字符串截取
substr 函数:截取字符串
语法:substr(string, start, [length])
解释:
- String:源字符串
- start:开始位置,从0或1开始查找,如果start是负数,则从string字符串末尾开始算起
- length:可选项,表示字符串的长度
--截取所有字符串,返回'Hello ghostwolf1'
SELECT SUBSTR('Hello ghostwolf1', 0) NAME FROM DUAL;
--截取所有字符串,返回'Hello ghostwolf1'
SELECT SUBSTR('Hello ghostwolf1', 1) NAME FROM DUAL;
--从第7个字符串开始截取,返回‘ghostwolf1’
SELECT SUBSTR('Hello ghostwolf1', 7) NAME FROM DUAL;
--从倒数第10个字符开始,截取到末尾,返回‘ghostwolf1’
SELECT SUBSTR('Hello ghostwolf1', -10) NAME FROM DUAL;
--从第7个字符开始,截取17个字符。返回'ghostwolf1'
SELECT SUBSTR('Hello ghostwolf1', 7, 17) NAME FROM DUAL;
--从倒数第4个字符开始,截取3个字符,返回‘ghostwolf1’
SELECT SUBSTR('Hello ghostwolf1', -10, 10) NAME FROM DUAL;
instr 函数:查找字符串位置
语法:instr(String, subString, position, ocurrence)
解释:
- String:源字符串
- subString:要查找的子字符串
- position:开始的位置,默认从1开始。如果为负数,则从右向左检索
- ocurrence:可选项,表示子字符串第几次出现在源字符串当中,默认第1次,负数则报错。
--表示从源字符串'city_company_staff'中第1个字符开始查找子字符串'_'第1次出现的位置,返回5
SELECT INSTR('ABCD_EFGHIJK_LMNOP', '_') NAME FROM dual ;
--表示从源字符串'city_company_staff'中第5个字符开始查找子字符串'_'第1次出现的位置,返回5
SELECT INSTR('ABCD_EFGHIJK_LMNOP', '_', 5) NAME FROM dual;
--表示从源字符串'city_company_staff'中第5个字符开始查找子字符串'_'第1次出现的位置,返回5
SELECT INSTR('ABCD_EFGHIJK_LMNOP', '_', 5, 1) NAME FROM dual;
--表示从源字符串'city_company_staff'中第3个字符开始查找子字符串'_'第2次出现的位置,返回13
SELECT INSTR('ABCD_EFGHIJK_LMNOP', '_', 3, 2) NAME FROM dual ;
--start参数为-1,从右向左检索,查找'_'字符串在源字符串中第1次出现的位置,返回13
SELECT INSTR('ABCD_EFGHIJK_LMNOP', '_', -1, 1) NAME FROM dual ;
--start参数为-6,从右向左检索,查找'_'字符串在源字符串中第2次出现的位置,返回5
SELECT INSTR('ABCD_EFGHIJK_LMNOP', '_', -6, 2) NAME FROM dual ;
字符串拼接
“||” 拼接
这个相当于java里面的 “+” 号
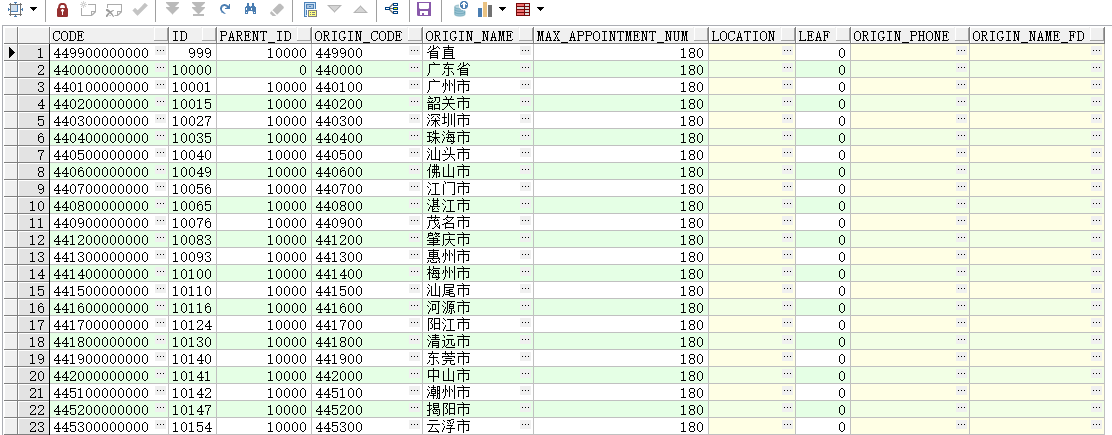
SELECT origin_code||'000000' CODE FROM t_origin t WHERE t.leaf='0' AND t.origin_code LIKE '44%00';
输出结果:
concat() 函数
采用CONCAT进行连接,CONCAT()只允许两个参数;换言之,一次只能将两个字串串连起来(如果需要拼接多个字符串,可以进行嵌套)
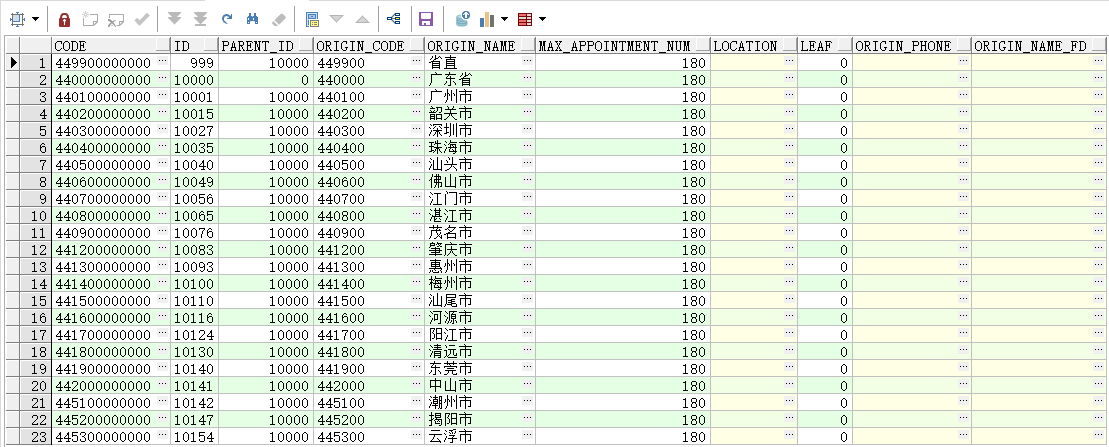
SELECT CONCAT(origin_code,'000000') CODE,t.* FROM t_origin t WHERE t.leaf='0' AND t.origin_code LIKE '44%00';
输出结果:
字符串替换
replace(char, str1, str2):把 char 中 str1 字符串替换为 str2 字符串
-- 将‘123456’中的‘456’替换成‘123’, 返回‘123123’
select replace('123456','456','123') name from dual;
replace(char, str1):把char 中的 str1 字符串移除
-- 将‘123456’中的‘456’替换掉。返回‘123’
select replace('123456','456') name from dual;
regexp_replace(cstr_sourcear, pattern_str, rep_str):支持正则表达式,用法类似于 replace,但功能更强大
-- 将‘12345654321’中的‘2’替换成‘*’,返回‘1*34566543*1’
select regexp_replace('123456654321','2','*') name from dual;
--将‘12345654321’中的‘[26]’替换成‘*’,返回‘1*345**543*1’
select regexp_replace('123456654321','[26]','*') name from dual;
regexp_replace(str_source, pattern_str):把 str_source中的 pattern_str 字符串剔除
--将‘12345654321’中的‘[26]’替换掉,返回‘13455431’
select regexp_replace('123456654321','[26]') name from dual;
translate(str_source, char1, char2):以字符为单位,把 str_source 中的 chr1 字符对应替换为 chr2。如果 chr1 比chr2 长,那么在 chr1 中而不在 chr2 中的字符将被剔除,因为没有对应的替换字符。需注意 chr2 不能为 null 或'',否则返回值也为空
--用字符'A'、'B'、'C'对应替换'a','b','c'字符;
select translate('abcc123a','abc','ABC') name from dual;
--'abc'长度为 3,'AB'长度为 2,字符'c'没有对应的字符来替换,因此被剔除掉;
select translate('abcc123a','abc','AB') name from dual;
--剔除掉字符'a'、'b'、'c',translate 有 # 的特殊用法,以 # 开头的表示所有字符。
select translate('abcc123a','#abc','#') name from dual;
--先把数字筛选出来,然后用筛选出来的字符串取筛选原来的字符串,结果‘234’
select translate('阿2萨德桑的3股份的4观点','#'||translate('阿2萨德桑的3股份的4观点', '#0123456789', '#'),'#') as col from dual;