碰到朋友一个问题,基于Oracle环境,有点复杂,直接看代码。
我的测试环境是sql server 2014
create table test101( [门店] int ,[缴费大类] int ,[支付方式] int ,[付款] int, [手续费] int ) insert into test101 values (1,0,1,10,2), (1,0,2,10,2), (1,0,3,10,2), (1,0,4,10,2), (1,1,1,10,2), (1,1,2,10,2), (1,1,3,10,2), (1,1,4,10,2), (1,2,1,10,2), (1,2,2,10,2), (1,2,3,10,2), (1,2,4,10,2), (1,3,1,10,2), (1,3,2,10,2), (1,3,3,10,2), (1,3,4,10,2)
数据如下:
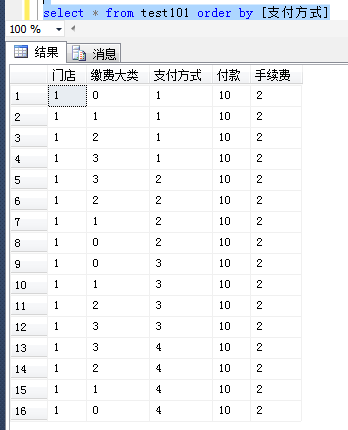
然后是要求出挣得钱和缴多少税。
消费大类:3为退款,0~2为入账大类。
现在要计算每一种支付方式,挣了多少钱,缴了多少税。
逻辑算法:
挣钱:当支付方式为1时:累加支付方式0~2的付款数,减去消费大类为3(退款)的付款数,即为支付方式1所挣的钱。
手续费:当支付方式为1时:累加支付方式0~2的手续费,减去消费大类为3(退款)的手续费,即为支付方式1所需要承担的手续费。

挣钱:这里计算一下是10+10+10-10;
手续费:这里计算一下是2+2+2-2;
以此类推,算出每个门店下所有支付方式对应挣得钱和所需手续费。
方法:1(我朋友的方法,对此我是无比佩服),在实际业务中,肯定会有多条
[门店],[支付方式],[缴费大类]相同的,而付款和手续费不同的数据,所以实际业务中应当用sum代替max,这里只是测试就用Max了。
select [门店],[支付方式], max(case when [缴费大类]=0 then isnull([付款],0) else 0 end) + max(case when [缴费大类]=1 then isnull([付款],0) else 0 end) + max(case when [缴费大类]=2 then isnull([付款],0) else 0 end) - max(case when [缴费大类]=3 then isnull([付款],0) else 0 end) as [付款], max(case when [缴费大类]=0 then isnull([手续费],0) else 0 end) + max(case when [缴费大类]=1 then isnull([手续费],0) else 0 end) + max(case when [缴费大类]=2 then isnull([手续费],0) else 0 end) - max(case when [缴费大类]=3 then isnull([手续费],0) else 0 end) as [付款] from test101 t group by [门店],[支付方式] order by [门店]
看结果:(因为值都是一样,所以每个支付方式都是一样)

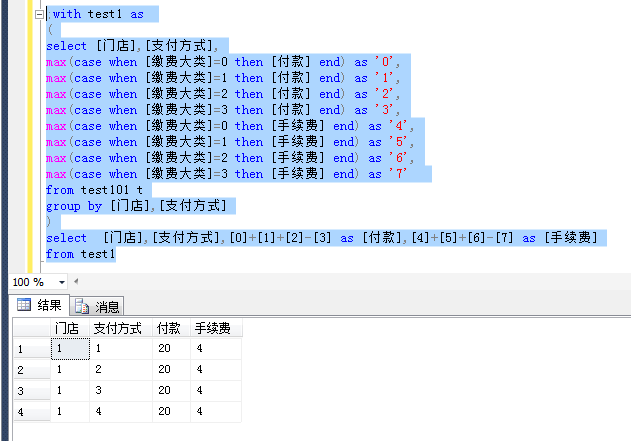
(1)原理剖析:通过门店与支付方式为分组,对支付方式进行行转列,并带着对应的付款数与手续费
select [门店],[支付方式], max(case when [缴费大类]=0 then [付款] end) as '0', max(case when [缴费大类]=1 then [付款] end) as '1', max(case when [缴费大类]=2 then [付款] end) as '2', max(case when [缴费大类]=3 then [付款] end) as '3', max(case when [缴费大类]=0 then [手续费] end) as '4', max(case when [缴费大类]=1 then [手续费] end) as '5', max(case when [缴费大类]=2 then [手续费] end) as '6', max(case when [缴费大类]=3 then [手续费] end) as '7' from test101 t group by [门店],[支付方式] order by [门店]
可是这不就是sum嘛,把其转成负一就好

SUM(付款 * case when [缴费大类] = '3' then -1 else 1 end ) as 付款,
SUM(手续费 * case when [缴费大类] = '3' then -1 else 1 end ) as 手续费
FROM 表 group by 门店,支付方式
(2)由此可见,这里我们类似于下面这类形式的
max(case when [缴费大类]=0 then [付款] end)
其实是获取,每个门店、每个消费方式对应缴费大类的值。
所以,我们可以直接通过下面这类值,来获取当个【门店】下当个【支付方式】对应【缴费大类】下的【付款】与【手续费】
max(case when [缴费大类]=0 then isnull([付款],0) else 0 end) + max(case when [缴费大类]=1 then isnull([付款],0) else 0 end) + max(case when [缴费大类]=2 then isnull([付款],0) else 0 end) - max(case when [缴费大类]=3 then isnull([付款],0) else 0 end)
然后用此表达式就实现了我们的逻辑算法。
挣钱:当支付方式为1时:累加支付方式0~2的付款数,减去消费大类为3(退款)的付款数,即为支付方式1所挣的钱。
手续费:当支付方式为1时:累加支付方式0~2的手续费,减去消费大类为3(退款)的手续费,即为支付方式1所需要承担的手续费。
当然,也可以去用我们传统的方法:
(3)这里问题也来了,如果支付方式过多,1个门店会有很多行,这不利于我们查看,这里还需要再行转列一下,把支付方式变成列,付款和手续费变成对应转换后的列值
;with test1 as ( select [门店],[支付方式], max(case when [缴费大类]=0 then [付款] end) as '0', max(case when [缴费大类]=1 then [付款] end) as '1', max(case when [缴费大类]=2 then [付款] end) as '2', max(case when [缴费大类]=3 then [付款] end) as '3', max(case when [缴费大类]=0 then [手续费] end) as '4', max(case when [缴费大类]=1 then [手续费] end) as '5', max(case when [缴费大类]=2 then [手续费] end) as '6', max(case when [缴费大类]=3 then [手续费] end) as '7' from test101 t group by [门店],[支付方式] ) , test2 as ( select [门店],[支付方式],[0]+[1]+[2]-[3] as [付款],[4]+[5]+[6]-[7] as [手续费] from test1 ), test3 as ( select [门店],[1],[2],[3],[4] , '付款' as [tpye] from (select [门店],[支付方式],[付款] from test2) t pivot ( max([付款]) for [支付方式] in ([1] ,[2],[3],[4]) ) t1 union all select [门店],[1],[2],[3],[4],'手续费' as [tpye] from (select [门店],[支付方式],[手续费] from test2) t pivot ( max([手续费]) for [支付方式] in ([1],[2],[3],[4]) ) t1 ) select * from test3
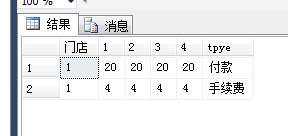
test2数据:就是(2)中的图
test3查询完结果如图:
很明显,我这个方法效率很低,要多次查询表,会造成太多额外的开销。如果有多个需要这样展示的选项,那开销将大一点,除非数据量特别小!不过,cte会把数据缓存在内存中,逻辑读还是比较快的,在数据量比较小的情况下不影响!如果数据量比较大,可以用全局临时表(避免需要重复创建)+给其建立索引,来优化,这样就会快一些了。
而,我的朋友是这么写的
with test1 as (select [门店],[支付方式], max(case when [缴费大类]=0 then isnull([付款],0) else 0 end) + max(case when [缴费大类]=1 then isnull([付款],0) else 0 end) + max(case when [缴费大类]=2 then isnull([付款],0) else 0 end) - max(case when [缴费大类]=3 then isnull([付款],0) else 0 end) as [付款], max(case when [缴费大类]=0 then isnull([手续费],0) else 0 end) + max(case when [缴费大类]=1 then isnull([手续费],0) else 0 end) + max(case when [缴费大类]=2 then isnull([手续费],0) else 0 end) - max(case when [缴费大类]=3 then isnull([手续费],0) else 0 end) as [手续费] from test101 t group by [门店],[支付方式] ) select test1.[门店] , max(case when test1.[支付方式] = '1' then [付款] end ) as [付款_1], max(case when test1.[支付方式] = '1' then [手续费] end ) as [手续费_1], max(case when test1.[支付方式] = '2' then [付款] end ) as [付款_2], max(case when test1.[支付方式] = '2' then [手续费] end ) as [手续费_2], max(case when test1.[支付方式] = '3' then [付款] end ) as [付款_3], max(case when test1.[支付方式] = '3' then [手续费] end ) as [手续费_3] , max(case when test1.[支付方式] = '4' then [付款] end ) as [付款_4], max(case when test1.[支付方式] = '4' then [手续费] end ) as [手续费_4] from test1 group by test1.[门店]
这里的case when 都可以用decode来代替,显得代码少一点点。
结果:高下立判,他的方法高明的多,但这种情况,支付方式多了,或者显示的数据多了(这里只有付款数和手续费),那列的字段数量也将是灾难级的。看个人习惯喜欢看哪种方式展示数据。

或许是我还不太会用pivot,总觉得今天case when给了我很大震撼。。以前也不知道还能这么用,学习了,感谢小余同学的提问,互相学习共勉。
今天心里还在念叨这个事,于是又想了很多,去请教了一个人,终于用pivot unoivot解决了
;with t2 as ( SELECT 门店,支付方式, SUM(付款 * case when [缴费大类] = '3' then -1 else 1 end ) as 付款, SUM(手续费 * case when [缴费大类] = '3' then -1 else 1 end ) as 手续费 FROM test101 group by 门店,支付方式 ) ----***第二步将加工过的数据 行转列 select * from
( ---****先将第一步汇总的数据源列转行 select * from (SELECT [门店] ,[支付方式] ,[付款] ,[手续费] from t2 ) p UNPIVOT ( [Money] FOR PayClass IN (付款, 手续费) ) m
) p ----***列转行结束 PIVOT ( SUM([Money]) FOR [支付方式] IN ( [1],[2],[3],[4] ) ) as pvt ---***行专列结束
结果如下:

多行转列(2):~
另一种模式,我想这样转换
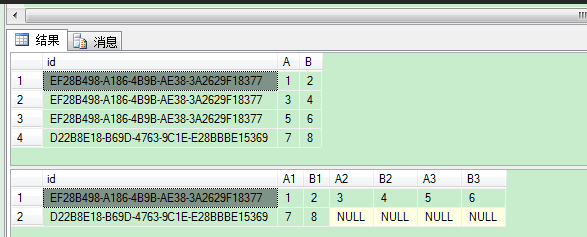
CREATE TABLE #T ( id UNIQUEIDENTIFIER, A INT, B INT ) INSERT INTO #T( id, A, B)
VALUES('EF28B498-A186-4B9B-AE38-3A2629F18377',1,2),
('EF28B498-A186-4B9B-AE38-3A2629F18377',3,4),
('EF28B498-A186-4B9B-AE38-3A2629F18377',5,6),
('D22B8E18-B69D-4763-9C1E-E28BBBE15369',7,8) SELECT * FROM #T SELECT id, SUM(CASE WHEN x=1 THEN A ELSE NULL END) AS A1, SUM(CASE WHEN x=1 THEN B ELSE NULL END) AS B1, SUM(CASE WHEN x=2 THEN A ELSE NULL END) AS A2, SUM(CASE WHEN x=2 THEN B ELSE NULL END) AS B2, SUM(CASE WHEN x=3 THEN A ELSE NULL END) AS A3, SUM(CASE WHEN x=3 THEN B ELSE NULL END) AS B3 FROM ( SELECT *,ROW_NUMBER() OVER(PARTITION BY id ORDER BY id) AS x FROM #T ) A GROUP BY id
这样是固定的,其实是有问题的(比如我的X在一个大范围内比如1~10000都有可能,不能1+1一步一步判断吧),那么如果我要动态呢
DECLARE @M INT SELECT @M=MAX(A) FROM ( SELECT COUNT(*) A FROM #T GROUP BY id )A DECLARE @W VARCHAR(max)='' DECLARE @SQL VARCHAR(max)='' SELECT @W=@W+',SUM(CASE WHEN x='+CONVERT(VARCHAR(10),number)+' THEN A ELSE NULL END) AS A1'+',SUM(CASE WHEN x='+CONVERT(VARCHAR(10),number)+' THEN B ELSE NULL END) AS B1' FROM master..spt_values WHERE type='P' AND number>0 AND number<=@M SET @SQL='SELECT id'+@W+' FROM ( SELECT *,ROW_NUMBER() OVER(PARTITION BY id ORDER BY id) AS x FROM #T ) A GROUP BY id ' EXEC (@SQL)

感谢sql server技术群--东莞-小小 提供的代码 以及其支持与帮助。
善用笛卡尔积
需求:

declare @temp table(a varchar(50), b varchar(16), c int); insert into @temp values ('2', '201705', 50), ('2', '201708', 200), ('23', '201708', 1), ('23', '201705', 2); select * from @temp as a left join @temp as b on(b.a=a.a) where a.b='201705' and b.b='201708'; select * from @temp pivot(sum(c) for b in([201705],[201708])) as x
结果:

相关参考文章: