一、滑动窗口检测器
一种用于目标检测的暴力方法就是从左到右,从上到下滑动窗口,利用分类识别目标。为了在不同观察距离处检测不同的目标类型,我们可以使用不同大小和宽高比的窗口

得到窗口内的图片送入分类器,但是很多分类器只取固定大小的图像,所以这些图像需要经过一定的变形转换。但是,这不影响分类的准确率,因为分类器是可以处理变形后的图像

将图像变形转换成固定大小
变形图像块被输入CNN分类器中,提取4096个特征,使用SVM分类器识别类别和该边界框的另一个线性回归器
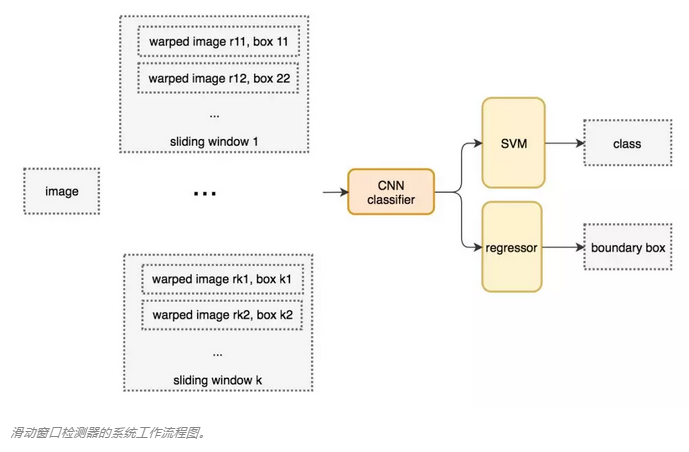
下面是伪代码,我们创建很多窗口来检测不同位置的不同目标。要提升性能,一个显而易见的办法就是减少窗口的数量
for window in windows patch = get_patch(image, window) results = detector(patch)
二、选择性搜索
不使用暴力方法,而是用候选区域方法(region proposal method)创建目标检测的感兴趣区域(ROI)。在选择性搜索(selective search,SS)中,我们可以先利用基于图的图像分割的方法得到小尺度的区域,然后一次次合并得到大的尺寸。考虑所有特征,例如颜色、纹理、大小等,同时照顾下计算复杂度。
在深入介绍Selective Search之前,先说明一下需要考虑的问题:
- 适应不同尺度(Capture All Scales):穷举搜索(Exhaustive Selective)通过改变窗口大小来适应物体的不同尺度,选择搜索(Selective Search)同样无法避免这个问题。算法采用图像分割(Image Segmentation)以及使用一种层次算法(Hierarchical Algorithm)有效地解决了这个问题
- 多样化(Diversification):单一的策略无法应对多种类别的图像,使用颜色、纹理、大小等多种策略对分割号的区域进行合并
- 速度快
选择性搜索的具体算法(区域合并算法)

输入:一张图片 输出:候选的目标位置集合 算法: 利用切分方法得到候选的区域集合R = {r1,r2,…,rn} 初始化相似集合S = ϕ foreach 遍历邻居区域对 (ri,rj) do 计算相似度s(ri,rj) S = S ∪ s(ri,rj) while S not=ϕ do 从s中得到最大的相似度s(ri,rj)=max(S) 合并对应的区域rt = ri ∪ rj 移除ri对应的所有相似度:S = Ss(ri,r*) 移除rj对应的所有相似度:S = Ss(r*,rj) 计算rt对应的相似度集合St S = S ∪ St R = R ∪ rt L = R中所有区域对应的边框
首先通过基于图的图像分割方法初始化原始区域,就是将图像分割成很多很多的小块,使用贪心策略,计算每两个相邻区域的相似度,然后每次合并最相似的两块,直至最终只剩下一块完整的图片。然后这其中每次产生的图像块包括合并的图像块我们都保存下来,这样就得到图像的分成表示,那么如何计算两个图像块的相似度呢?
三、保持多样性的策略
区域合并采用了多样性的策略,如果简单采用一种策略很容易错误合并不相似的区域,比如只考虑纹理时,不同颜色的区域很容易被误合并。选择性搜索采用三种多样性策略来增加候选区域以保证召回:
- 多种颜色空间,考虑RGB、灰度、HSV及其变种
- 多种相似度度量标准,既考虑颜色相似度,又考虑纹理、大小、重叠情况等
- 通过改变阈值初始化原始区域,阈值越大,分割的区域越少
1、颜色空间转换
通过色彩空间转换,将原始色彩空间转换到多达八种色彩空间。也是为了考虑场景以及光照条件等,主要应用于图像分割算法中原始区域的生成(两个像素点的相似度计算时,计算不同颜色空间下的两点距离)。主要使用的颜色空间有:(1)RGB,(2)灰度I,(3)Lab,(4)rgI(归一化的rg通道加上灰度),(5)HSV,(6)rgb(归一化的RGB),(7)C,(8)H(HSV通道的H)
2、区域相似度计算
我们在计算多种相似度的时候,都是把单一相似度的值归一化到[0, 1]之间,1表示两个区域之间相似度最大
-
颜色相似度
- 纹理相似度
- 有限合并小的区域
- 区域的合适度距离
- 合并上面四种相似度
四、给区域打分
通过上述步骤,我们可以得到很多区域,但是并不是每个区域作为目标的可能性都是相同的,我们要进行筛选。
做法:给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2,以此类推。但是当我们策略很多,多样性很多的时候,权重就会有太多的重合,这样排序就不太方便。我们可以给他们乘以一个随机数,然后对于相同的区域多次出现的也叠加下权重,毕竟多个方法都说你是目标,也是有理由的嘛。这样我们就得到所有区域的目标分数,也就可以根据自己的需要选择多少个区域了。
五、选择性搜索性能评估
自然地,通过算法计算得到的包含物体的Bounding Boxes与真实情况(ground truth)的窗口重叠越多,那么算法性能就越好。这是使用的指标是平均最高重叠率ABO(Average Best Overlap)。对于每个固定的类别c,每个真实情况(ground truth)表示为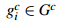 ,令计算得到的位置假设L中的每个值lj,那么 ABO的公式表达为:
,令计算得到的位置假设L中的每个值lj,那么 ABO的公式表达为:
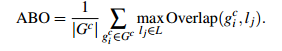
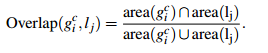
上面结果给出的是一个类别的ABO,对于所有类别下的性能评价,很自然就是使用所有类别的ABO的平均值MABO(Mean Average Best Overlap)来评价。
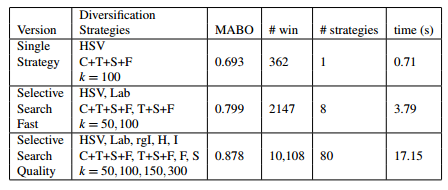
1、单一策略评估
我们可以通过改变多样性策略中的任何一种,评估选择性搜索的MABO性能指标。采取的策略如下:
- 使用RGB色彩空间
- 采用四中相似度计算的组合方式
- 设置图像分割的阈值k=50
2、多样性策略组合
我们使用贪婪搜索算法,把单一策略进行组合,会获得较高的MABO,但是也会造成计算成本的增加。

上图中绿色边框为对象的标记边框,红色边框为我们使用'Quality' Selective Search算法获得的Overlap最高的候选框。可以看到我们这个候选框和真实标记非常接近。
六、代码实现
我们可以通过下面的命令直接安装Selective Search包
pip install selectivesearch
然后从https://github.com/AlpacaDB/selectivesearch下载源码,运行exampleexample.py文件。效果如下:
# -*- coding: utf-8 -*- from __future__ import ( division, print_function, ) import skimage.data import matplotlib.pyplot as plt import matplotlib.patches as mpatches import selectivesearch import numpy as np def main(): # 加载图片数据 img = skimage.data.astronaut() ''' 执行selective search,regions格式如下 [ { 'rect': (left, top, width, height), 'labels': [...], 'size': component_size }, ... ] ''' img_lbl, regions = selectivesearch.selective_search( img, scale=500, sigma=0.9, min_size=10) #计算一共分割了多少个原始候选区域 temp = set() for i in range(img_lbl.shape[0]): for j in range(img_lbl.shape[1]): temp.add(img_lbl[i,j,3]) print(len(temp)) #286 #计算利用Selective Search算法得到了多少个候选区域 print(len(regions)) #570 #创建一个集合 元素不会重复,每一个元素都是一个list(左上角x,左上角y,宽,高),表示一个候选区域的边框 candidates = set() for r in regions: #排除重复的候选区 if r['rect'] in candidates: continue #排除小于 2000 pixels的候选区域(并不是bounding box中的区域大小) if r['size'] < 2000: continue #排除扭曲的候选区域边框 即只保留近似正方形的 x, y, w, h = r['rect'] if w / h > 1.2 or h / w > 1.2: continue candidates.add(r['rect']) #在原始图像上绘制候选区域边框 fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6)) ax.imshow(img) for x, y, w, h in candidates: print(x, y, w, h) rect = mpatches.Rectangle( (x, y), w, h, fill=False, edgecolor='red', linewidth=1) ax.add_patch(rect) plt.show() if __name__ == "__main__": main()

参考文章:
https://www.cnblogs.com/zyly/p/9259392.html
图像分割—基于图的图像分割(Graph-Based Image Segmentation)(附代码)
https://github.com/AlpacaDB/selectivesearch(代码)