引言
一直久闻kaggle大名,自己也陆陆续续学了一些机器学习方面的知识,想在kaggle上面尝试一下,但是因为各种烦杂的事情和课业拖累,一直没时间参加一次kaggle的比赛。这次我将用kaggle的入门赛:Titanic: Machine Learning from Disaster来让我熟悉比赛流程和各种数据处理技巧,也让和我一样第一次接触kaggle的萌新们快速上手。本文旨在完整走一遍kaggle流程,并不旨在获得一个很高的分数,因为特征处理和超参数的选择都较为随意。
数据认识
虽然我们一直戏称机器学习就是
train,target = load_data()
model.fit(data_train, data_taget)
model.predict(test)
我也一直吐槽机器学习就像炼丹,但是没有充分的数据认识和特征工程,预测出来的数据准确率将无法保证。那让我们看看我们手上的数据长啥样吧。
我们手上的文件一份是train.csv,一份是test.csv。我们用pandas将它打开
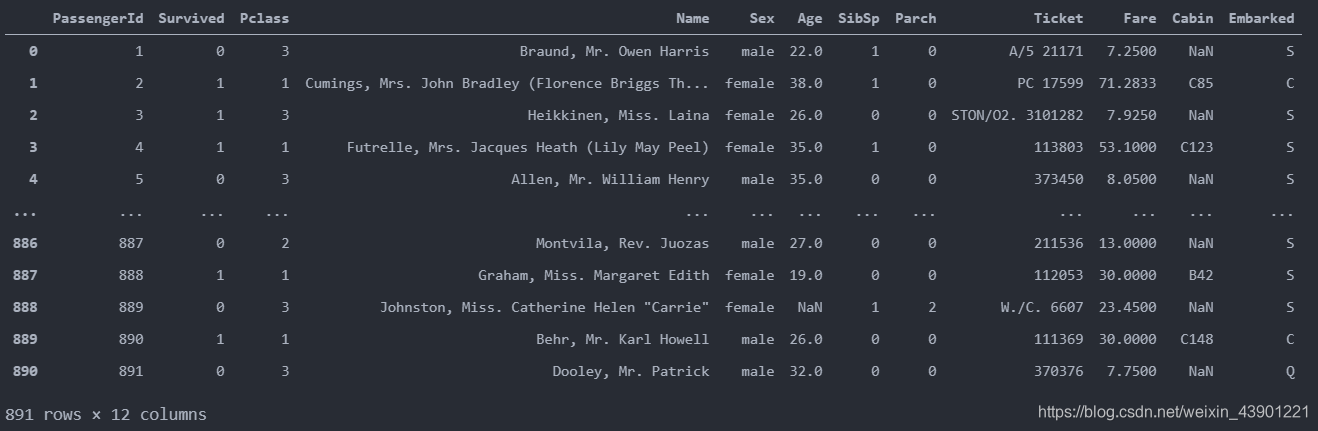
我们看到,总共有12列,其中Survived字段表示的是该乘客是否获救,其余都是乘客的个人信息,包括:
- PassengerId: 乘客ID
- Pclass: 乘客等级(1/2/3等舱位)
- Name: 乘客姓名
- Sex: 性别
- Age: 年龄
- SibSp: 堂兄弟/妹个数
- Parch: 父母与小孩个数
- Ticket: 船票信息
- Fare: 票价
- Cabin: 客舱
- Embarked: 登船港口
我们首先使用pandas自带的两种方法查看data_train的综合信息。
data_train.info()
我们可以看到我们的Age数据略有缺失,而cabin数据缺失严重,后面肯定要进行处理。

data_train.describe()
从这里我们可以看到Survived只有0.38,说明只有三分之一的人获救。船上的平均年龄是29.6岁,最大可达80岁。

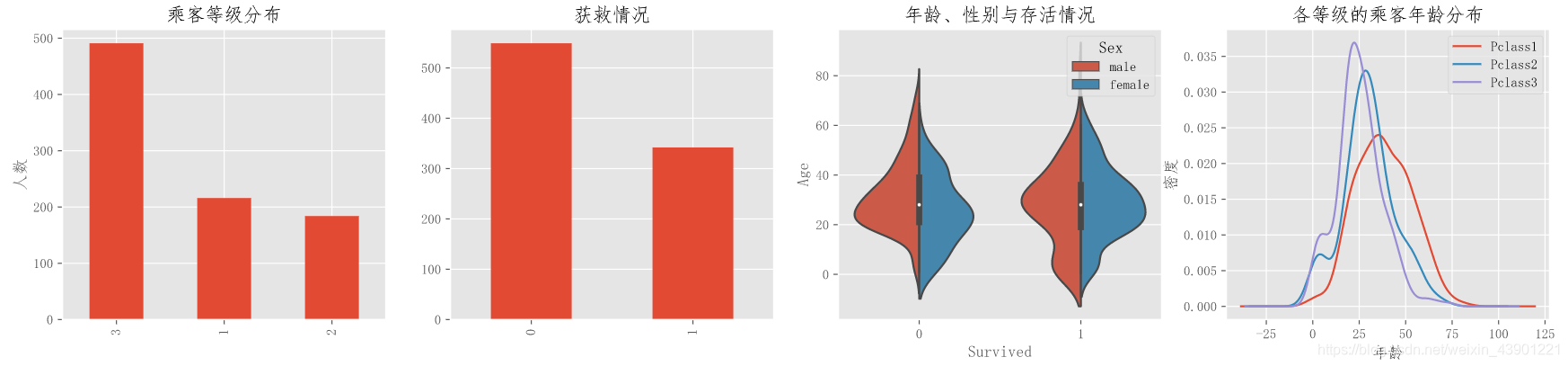
上面都是非常概括的数据,我们需要对数据有一个更直观的认识。我们使用matplotlib和snsborn两个包来进行可视化分析。
fig=plt.figure(figsize=(20,4))
plt.subplot(1,4,1)
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel("人数")
plt.title("乘客等级分布")
plt.subplot(1,4,2)
data_train['Survived'].value_counts().plot(kind='bar')
plt.ylabel("人数")
plt.title('获救情况')
plt.subplot(1,4,3)
sns.violinplot(x='Survived',y='Age',data=data_train,hue='Sex',split=True)
plt.title('年龄、性别与存活情况')
plt.subplot(1,4,4)
data_train['Age'][data_train['Pclass'] == 1].plot(kind='kde')
data_train['Age'][data_train['Pclass'] == 2].plot(kind='kde')
data_train['Age'][data_train['Pclass'] == 3].plot(kind='kde')
plt.xlabel("年龄")# plots an axis lable
plt.ylabel("密度")
plt.title("各等级的乘客年龄分布")
plt.legend(('Pclass1','Pclass2','Pclass3'))
果然图片要直观多了。我们发现三号舱位的乘客最多,乘客年龄主要分布在20-40附近。各个船舱的年龄分布大致相同。
survived_1=data_train['Sex'][data_train['Survived']==1].value_counts()
survived_0=data_train['Sex'][data_train['Survived']==0].value_counts()
df_survived=pd.DataFrame({'0':survived_0,'1':survived_1})
df_survived.plot(kind='bar',stacked=True)
plt.title('性别与存活情况')
这里可以看出女性获救比例远远高于男性,这也映证了在泰坦尼克号事故中的Lady First(毕竟男同胞们都是绅士嘛)

survived_1=data_train['Pclass'][data_train['Survived']==1].value_counts()
survived_0=data_train['Pclass'][data_train['Survived']==0].value_counts()
df_survived=pd.DataFrame({'0':survived_0,'1':survived_1})
df_survived.plot(kind='bar',stacked=True)
plt.title('舱位与存活情况')
虽然各个舱位获救的人数大致相当,但是1号和2号船舱的获救率还是远远高于3号船舱,可见金钱也是能提高生存率的=。=

总结
- 性别是极大的影响因素,女性的生还率比男性高出不止一倍。
- 不同的舱位代表着财富的不同,我们可以看出越是昂贵的舱位生还率越是高。
特征处理
现在我们对数据有了一个直观的认识,那接下来就是至关重要的特征处理了,特征处理的好坏直接影响最后模型预测结果的准确性和泛化能力。
我们先处理缺失数据,Cabin数据缺失过多,我们可以将NaN直接作为一个特征,将非缺失数据设为Yes。
data_train.loc[data_train['Cabin'].notnull(),'Cabin']='Yes'
data_train.loc[data_train['Cabin'].isnull(),'Cabin']='No'
对于Age,age缺失的数据适中,我们可以试着通过已有数据将其拟合出来。这里我们采用RandomForest来拟合一下缺失的年龄数据。
# 利用随机森林拟合缺失的年龄数据
from sklearn.ensemble import RandomForestRegressor
age_train=data_train[data_train['Age'].notnull()].drop(['Age','Survived'],axis=1)
age=data_train['Age'][data_train['Age'].notnull()]
age_unknow=data_train[data_train['Age'].isnull()].drop(['Age','Survived'],axis=1)
rfr=RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(age_train,age)
age_predict=rfr.predict(age_unknow)
data_train['Age'][data_train['Age'].isnull()]=age_predict
不同的数据我们有不同的处理方式:
- 对于离散型数据,例如Sex和Cabin,我们可以对它进行one-hot编码。
- 对于连续型数据,例如Age和Fare,我们可以将其标准化,将其映射至[-1,1]之间。因为不同属性的scale不同,将对收敛速度造成极大的影响,当然我们也可以使用Adagrad算法解决这个问题。
对于Cabin、Sex和Embarked,我们使用pandas的get_dummies方法将其进行one-hot编码。顺便丢弃无用特征(当然不是真的无用,只是目前我无法从中看出规律,日后我会对其做更详细的分析)
# 对部分数据进行 one—hot编码
sex_dummies=pd.get_dummies(data_train['Sex'],prefix='Sex')
embarked_dummies=pd.get_dummies(data_train['Embarked'],prefix='Embarked')
cabin_dummies=pd.get_dummies(data_train['Cabin'],prefix='Cabin')
data_train=data_train.join([sex_dummies,embarked_dummies,cabin_dummies])
data_train.drop(['Sex','Embarked','Cabin','Name','PassengerId','Ticket'],axis=1,inplace=True)
data_train
得到

然后将Age和Fare进行标准化,得到无量纲数据
# 标准化
from sklearn.preprocessing import StandardScaler
std=StandardScaler()
data_train.loc[:,['Age','Fare']]=std.fit_transform(data_train.loc[:,['Age','Fare']])
然后我们就处理好了我们所需要的训练集
# 训练集
x=data_train.iloc[:,1:]
y=data_train.iloc[:,0]
当然我们不仅需要对训练数据进行处理,还需要同时将测试数据同训练数据一起处理,使得二者具有相同的数据类型和数据分布。
# 将预测集数据作相同处理
data_test=pd.read_csv('test.csv')
data_test.loc[data_test['Cabin'].notnull(),'Cabin']='Yes'
data_test.loc[data_test['Cabin'].isnull(),'Cabin']='No'
sex_dummies=pd.get_dummies(data_test['Sex'],prefix='Sex')
embarked_dummies=pd.get_dummies(data_test['Embarked'],prefix='Embarked')
cabin_dummies=pd.get_dummies(data_test['Cabin'],prefix='Cabin')
data_test=data_test.join([sex_dummies,embarked_dummies,cabin_dummies])
data_test.drop(['Sex','Embarked','Cabin','Name','Ticket'],axis=1,inplace=True)
age_unknow=data_test[data_test['Age'].isnull()].drop(['Age','PassengerId'],axis=1)
age_predict=rfr.predict(age_unknow)
data_test['Age'][data_test['Age'].isnull()]=age_predict
std=StandardScaler()
data_test.loc[:,['Age','Fare']]=std.fit_transform(data_test.loc[:,['Age','Fare']])
data_test.fillna(data_test.mean(),inplace=True) # 用均值填充fare缺失值
建模预测
这里就是人们最喜欢的调参炼丹环节啦,开始我们快乐的model.fit()和model.predict()。
logistic分类模型
# logistic预测
# 建模
from sklearn import linear_model
lr=linear_model.LogisticRegression(C=1.0,penalty='l2',solver='liblinear',tol=1e-6)
lr.fit(x,y)
survived_predict=lr.predict(data_test.drop('PassengerId',axis=1))
result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':survived_predict})
result.to_csv("logistic_regression_predictions.csv", index=False)
最后得分0.76555,emmm。。。
随机森林
# 随机森林预测
from sklearn.ensemble import RandomForestClassifier
rfr2=RandomForestClassifier(random_state=0,n_estimators=2000,n_jobs=-1)
rfr2.fit(x,y)
survived_predict=rfr2.predict(data_test.drop('PassengerId',axis=1))
result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':survived_predict})
result.to_csv("RandomForestClassifier_predictions.csv", index=False)
得分0.75598,比logistic还差了
SVM
from sklearn.svm import SVC
svc=sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True,
probability=True, tol=0.001, cache_size=200, class_weight=None,
verbose=False, max_iter=-1, decision_function_shape='ovr',
random_state=None)
svc.fit(x,y)
survived_predict=svc.predict(data_test.drop('PassengerId',axis=1))
result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':survived_predict})
result.to_csv("SVC_predictions.csv", index=False)
最后得分0.77511,有进步!
xgboost
我们来尝试一下大名鼎鼎的xgboost
from xgboost import XGBClassifier
xgb = XGBClassifier(learning_rate=0.01,
n_estimators=10, # 树的个数-10棵树建立xgboost
max_depth=4, # 树的深度
min_child_weight = 1, # 叶子节点最小权重
gamma=0., # 惩罚项中叶子结点个数前的参数
subsample=1, # 所有样本建立决策树
colsample_btree=1, # 所有特征建立决策树
scale_pos_weight=1, # 解决样本个数不平衡的问题
random_state=27, # 随机数
slient = 0
)
xgb.fit(x,y)
survived_predict=xgb.predict(data_test.drop('PassengerId',axis=1))
result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':survived_predict})
result.to_csv("XGBClassifier_predictions.csv", index=False)
得分0.77033,怎么比svm还差一点,可能是调参的问题,以后我再来尝试一下。
模型验证
交叉验证
因为我们手上只有一份训练集,所以我们可以通过交叉验证的方式进行模型检验(有人会问为什么不直接提交结果进行验证,因为每日的提交是有次数限制的啊,而且有时候上交的人多要等5分钟才出结果)。交叉验证的思想就是将所有数据分成n份,每次取一份作为测试集,其余作为训练集。
# 交叉验证
from sklearn.model_selection import cross_val_score
cross_val_score(lr,x,y,cv=5)
学习曲线
高偏差:
随着样本数量的增加,测试集与交叉验证集的偏差几乎相等,这代表着,在高偏差(欠拟合)的情况下,增加数据集并不会优化算法。

解决方法:
- 增加特征
- 增加多项式
- 减小正则化
高方差
随着样本数量的增加,测试集与交叉验证集的偏差仍有很大的差距,这代表着,在高方差(过拟合)的情况下,增加数据集会一定程度上优化算法。

解决方法:
- 更多训练集
- 减少特征
- 增大正则化
# learning curve
from sklearn.model_selection import learning_curve
train_sizes,train_scores,test_scores=learning_curve(vote,x,y,train_sizes=np.linspace(0.5,1,20))
train_scores_mean=np.mean(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
plt.plot(train_sizes,train_scores_mean,'o-',color='b',label='train')
plt.plot(train_sizes,test_scores_mean,'o-',color='r',label='test')
plt.legend()
plt.gca().invert_yaxis()
这里我们可以看出我们的模型处于高偏差状态,我们应该增加特征数量,我们去除的名字和船票可能能帮助我们改善模型

模型融合
最后我们将使用最终武器,模型融合。
俗话说三个臭皮匠顶个诸葛亮,每个模型有每个模型的长处和短处,这时候我们让所有模型都进行预测,然后投票选择最终答案,不就能大大提高正确率吗。这就是Voting Bagging的思想。
Bagging 将多个模型,也就是多个基学习器的预测结果进行简单的加权平均或者投票。它的好处是可以并行地训练基学习器。Random Forest就用到了Bagging的思想。
我们将上面所有模型合并起来
# volting
from sklearn.ensemble import VotingClassifier
vote=VotingClassifier(estimators=[('lr',lr),('rfr',rfr2),('svm',svc),('xgb',xgb)],voting='soft')
vote.fit(x,y)
survived_predict=vote.predict(data_test.drop('PassengerId',axis=1))
result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':survived_predict})
result.to_csv("VotingClassifier_predictions.csv", index=False)
得到最终得分:0.78468。看,还是有点用的。

总结
可以看出我们的模型还有很大的改进空间,还有很多可以挖掘的空间,比如我们这个特征处理还是挺粗糙的,丢弃特征也过于随意;超参数的选择上也有很大改进空间,我们可以使用网格搜索寻找最佳的参数。
后记
答主后来又试着用神经网络来预测结果
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,pd.get_dummies(y), train_size=0.25)# 切割数据集
import keras
from keras.models import Sequential
from keras.layers import Dense
model = Sequential() # 建立一个模型
# 搭建网络
'''@param
Dense: Fully connect layer
input_dim: 输入层
units: 神经元
activation: 激活函数
'''
model.add(Dense(input_dim=10, units=200, activation='relu')) # 建立一个神经网络
# 再加一个隐含层
model.add(Dense(units=200, activation='relu'))
# 输出层
model.add(Dense(units=2, activation='softmax')) # 输出向量长度为10,激活函数为softmax
# loss function
model.compile(loss='categorical_crossentropy', # 损失函数:交叉熵
optimizer='adam', # 优化器(都是梯度下降)
metrics=['accuracy'] # 指标
)
# batch_size: 将训练集随机分为分为几个batch,每次计算随机的一个
# 所有batch都计算一次,一个epoch结束
model.fit(x_train, y_train, batch_size=20, epochs=20)
# case1: 测试集正确率
score = model.evaluate(x_test, y_test)
print('Total loss on Test Set:', score[0])
print('Accuracy of Testing Set:', score[1])
# case 2:模型预测
result = model.predict(data_test.drop('PassengerId',axis=1))
for n,i in enumerate(result):
result[n]=i.argmax()
result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':survived_predict})
result.to_csv("neuralnetwork_predictions.csv", index=False)
但最终结果还是0.78468,不管怎么改神经元数量、网络结构、激活函数都是这个准确率,感觉是是这组特征所能预测的极限了=。=这也侧面反映良好的特征处理是有多重要,特征处理不行,再调参,尝试再多的模型也无法提高正确率。