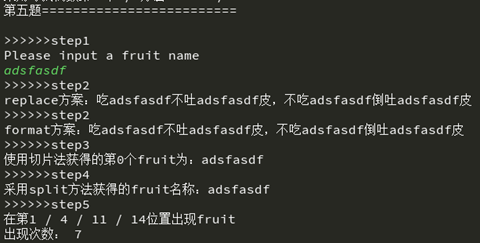
fruit = input('>>>>>>step1\nPlease input a fruit name\n')
# 替换
lyric = '吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮'
lyric_new = lyric.replace('葡萄', fruit)
print('>>>>>>step2\nreplace方案:'+ lyric_new)
# 格式化输出
print('>>>>>>step2\nformat方案:'+'吃{}不吐{}皮,不吃{}倒吐{}皮'.format(fruit, fruit, fruit, fruit))
# step3,切出水果
# 模拟索引index()函数,寻找第一个相符点
def my_index(lyric_new, fruit):
index_list = []
count= 0
# 遍历句子,判断和水果名的比较
for stri in range(len(lyric_new)-len(fruit)+1):
for dexi in range(0, len(fruit)):
# print(stri, lyric_new[stri + dexi], fruit[dexi],lyric_new[stri + dexi] == fruit[dexi])
if lyric_new[stri + dexi] == fruit[dexi]:
count += 1
index_list.append(stri)
# 计算出现次数
# print(count, len(fruit))
count_total = count // len(fruit)
# 修改出现位置列表
index_list = index_list[::len(fruit)]
# 切片获得随机一个fruit
import random
dex_redom = random.randint(0, len(index_list)-1)
fruit_cut = lyric_new[index_list[dex_redom]:index_list[dex_redom] + len(fruit)]
print('>>>>>>step3\n使用切片法获得的第{}个fruit为:{}'.format(dex_redom,fruit_cut))
# 使用strip获得fruit名称
lyric_new_split = lyric_new.split('不吐', 1)
lyric_new_split = lyric_new_split[0].strip('吃')
print('>>>>>>step4\n采用split方法获得的fruit名称:' + lyric_new_split)
#输出
print('>>>>>>step5\n在第{} / {} / {} / {}位置出现fruit'.format(index_list[0],\
index_list[1], index_list[2], index_list[3]))
print('出现次数: {}'.format(len(index_list)))
return index_list, count_total, fruit_cut
(my_index(lyric_new, fruit))
# print('寻找+切片,得出结果:'+my_index(lyric_new, fruit)[1])