1 从字符串说起
假设现在有几条数据,是以记事本文档的形式交到我们的手中
姓名:涂白竹 性别:女 年龄:15 班级:1班
姓名:江夜梅 性别:女 年龄:16 班级:1班
姓名:奉轩 性别:男 年龄:15 班级:1班
我们的任务是将他们录入到数据库中,并且这几个学生都要转到2班。怎么做?假设数据表已经建立好了。
第一思路:读取文档,通过换行符分割这几行数据,再将每条子串的倒数第二个字符替换为2.
代码如下:
StreamReader sr = new StreamReader("DOM演示\学生数据.txt",Encoding.Default); string s = sr.ReadToEnd(); sr.Close(); string[] students = s.Split(new String[]{" "},StringSplitOptions.None); foreach (string item in students) { string temp = item.Replace(item.Substring(item.IndexOf("班级:") + 3, item.Length - item.IndexOf("班级:") - 3), "2班"); Console.WriteLine(temp); }
运行结果:
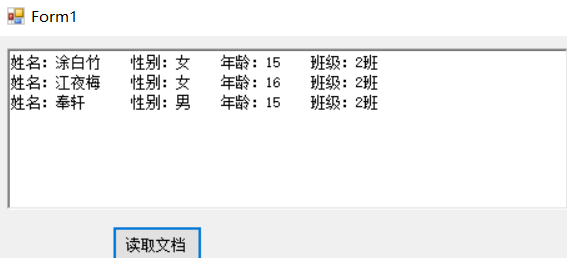
可以说非常麻烦。而且如果要改的是年龄呢?如果只是改(江夜梅)的年龄呢?那又要改代码了。每次调整需求就要改代码。
为了提高代码复用率,不如写成函数。
按照要求,是改任意一个人的任意属性。问题在于任何属性值的长度是不固定的。没办法像前面一样截取后2位更改。
1.1 文档规范化
思考一下XML或HTML是怎么做的。在值的前后加标记。
于是我们也仿照HTML制定一个规范:
姓名,必须在<name></name>中间
性别,必须在<sex></sex>中间
年龄,必须在<sex></sex>中间
班级,必须在<sex></sex>中间
现在来改造文档,用这种格式写
<name>涂白竹</name><sex>女</sex><age>15</age><class>1班</class> <name>江夜梅</name><sex>女</sex><age>16</age><class>1班</class> <name>奉轩</name><sex>男</sex><age>15</age><class>1班</class>
1.1.1 找到标签,和更改内容
现在再来改造代码:
public void update(string propertyName,string propertyValue) { StreamReader sr = new StreamReader("DOM演示\规范化学生数据.txt", Encoding.Default); string s = sr.ReadToEnd(); sr.Close(); string[] students = s.Split(new String[] { " " }, StringSplitOptions.None); foreach (string item in students) { int startIndex = item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2; int endIndex = item.IndexOf("</" + propertyName + ">"); int valueLength = endIndex - startIndex; string temp = item.Replace(item.Substring(item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2, valueLength), propertyValue); Console.WriteLine(temp); } }
调用:update("age", "20");
//update("class", "2班");
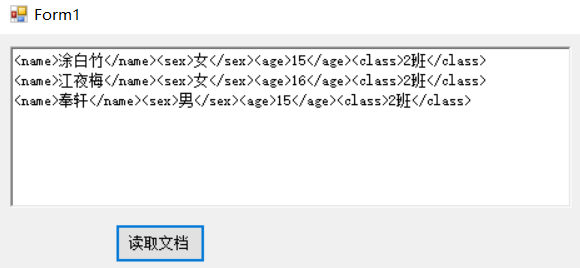
1.2 现在的问题是在显示时如何去掉标签?
不如专门写一个函数,去掉字符串”<“和">"之间的字符。然后在update()中每次输出时调用。
函数:获得指定串的所有位置
引用自:https://blog.csdn.net/iteye_19871/article/details/81495660
public int[]GetSubStrCountInStr(String str,String substr,int StartPos) { int foundPos=-1; int count=0; List<int> foundItems=new List<int>(); do { foundPos=str.IndexOf(substr,StartPos); if(foundPos>-1) { StartPos=foundPos+1; count++; foundItems.Add(foundPos); } }while(foundPos>-1&&StartPos<str.Length); return((int[])foundItems.ToArray()); }
调用这个函数完成对标记的去除,其实是反过来,只取值
public string remove(string student) { int[] left = GetSubStrCountInStr(student, "<", 0); int[] right = GetSubStrCountInStr(student, ">", 0); string newString = ""; for (int i=0,j=1;i<left.Length-1;i++,j++) { newString += student.Substring(right[i]+1, left[j] - right[i]-1)+" "; } return newString; }
然后在update()中调用
public void update(string propertyName,string propertyValue) { StreamReader sr = new StreamReader("DOM演示\规范化学生数据.txt", Encoding.Default); string s = sr.ReadToEnd(); sr.Close(); string[] students = s.Split(new String[] { " " }, StringSplitOptions.None); foreach (string item in students) { int startIndex = item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2; int endIndex = item.IndexOf("</" + propertyName + ">"); int valueLength = endIndex - startIndex; string temp = item.Replace(item.Substring(item.IndexOf("<" + propertyName + ">") + propertyName.Length + 2, valueLength), propertyValue); //string newString = remove(temp);<---这里调用 Console.WriteLine(newString); } }
现在就能实现对任意属性的修改了。
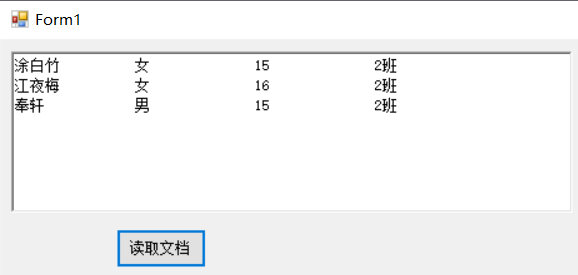
虽然修改成功了,但并没有指定特定的个人。当然,可以继续修改这个remove()函数。
我们的操作一共有查看(select),新增(insert),删除(delete),修改(update)。也就是说,每个操作都要写一个函数。
1.3 为了方便起见,我们把他们组织成一个类。但是组织成类。。。
现在要考虑的是学生的属性个数并不确定,可能会改变。
不如就像XML做的那样,把这些属性都看作节点,学生就是这些属性节点的父节点。这样就可以随意增添子节点(属性)。
那采用递归的方式比较好,采用设计模式里面的组合模式。假设类名叫Node,里面包含两个字段nodeName,txtValue外加一个集合child
1.4 现在可以再次改进文档
原来的的格式不足之处在于是通过换行符“ ”来区分不同记录的,当两条记录处于同一行就会出问题。而且这样不利于体现结构。
现在改成就像XML一样
<students> <student> <name>涂白竹</name> <sex>女</sex> <age>15</age> <class>1班</class> </student> <student> <name>江夜梅</name> <sex>女</sex> <age>16</age> <class>1班</class> </student> <student> <name>奉轩</name> <sex>男</sex> <age>15</age> <class>1班</class> </student> </students>
这样,从根节点开始,每个子节点<student>就是一条记录。
现在就可以利用Node来在内存中加载数据了。
利用有限状态自动机来读取文档,并在这个过程中保存数据,用于在正确结束后生成文档对象。
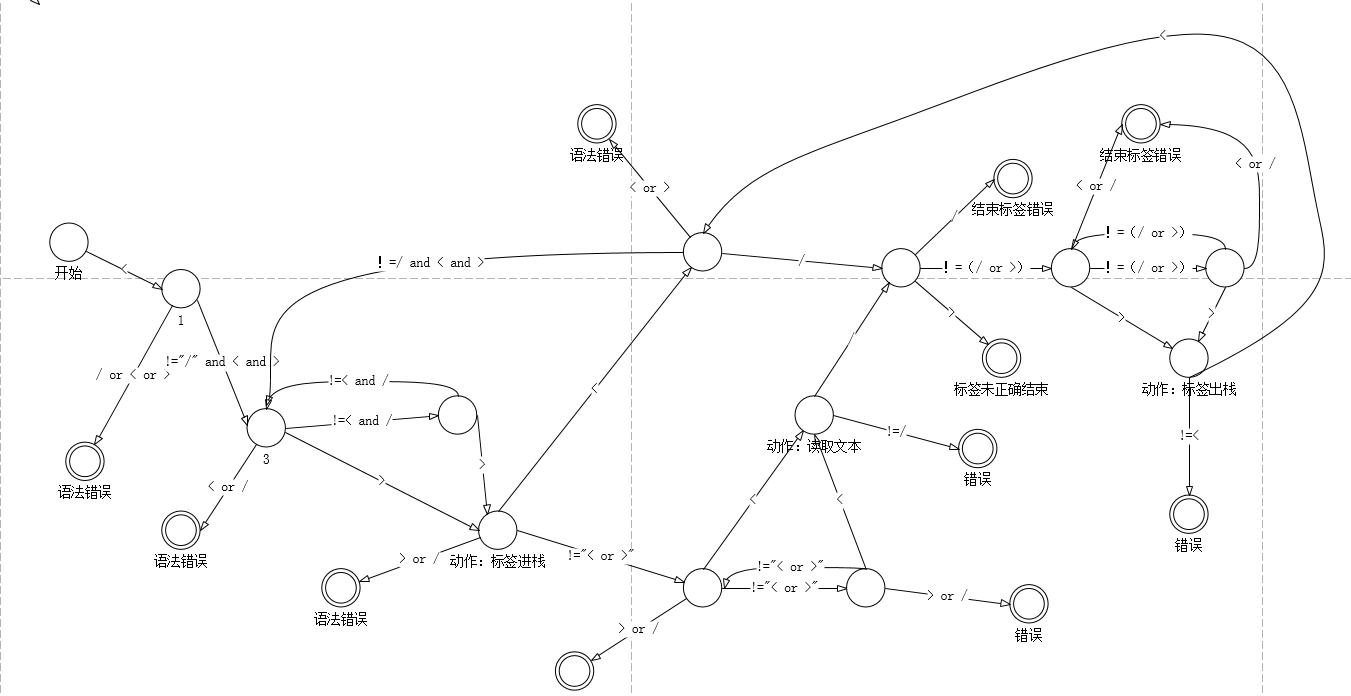
接下来就是实现了。待更新。。。
2 语法分析
更新5/29
文档规范化其实就是定义了一门语言,只允许我们以符合语法的形式写文档。因此我们建立文档对象模型其实就是编写一个解释器进行词法分析和语法分析,最终输出语法树。对于这里,一个文档就是一条语句。
2.1 词法分析器设计
这个自动机太复杂了,并且部分语法分析任务都被完成了,还是拆分一下,分成3个自动机,都写成一个函数。把左节点名,右节点名,文本都定义为单词,分别赋予单词种别码1,2,3待后面语法分析用。这里只做词法分析。
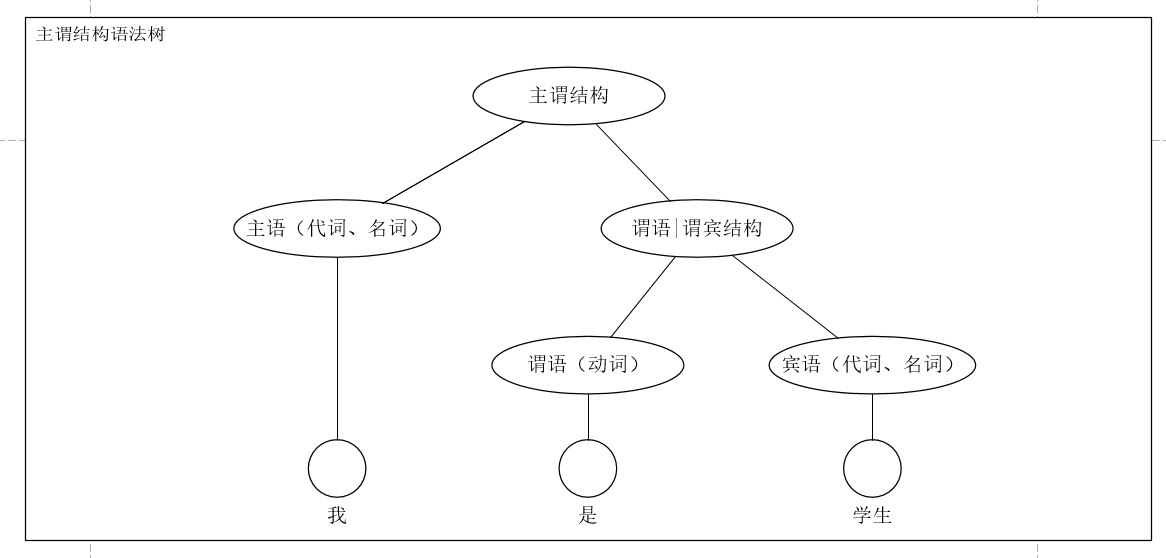
2.1.1 种别码是什么。
就是单词的词类。以汉语为例,我们知道,一般情况下主语后面要跟谓语,谓语后面跟宾语,但是填充主语、谓语和的词不是什么词都可以。主语位置上必须是我,你之类的代词或水,桌子之类的名词,谓语跟主语一样。因此单词的词类就分成了代词,动词,名词。在这里也是一样的,不过词类只有数字编号罢了,把填充左节点的单词叫做1类词,填充文本的单词叫做3类词,填充右节点的叫做3类词。汉语语法分析我们必须知道填在对应位置的词类正确与否,这里也一样。因此,在正式语法分析之前,必须知道单词是否有误和单词归类。
这点可以去阅读《语言学纲要》这本书
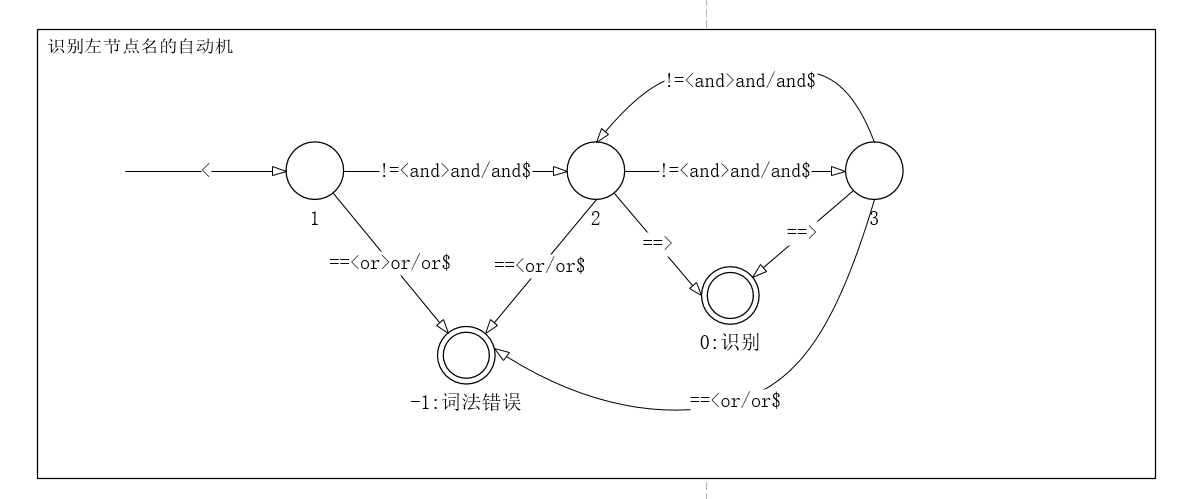
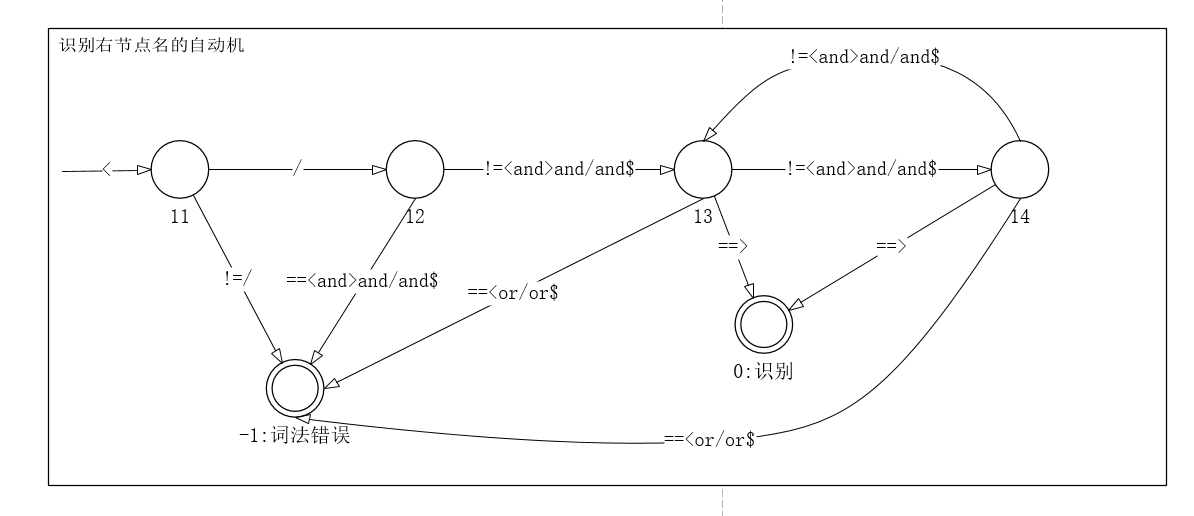
- 识别左标签名的自动机
- 识别左标签名的自动机
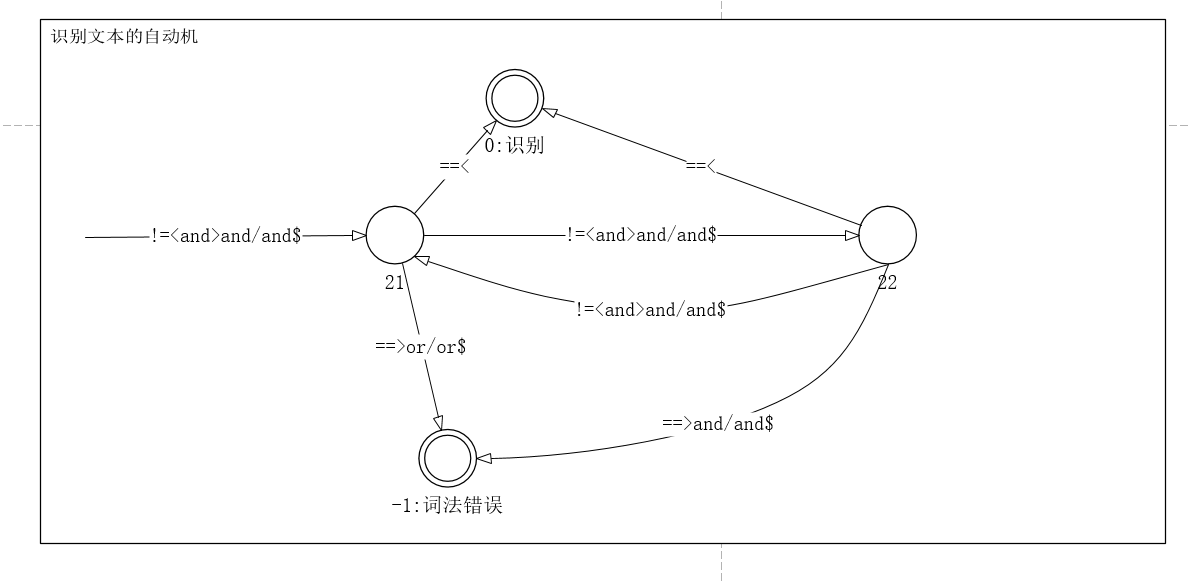
- 识别文本的自动机
通过一个函数通过switch(char)调用这三个自动机,并根据错误码对词法错误进行输出。如果成功通过词法分析,则把<单词值,种别码>的集合交给后面的语法分析器使用。用语法分析器建立起语法树。我们的就算完成了文档对象模型的创建。
3个自动机如下:
左节点:<值>
右节点:</值>
文本: 值
规定<,>,/,$是不能作为构成值的字符。
待更新词法分析器实现。。。
5/30更新
2.1.2 词法分析器实现
思路如下,词法分析器调用每个自动机扫描文档字符串 识别每个单词,自动机扫描失败换下一个自动机扫描。如果都失败了,则说明词法(构词)错误。
2.1.2.1 公共变量
static int cursor = 0;//扫描位置 static List<word> words;//符号表
2.1.2.2 word(单词)
class word { public int wordClass;//种别码 public string Value;//值 public word(int wordClass,string Value) { this.wordClass = wordClass; this.Value = Value; } }
2.1.2.3 识别左节点名的自动机


public static bool leftMachine(string str) { string Value=""; int count = 0; try { string nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar!="<")//开始符正确 { cursor--; return false; } nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar=="<" || nextChar==">" || nextChar=="/" || nextChar=="$")//第一个字符不正确 { cursor -= 2; return false; } Value += nextChar; nextChar = str.Substring(cursor, 1); while (nextChar != "<" && nextChar != "/" && nextChar != "$" && nextChar != ">") { cursor++; count++; Value += nextChar; nextChar = str.Substring(cursor, 1); } if (nextChar == "<" || nextChar == "/" || nextChar == "$") { for (int i = count; i > 0; i--) { cursor--; } return false; } else { cursor++;//跳过结尾符 words.Add(new word(1, Value)); return true; } } catch (Exception) { for (int i = count; i > 0; i--) { cursor--; } Console.WriteLine("超出索引"); return false; } }
2.1.2.4 识别文本的自动机
public static bool txtMachine(string str) { string Value = ""; int count = 0; try { string nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar=="<" || nextChar==">" || nextChar=="/" || nextChar=="$") { cursor--; return false; } else { Value += nextChar; nextChar = str.Substring(cursor, 1); cursor++; count++; while (nextChar != "<" && nextChar != ">" && nextChar != "/" && nextChar != "$") { Value += nextChar; nextChar = str.Substring(cursor, 1); cursor++; count++; } if (nextChar == ">" || nextChar == "/" || nextChar == "$") { for (int i = count; i > 0; i--) { cursor--; } return false; } else { cursor--; words.Add(new word(3, Value)); return true; } } } catch (Exception) { for (int i = count; i > 0; i--) { cursor--; } Console.WriteLine("超出索引"); return false; } }
2.1.2.5 识别右节点名的自动机
public static bool rightMachine(string str) { string Value = ""; int count = 0; try { string nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar!="<")//第一个开始符不正确 { cursor--; return false; } nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar!="/")//第二个开始符不正确 { cursor -= 2; return false; } nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar == "<" || nextChar == ">" || nextChar == "/" || nextChar == "$")//第一个字符不正确 { cursor -= 3; return false; } while (nextChar!="<" && nextChar!="/" && nextChar!="$" && nextChar!=">") { Value += nextChar; nextChar = str.Substring(cursor, 1); cursor++; count++; } if (nextChar=="<" || nextChar=="/" || nextChar=="$") { for (int i = count; i > 0; i--) { cursor--; } return false; } else { words.Add(new word(2, Value)); return true; } } catch (Exception) { for (int i = count; i > 0; i--) { cursor--; } Console.WriteLine("超出索引"); return false; } }
2.1.2 词法分析器
public static bool scanner(string fileName) { StreamReader sr = new StreamReader("DOM演示\规范化学生数据.txt", Encoding.Default);//这里假定文件已知 string s = sr.ReadToEnd(); sr.Close(); //预处理$非法字符 int indexOfInvalid = s.IndexOf("$"); if (indexOfInvalid != -1) { Console.WriteLine("文档非法字符:第" + indexOfInvalid + "个字符 字符:" + s.Substring(indexOfInvalid, 1)); if (indexOfInvalid - 6 < 0) { Console.WriteLine("所在子串:" + s.Substring(0, 20)); return false; } else if (indexOfInvalid + 20 > s.Length) { Console.WriteLine("所在子串:" + s.Substring(indexOfInvalid - 6, s.Length - indexOfInvalid)); return false; } else { Console.WriteLine("所在子串:" + s.Substring(indexOfInvalid - 6, 20)); return false; } } //预处理,去空格 s = s.Replace(" ", ""); s = s.Replace(" ", ""); s = s.Replace(" ", ""); cursor = 0; words = new List<word>(); while (cursor<s.Length)//调用自动机 { if (!leftMachine(s)) { if (!txtMachine(s)) { if (!rightMachine(s)) { Console.WriteLine("分析串:"+s); Console.WriteLine("词法错误,词法分析停止!"); try { Console.WriteLine("错误子串"+s.Substring(cursor, 10)); return false; } catch (Exception) { Console.WriteLine("错误子串" + s.Substring(cursor, s.Length - cursor)); return false; } } } } } Console.WriteLine("词法分析正确"); return true; }
2.1.2.1 测试
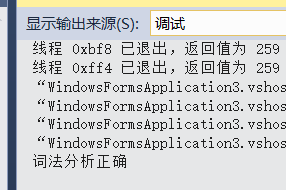
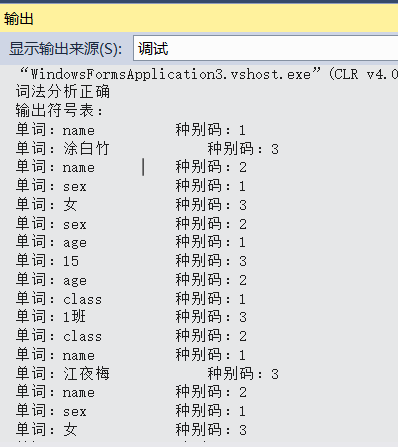
输出一下:
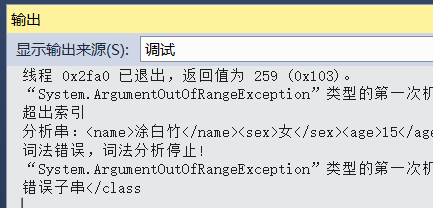
错误测试,将最后一个结束符去掉(</class)
待更新语法分析器。。。
2.2 语法分析
语法分析器的任务是将词法分析器输出的符号表转化为语法树,也就是我们的文档对象模型。具体的工作方式是从符号表中一个个读出单词到一个栈中。
2.2.1 语法规则
产生式如下:
假设left代表左节点名,right代表右节点名,text代表文本,N代表子节点,E代表根节点。大写字母成为非终结符,小写字母成称为终结符。
- E->E1 | E2(根节点有两种可能的情况)
- E1->left N right(根节点可以有子节点)
- E2->left text right(根节点可以没有有子节点)
- N->N1 | N2 | N3(子节点有三种可能的情况)
- N1->left N right(子节点可以有子节点)
- N2->N N(子根节点可以有兄弟节点)
- N3->left text right(子节点可以没有子节点)
在上面的几条规则中,由于存在无限递归情况:4->6->4->6->4....
在从E向下推导的时候会出现无限递归,这导致了当字符串包含7所定义的情况时,语法分析器会陷入无限循环。这被称为左递归,确定左递归的方法是看解决方法有两种
- 6和7交换位置,在程序中先判断7再判断6。但这样对于语法错误时一样会无限递归,不是很好的解决方案。
- 消除左递归。对于N->N2 <=> N->N N 和N->left text right 可以改成N->left text right N` ,N`->空值
得到的结果如下:
- E->E1 | E2(根节点有两种可能的情况)
- E1->left N right(根节点可以有子节点)
- E2->left text right(根节点可以没有有子节点)
- N->N1 | N2 | N3 (非根节点有三种可能的情况)
- N1->left N right N(非根节点可以有子节点和兄弟)
- N2->left text right N(非根节点的子节点可以有兄弟节点)
- N3->空值(非根节点可以为空值)
5/32更新
采用递归下降分析遇到了两个问题。
- 空值没有对应的输入,就是说没有单词的类别是空值。
- 修改了语法规则后,使得语言能够接受空文本
问题出在哪?7的意思是说,假设某节点的兄弟为空,那么就意味着下一个输入只能是父节点的结束标签,只能是right;如果假设某节点的子节点为空值,则意味着下一个输入是本节点的结束标签,只能是right。
也就是说,当进入7时,我们需要看下一个单词是什么,当是right时则产生式匹配,否则就是语法错误。也就是说,需要预测分析。
上面的语法还有一个问题,部分匹配,即是说输入串在没有全部匹配完成,仅仅是部分匹配成功后就会完成语法分析,而从整个串来说,语法是错误的。
比如:
<student> <name>涂白竹</name><sex>女</sex><age>15</age><class>1班</class> </student> <student> <name>江夜梅</name><sex>女</sex><age>16</age><class>1班</class> </student> <student> <name>奉轩</name><sex>男</sex><age>15</age><class>1班</class> </student> </students>
在这里,第一个学生作为根节点匹配完成后就退出了语法分析,没有对之后的情况分析。
因此还要改造语法,在产生式中明确指出,根节点完成分析后继续向后分析,不能有兄弟节点。
改造如下:
- E1->left N right E3(根节点可以有子节点但不能有兄弟节点)
- E2->left text right N3(根节点可以没有有子节点而且不能有兄弟节点)
- E3->空值
在这里的空值的意义是下一个标签不存在(索引超出单词表)
完整产生式如下:
- E1->left N right E3(根节点可以有子节点但不能有兄弟节点)
- E2->left text right N3(根节点可以没有有子节点而且不能有兄弟节点)
- E3->空值(根节点的兄弟节点只能为空值)
- N->N1 | N2 | N3 (非根节点有三种可能的情况)
- N1->left N right N(非根节点可以有子节点和兄弟)
- N2->left text right N(非根节点的子节点可以有兄弟节点)
- N3->空值(非根节点可以为空值)
在这里推荐一下
https://www.bilibili.com/video/BV1jE411B7Me 【斯坦福编译原理中文翻译版】24 递归下降解析
https://www.bilibili.com/video/BV1YE411i71L 【斯坦福编译原理中文翻译版】25 递归下降算法
在这两个视频中解释了如何写递归下降程序,但没有对左递归(无限递归)进行处理
2.2.2 递归下降语法分析器实现:
//语法分析器
public static bool E()
{
if (E1() || E2())
{
return true;
}
else
return false;
}
public static bool E1()
{
wordsCursor++;
if (words[wordsCursor].wordClass==1)
{
word left = words[wordsCursor];
if (N())//有子节点
{
wordsCursor++;
if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value == left.Value)
{
if (E3())
{
return true;
}
else
{
wordsCursor -= 2;
return false;
}
}
else
{
wordsCursor-=2;
return false;
}
}
else
{
wordsCursor -= 1;
return false;
}
}
else
{
wordsCursor--;
return false;
}
}
public static bool E2()
{
wordsCursor++;
if (words[wordsCursor].wordClass == 1)
{
word left=words[wordsCursor];
wordsCursor++;
if (words[wordsCursor].wordClass == 3)
{
wordsCursor++;
if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value==left.Value)
{
if (E3())
{
return true;
}
else
{
wordsCursor -= 3;
return false;
}
}
else
{
wordsCursor -= 3;
return false;
}
}
else
{
wordsCursor-=2;
return false;
}
}
else
{
wordsCursor--;
return false;
}
}
public static bool E3()
{
if (wordsCursor == words.Count - 1)
{
return true;
}
else
return false;
}
public static bool N()
{
if (N1() || N2() || N3())
{
return true;
}
else
return false;
}
public static bool N1()
{
wordsCursor++;
word show = words[wordsCursor];
if (words[wordsCursor].wordClass == 1)
{
word left = words[wordsCursor];
if (N())
{
wordsCursor++;
if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value==left.Value)
{
if (N())
{
return true;
}
else
{
wordsCursor -= 2;
return false;
}
}
else
{
wordsCursor -= 2;
return false;
}
}
else
{
wordsCursor --;
return false;
}
}
else
{
wordsCursor--;
return false;
}
}
public static bool N2()
{
wordsCursor++;
if (words[wordsCursor].wordClass == 1)
{
word left = words[wordsCursor];
wordsCursor++;
if (words[wordsCursor].wordClass == 3)
{
wordsCursor++;
if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value == left.Value)
{
if (N())
{
return true;
}
else
{
wordsCursor -= 3;
return false;
}
}
else
{
wordsCursor -= 3;
return false;
}
}
else
{
wordsCursor -= 2;
return false;
}
}
else
{
wordsCursor--;
return false;
}
}
public static bool N3()
{
if (words[wordsCursor + 1].wordClass == 2)//下一个单词是right
{
return true;
}
else
return false;
}
这个语法分析器的入口是E(),使用前面词法分析器的单词表作为输入,使用游标在单词表中移动
static int wordsCursor = -1;//游标 static List<word> words;//符号表
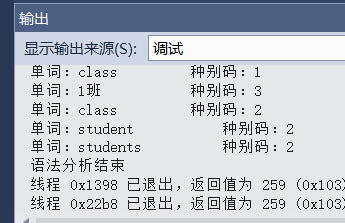
测试一下,正确语法:
多根节点语法:
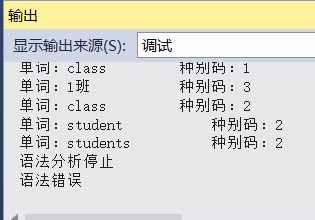
空文本测试证明语法确实稍有改变:
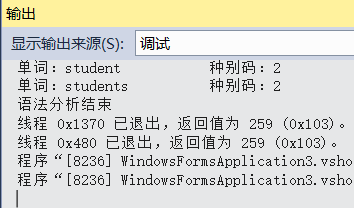
对于一些语法错误是可以提示的,只需要在有些函数返回false前进行输出就行了。比如多根节点错误可以在E3()返回false的语句分支中进行输出。
2.2.3 下一步,在语法分析过程中建立语法树
待更新。。。
6/1更新
完整代码:
class Node { public string nodeName;//节点名 public string txtValue="";//文本 public List<Node> child; public Node parent; public Node(string nodeName,string txtValue,Node parent) { this.nodeName = nodeName; this.txtValue = txtValue; this.child = new List<Node>(); this.parent = parent; } public Node() { this.child = new List<Node>(); } //打印节点树 public void print(string tab) { if (root!=null) { Console.WriteLine(tab+this.nodeName); if (this.txtValue!="") { Console.WriteLine(" " + tab + this.txtValue); } foreach (Node item in this.child) { item.print(tab+tab); } Console.WriteLine(tab + this.nodeName); } } static int cursor = 0;//扫描位置 static List<word> words;//符号表 //词法分析器 public static bool scanner(string fileName) { StreamReader sr = new StreamReader("DOM演示\规范化学生数据.txt", Encoding.Default);//这里假定文件已知 string s = sr.ReadToEnd(); sr.Close(); //预处理$非法字符 int indexOfInvalid = s.IndexOf("$"); if (indexOfInvalid != -1) { Console.WriteLine("文档非法字符:第" + indexOfInvalid + "个字符 字符:" + s.Substring(indexOfInvalid, 1)); if (indexOfInvalid - 6 < 0) { Console.WriteLine("所在子串:" + s.Substring(0, 20)); return false; } else if (indexOfInvalid + 20 > s.Length) { Console.WriteLine("所在子串:" + s.Substring(indexOfInvalid - 6, s.Length - indexOfInvalid)); return false; } else { Console.WriteLine("所在子串:" + s.Substring(indexOfInvalid - 6, 20)); return false; } } //预处理,去空格 s = s.Replace(" ", ""); s = s.Replace(" ", ""); s = s.Replace(" ", ""); cursor = 0; words = new List<word>(); while (cursor<s.Length)//调用自动机 { if (!leftMachine(s)) { if (!txtMachine(s)) { if (!rightMachine(s)) { Console.WriteLine("分析串:"+s); Console.WriteLine("词法错误,词法分析停止!"); try { Console.WriteLine("错误子串"+s.Substring(cursor, 10)); return false; } catch (Exception) { Console.WriteLine("错误子串" + s.Substring(cursor, s.Length - cursor)); return false; } } } } } Console.WriteLine("词法分析正确 输出符号表:"); foreach (word item in words) { Console.WriteLine("单词:" + item.Value + " 种别码:" + item.wordClass); } return true; } public static bool leftMachine(string str) { string Value=""; int count = 0; try { string nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar!="<")//开始符正确 { cursor--; return false; } nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar=="<" || nextChar==">" || nextChar=="/" || nextChar=="$")//第一个字符不正确 { cursor -= 2; return false; } Value += nextChar; nextChar = str.Substring(cursor, 1); while (nextChar != "<" && nextChar != "/" && nextChar != "$" && nextChar != ">") { cursor++; count++; Value += nextChar; nextChar = str.Substring(cursor, 1); } if (nextChar == "<" || nextChar == "/" || nextChar == "$") { for (int i = count; i > 0; i--) { cursor--; } return false; } else { cursor++;//跳过结尾符 words.Add(new word(1, Value)); return true; } } catch (Exception) { for (int i = count; i > 0; i--) { cursor--; } Console.WriteLine("超出索引"); return false; } } public static bool txtMachine(string str) { string Value = ""; int count = 0; try { string nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar=="<" || nextChar==">" || nextChar=="/" || nextChar=="$") { cursor--; return false; } else { Value += nextChar; nextChar = str.Substring(cursor, 1); cursor++; count++; while (nextChar != "<" && nextChar != ">" && nextChar != "/" && nextChar != "$") { Value += nextChar; nextChar = str.Substring(cursor, 1); cursor++; count++; } if (nextChar == ">" || nextChar == "/" || nextChar == "$") { for (int i = count; i > 0; i--) { cursor--; } return false; } else { cursor--; words.Add(new word(3, Value)); return true; } } } catch (Exception) { for (int i = count; i > 0; i--) { cursor--; } Console.WriteLine("超出索引"); return false; } } public static bool rightMachine(string str) { string Value = ""; int count = 0; try { string nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar!="<")//第一个开始符不正确 { cursor--; return false; } nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar!="/")//第二个开始符不正确 { cursor -= 2; return false; } nextChar = str.Substring(cursor, 1); cursor++; count++; if (nextChar == "<" || nextChar == ">" || nextChar == "/" || nextChar == "$")//第一个字符不正确 { cursor -= 3; return false; } while (nextChar!="<" && nextChar!="/" && nextChar!="$" && nextChar!=">") { Value += nextChar; nextChar = str.Substring(cursor, 1); cursor++; count++; } if (nextChar=="<" || nextChar=="/" || nextChar=="$") { for (int i = count; i > 0; i--) { cursor--; } return false; } else { words.Add(new word(2, Value)); return true; } } catch (Exception) { for (int i = count; i > 0; i--) { cursor--; } Console.WriteLine("超出索引"); return false; } } static int wordsCursor = -1;//游标 public static Node root; //语法分析器入口(非终结符E) public static bool E() { //父节点并不知道子节点信息,因此只能把自己传入创建子节点的非终结符函数中 root = new Node(); if (E1(root) || E2(root)) { return true; } else return false; } //非终结符E1 public static bool E1(Node node) { wordsCursor++; node.nodeName = words[wordsCursor].Value; if (words[wordsCursor].wordClass==1) { word left = words[wordsCursor]; if (N(node))//有子节点 { wordsCursor++; //左右节点名相同 if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value == left.Value) { if (E3())//没有兄弟节点 { return true; } else { wordsCursor -= 2; node = null; return false; } } else { wordsCursor-=2; node = null; return false; } } else { wordsCursor -= 1; node = null; return false; } } else { wordsCursor--; node = null; return false; } } //非终结符E2 public static bool E2(Node node) { wordsCursor++; node.nodeName = words[wordsCursor].Value; if (words[wordsCursor].wordClass == 1) { word left=words[wordsCursor]; wordsCursor++; node.txtValue = words[wordsCursor].Value; if (words[wordsCursor].wordClass == 3) { wordsCursor++; if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value==left.Value) { if (E3())//没有兄弟节点 { return true; } else { wordsCursor -= 3; node = null; return false; } } else { wordsCursor -= 3; node = null; return false; } } else { wordsCursor-=2; node = null; return false; } } else { wordsCursor--; node = null; return false; } } //非终结符E3 public static bool E3() { if (wordsCursor == words.Count - 1) { return true; } else return false; } public static bool N(Node node) { if (N1(node) || N2(node) || N3()) { return true; } else return false; } public static bool N1(Node node) { wordsCursor++; Node child = new Node(); child.nodeName = words[wordsCursor].Value; word show = words[wordsCursor]; if (words[wordsCursor].wordClass == 1) { word left = words[wordsCursor]; if (N(child))//有子节点 { wordsCursor++; if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value==left.Value) { if (N(node))//兄弟节点 { //产生式匹配成功 node.child.Add(child); child.parent = node; return true; } else { //产生式匹配失败 wordsCursor -= 2; child = null; return false; } } else { wordsCursor -= 2; child = null; return false; } } else { wordsCursor --; child = null; return false; } } else { wordsCursor--; child = null; return false; } } public static bool N2(Node node) { wordsCursor++; Node child = new Node(); child.nodeName = words[wordsCursor].Value; if (words[wordsCursor].wordClass == 1) { word left = words[wordsCursor]; wordsCursor++; child.txtValue = words[wordsCursor].Value; if (words[wordsCursor].wordClass == 3) { wordsCursor++; if (words[wordsCursor].wordClass == 2 && words[wordsCursor].Value == left.Value) { if (N(node))//兄弟节点 { node.child.Add(child); child.parent = node; return true; } else { wordsCursor -= 3; child = null; return false; } } else { wordsCursor -= 3; child = null; return false; } } else { wordsCursor -= 2; child = null; return false; } } else { wordsCursor--; child = null; return false; } } public static bool N3() { if (words[wordsCursor + 1].wordClass == 2)//下一个单词是right,没有兄弟节点,空节点 { return true; } else return false; } }
按照前面的正确语法运行一遍:
调用:
if (Node.scanner("")) { if (Node.E()) { Console.WriteLine("语法分析结束"); Node.root.print(" "); } else Console.WriteLine("语法分析停止 语法错误"); }
输出:
词法分析器输出:
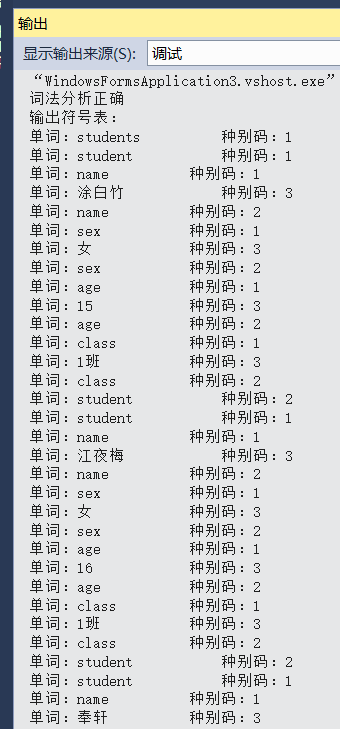
语法分析器建立语法树输出:

至此文档对象模型可以说已经建立,只需要添加一些在树里面操作节点的函数了。
不过从完整的翻译角度讲还可以进行语义分析,虽然这里并不需要。
者